







均值向量和协方差矩阵的参数估计
一种是将参数作为非随机变量来处理,例如矩估计就是一种非随机参数的估计。另一种是随机参数的估计,即把这些参数看成是随机变量,例如贝叶斯参数估计。
均值和协方差矩阵的非随机参数的估计
均值和协方差矩阵的估计量定义设模式的类概率密度函数为p(x),则其均值向量定义为:

其中,x = (x1, x2, …, xn)T,m = (m1, m2, …, mn)T。
若以样本的平均值作为均值向量的近似值,则均值估计量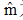
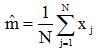
其中N为样本的数目。
协方差矩阵为:
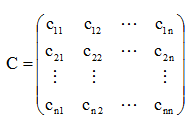
其每个元素clk定义为:
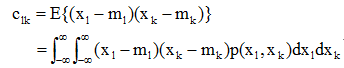
其中,xl、xk和ml、mk分别为x和m的第l和k个分量。
协方差矩阵写成向量形式为:
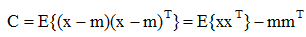
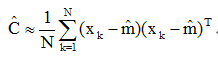
均值和协方差矩阵估计量的迭代运算形式
假设已经计算了N个样本的均值估计量,若再加上一个样本,其新的估计量为:
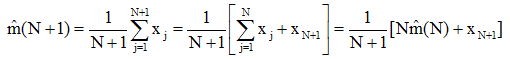
其中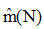
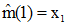
协方差矩阵估计量的迭代运算与上述相似。取表示N个样本时的估计量为:
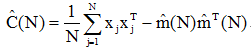
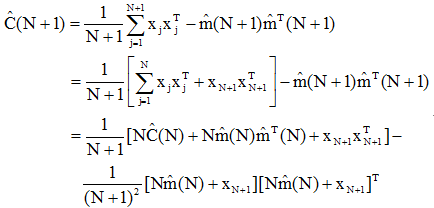
其中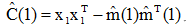
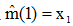
均值向量和协方差矩阵的贝叶斯学习
将概率密度函数的参数估计量看成是随机变量θ,它可以是纯量、向量或矩阵。按这些估计量统计特性的先验知识,可以先粗略地预选出它们的密度函数。通过训练模式样本集{xi},利用贝叶斯公式设计一个迭代运算过程求出参数的后验概率密度p(θ|xi)。当后验概率密度函数中的随机变量θ的确定性提高时,可获得较准确的估计量。一般概念
设{x1,x2,…, xN}为N个用于估计一未知参数θ的密度函数的样本,xi被一个接着一个逐次地给出。于是用贝叶斯定理,可以得到在给定了x1, x2,…,xN之后,θ的后验概率密度的迭代表示式为:
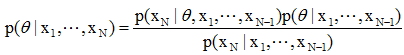
这里,需要先知道最初始的概率密度函数p(θ)。至于全概率p(xN | x1, …, xN-1)则可通过下式算出:
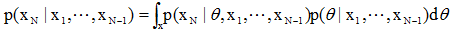
该值与未知量θ无关,可认为是一定值。
单变量正态密度函数的均值学习
设一个模式样本集,其类概率密度函数是单变量正态分布N(θ,σ2),均值θ待求,即:
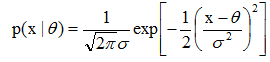
给出N个训练样本{x1, x2,…, xN},用贝叶斯学习计算其均值估计量。 设最初的先验概率密度p(θ)为
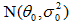 ,这里θ0是凭先验知识对未知量θ的“最好”推测, 表示上述推测的不确定性度量。这里可以假定p(θ)是正态的,因为均值的估计量是样本的线性函数,因样本x是正态分布的,因此p(θ)取为正态分布是合理的,这样计算起来可比较简单。
,这里θ0是凭先验知识对未知量θ的“最好”推测, 表示上述推测的不确定性度量。这里可以假定p(θ)是正态的,因为均值的估计量是样本的线性函数,因样本x是正态分布的,因此p(θ)取为正态分布是合理的,这样计算起来可比较简单。
初始条件已知,即p(θ)为
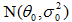 ,p( x1|θ)为N(θ,σ2),由贝叶斯公式p(θ| x1)=a p( x1|θ) p(θ),可得:
,p( x1|θ)为N(θ,σ2),由贝叶斯公式p(θ| x1)=a p( x1|θ) p(θ),可得:
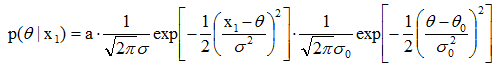
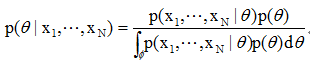
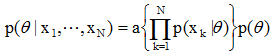
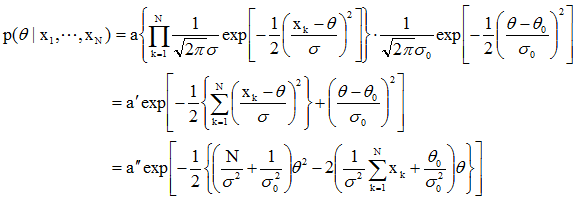
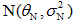 的形式,即:
的形式,即:
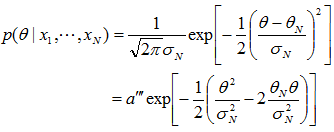
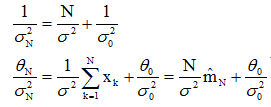
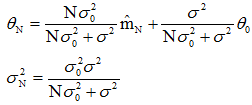
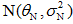 ,其中θN是经过N个样本观察之后对均值的最好估计,它是先验信息(即θ0,θ0的平方和σ2)与训练样本所给信息(即N和
,其中θN是经过N个样本观察之后对均值的最好估计,它是先验信息(即θ0,θ0的平方和σ2)与训练样本所给信息(即N和 )适当结合的结果,是用N个训练样本对均值的先验估计θ0的补充;
)适当结合的结果,是用N个训练样本对均值的先验估计θ0的补充; 是对这个估计的不确定性的度量,因其随N的增加而减小,因此当N趋向于无穷大时,
是对这个估计的不确定性的度量,因其随N的增加而减小,因此当N趋向于无穷大时,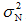 趋于零。由于θN是 和θ0的线性组合,两者的系数都非负且其和为1,因此只要
趋于零。由于θN是 和θ0的线性组合,两者的系数都非负且其和为1,因此只要 ,当N趋向于无穷大时,θN趋于样本均值的估计量
,当N趋向于无穷大时,θN趋于样本均值的估计量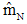 。
。
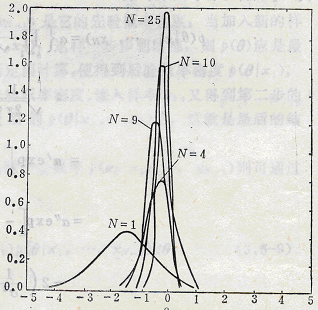
图中所示为一正态密度的均值学习过程,每增加一次对样本的预测,都可减小对θ估计的不确定性,所以p(θ| x1, …, xN)变得越来越峰形突起,且其均值与估计量
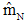 之间的偏差的绝对值亦越来越小。
之间的偏差的绝对值亦越来越小。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









