






完整代码以及相关数据集在 FchZero/Digita_Image_Processing_Experiment (github.com)
Pytorch(TensorFlow)环境的搭建可见我这篇文章。
(3条消息) Anaconda + CUDA + cuDNN + Pytorch(TensorFlow)环境搭建_FchZero的博客-CSDN博客
一、Unet模型
Unet的相关知识以下仅作简要介绍,介绍来源于[1]陈燕宁. 高分辨率遥感图像道路提取深度学习模型研究与应用[D].中国地质大学(北京),2021.DOI:10.27493/d.cnki.gzdzy.2021.000449.,想要深入了解的可以自己再去找相关资料。
在图像的语义分割领域,传统的CNN网络最后连接的是若干个全连接层,在图像分类以及目标识别领域较为有效,但是在物体特征提取方面表现较为粗糙,因为全连接层中充斥着大量的节点信息,每层节点之间都有不同的参数,这样就会忽略像素之间的空间信息,使得提取的边缘信息不够完整,很难实现图像像素级的语义分割,FCN网络将传统的CNN网络末尾的全连接层用卷积层替代,因此得名全卷积神经网络,该模型自提出以来,一直反响火热,其基本结构如下图所示,其基本思想就是将网络结构分为前后两个部分,前半部分同传统的卷积网络一样,采用卷积运算的方式来提取图像中的特征信息;后半部分则采用反池化和融合的方式来进行分割,由于整个网络模型没有使用全连接层,输入图像的尺寸也不再受限,原始图像的空间信息也得以保存,反卷积操作也使输出图像恢复原始尺寸,更好的进行像素级别的语义分割。
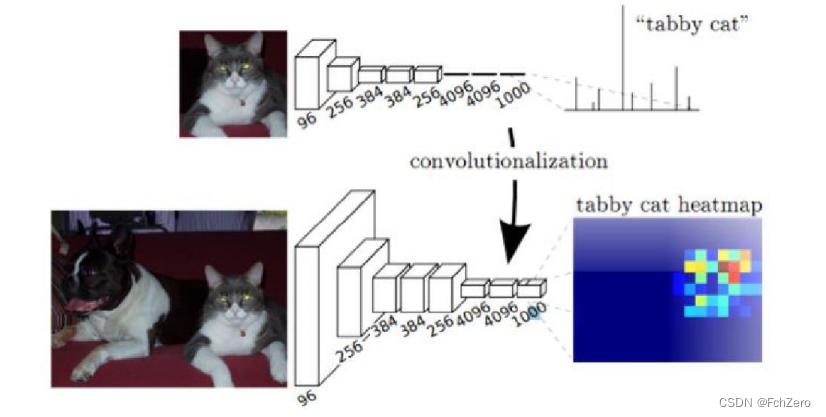
与传统的CNN网络相比,FCN网络具有以下三个优点:一是输入图像的大小不再受限,也不用要求测试图像和训练图像必须尺寸一致,使得模型的输入信息更加简单;二是网络的提取效率有所提高,解不仅决了重复存储的问题还使得计算量减少;三是图像的空间特征得以保存,使得提取出来的结果精度更高。
虽然FCN网络的出现,已经解决了传统神经网络分类精度低下的问题,实现了提取结果从像素块级到像素级分类的跨越,但是随着科技水平的发展和硬件水平的提高,FCN网络的提取精度已不能满足人们的需求,缺陷也逐渐明显,一是提取结果仍然不够精准,最终分割结果图中边缘细节信息处理的不够清晰明了,上采样的结果整体还是较为粗糙;二是对没有充分考虑到像素和像素之间的联系,针对单个像素逐一分类,缺乏空间一致性,特别是在道路连通性上有待提高。虽然FCN网络还是不够完美,但是从CNN到FCN的飞跃,打开了学者们的思路,为图像的语义化分割领域开创了一片新的天地,也为后续各种改进模型的出现奠定了基础。Unet模型也是在FCN网络的基础上进行改进的,自2015年被提出,一直备受关注,因网络模型酷似大写英文字母U故得名Unet模型,也叫编码器-解码器结构,如图2-6所示,模型的左边部分主要用于特征提取,右边则是上采样操作,除输出层外,Unet的每一层由三层卷积结构组成,层与层之间则采用池化或下采样方式来实现特征的提取和整合,并将网络同一层的编码及解码器部分通过捷径连接的方式融合低层特征与高层特征,这样会比FCN网络更能把握图像多层次信息。
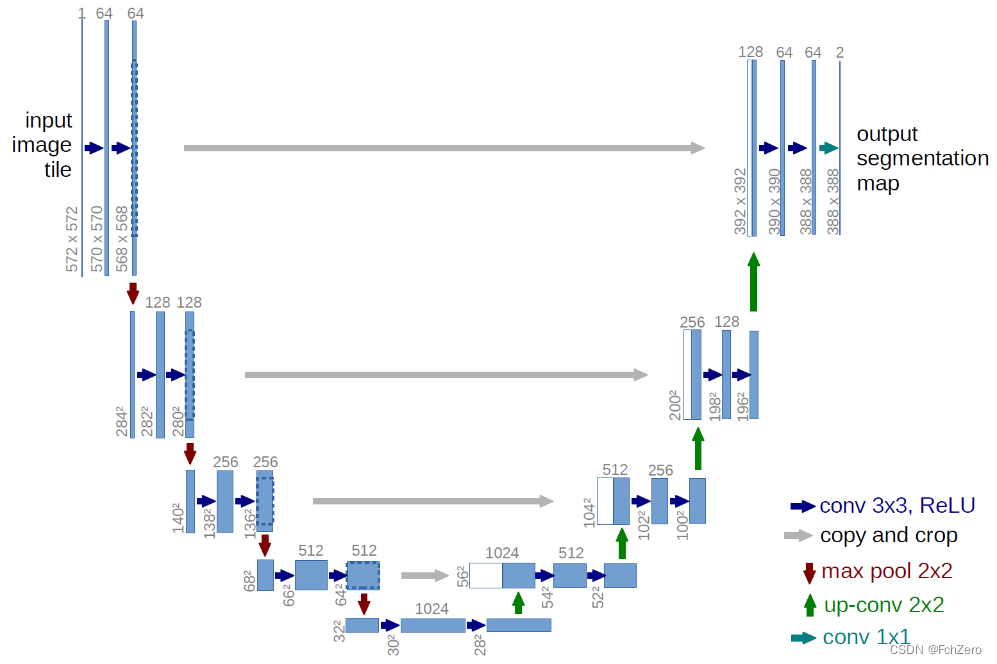
从Unet的网络结构图中不难发现该模型两个最主要的特点,一是它对称的型结构,左边Unet的编码器通过4次下采样过程来提取高级语义信息特征,右边Unet的解码器自然对应了4次上采样来进行分辨率恢复,使得被压缩的图像可以恢复至原始的大小;二是它独特的捷径连接结构,通过引入了跳层连接来缓解下采样过程带来的空间信息损失,将在下采样路径上所提取的局部图像特征在上采样的过程中与新的特征图进行整合,从而实现局部信息和全局信息的融合,低层特征和高层特征的结合,通过更全面的信息整合来提高像素点的预测准确性,最大限度的利用前面下采样过程中提取出的重要特征信息,为了使网络可以高效运行,网络结构也没有使用全连接层,不仅使得需要训练过程中的参数数量大幅减少,还保证了较好的空间特性,比全卷积神经网络更能把握图像多层次信息。该模型提出的初衷是为了解决医疗影像中的图像分割问题,但是由于该模型精炼而效果出色,从而成为经典,后续又有很多学者在此基础上进行了改进,影响意义深远。
二、算法流程及实现
2.1、实验平台
为了更好的满足实验需求,在计算机硬件方面,GPU选取了GeForce RTX 1060,能够基本保证语义分割网络的运行。在CPU的选择上,使用拥有6核心12线程的硬件规格以及2.2GHz的主频。在软件配置方面,选用了Windows11操作系统,为了使用GPU硬件,还配置了CUDA 11.3.1和CUDNN 8.2.1,所有网络结构均采用Python编程语言编写,模型采用PyTorch框架。
2.2、实验数据集
马萨诸塞数据集:由波士顿地区的151张航拍图像组成,每张图像的大小为1500×1500像素,面积为2.25平方公里。因此,整个数据集大约覆盖340平方公里。该数据集主要涵盖城市和郊区,各种规模的建筑物,包括个人房屋和车库,都包含在标签中。
2.3、实验流程
Unet的语义分割流程大致可以分为三个部分,数据预处理部分、模型训练部分以及测试验证部分.在模型训练阶段主要是通过模型损失函数的误差的反向传播算法来进一步的优化更新网络的参数,直到模型达到一个最优的状态;在测试阶段,主要利用测试数据集以及验证数据集来实时的验证模型的训练情况,并衡量该模型的性能和分类能力。
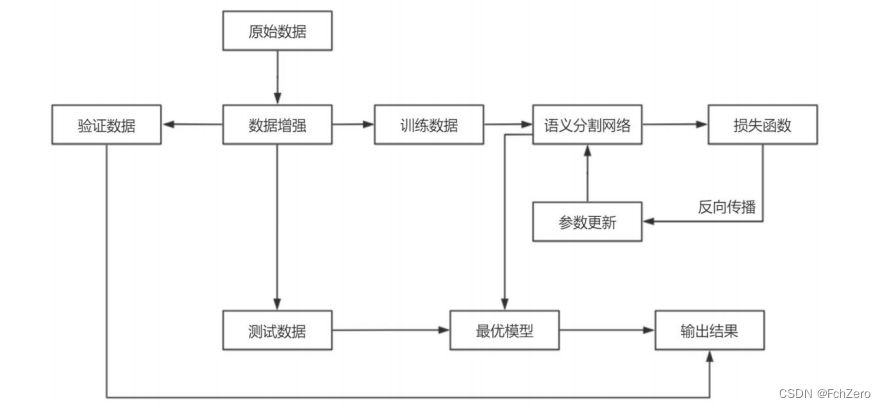
图3-1 实验流程图
在train.py文件中,修改dir_img为原图路径,dir_mask为标签路径。

在get_args()函数中,Epochs参数为训练的轮数,batch-size为批处理大小,leraning-rate为学习率。设定好相应的参数后即可开始训练。

训练好的模型文件会保存在checkpoints文件夹中。
训练好模型文件后,在predict.py文件中,修改get_args中的参数。Model修改为你的checkpoints中精度最高的模型文件。Input和output分别为输入图像和输出的预测。
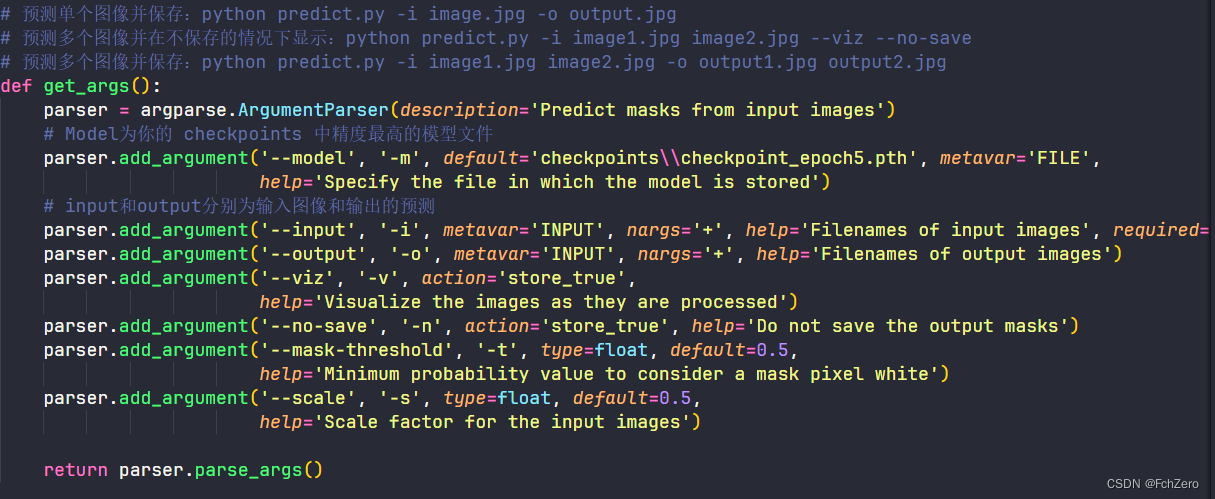
在终端进入predict.py所在的文件夹,在终端输入python predict.py -i image.jpg -o output.jpg即可进行单张预测。
三、结果


(a)原始图像2 (b)Unet结果图1


(a)原始图像2 (b)Unet结果图2


















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











