







第一次见到这样的说法是在《机器学习实战——基于scikit-learn和tensorflow》p159 决策树正则化超参,所以总结一下。
非参数模型(non-parametric model)和参数模型(parametric model)作为数理统计学中的概念,现在也常用于机器学习领域中。在统计学中,参数模型通常假设总体服从某个分布,这个分布可以由一些参数确定,如正态分布由均值和标准差确定,在此基础上构建的模型称为参数模型;非参数模型对于总体的分布不做任何假设或者说是数据分布假设自由,只知道其分布是存在的,所以就无法得到其分布的相关参数,只能通过非参数统计的方法进行推断。
所以说,参数模型和非参数模型中的“参数”并不是模型中的参数,而是数据分布的参数。问题中有没有参数,并不是参数模型和非参数模型的区别。其区别主要在于总体的分布形式是否已知。而为何强调“参数”与“非参数”,主要原因在于参数模型的分布可以有参数直接确定。
参数模型、非参数模型(以及半参数模型)的概念应该源自于统计学中。统计专业中有一门课程叫做《非参数统计》,研究的对象就是秩检验、核密度估计等。
对几篇博客的分析进行了总结和浓缩:
一、非参数模型并不是说模型中没有参数!而是参数很多或者说参数不确定。
这里的non-parametric类似单词priceless,并不是没有价值,而是价值非常高,无价,也就是参数是非常非常非常多的!(注意:所谓“多”的标准,就是参数数目大体和样本规模差不多)
而:可以通过有限个参数来确定一个模型,这样的方式就是“有参数模型”,也就是这里说的参数模型,如线性回归、Logistic回归(假定样本维度为N,则假定N个参数theta1,theta2...thetaN)。
二、参数模型 :对学到的函数方程有特定的形式,也就是明确指定了目标函数的形式 -- 比如线性回归模型,就是一次方程的形式,然后通过训练数据学习到具体的参数。
假设可以极大地简化学习过程,但是同样可以限制学习的内容。简化目标函数为已知形式的算法就称为参数机器学习算法。
通过固定大小的参数集(与训练样本数独立)概况数据的学习模型称为参数模型。不管你给与一个参数模型多少数据,对于其需要的参数数量都没有影响。— Artificial Intelligence: A Modern Approach,737页
所以参数机器学习模型包括两个部分:
1、选择合适的目标函数的形式。
2、通过训练数据学习目标函数的参数。
通常来说,目标函数的形式假设是:对于输入变量的线性联合,于是参数机器学习算法通常被称为“线性机器学习算法”。那么问题是,实际的未知的目标函数可能不是线性函数。它可能接近于直线而需要一些微小的调节。或者目标函数也可能完全和直线没有关联,那么我们做的假设是错误的,我们所做的近似就会导致差劲的预测结果。(容易欠拟合)
三、非参数机器学习算法:对于目标函数形式不作过多的假设的算法称为非参数机器学习算法。通过不做假设,算法可以自由的从训练数据中学习任意形式的函数。
当你拥有许多数据而先验知识很少时,非参数学习通常很有用,此时你不需要关注于参数的选取。— Artificial Intelligence: A Modern Approach,757页
非参数理论寻求在构造目标函数的过程中对训练数据作最好的拟合,同时维持一些泛化到未知数据的能力。同样的,它们可以拟合各种形式的函数。(所以说,非参数有目标函数,但是我们不知道目标函数的具体形式也不做出过多假设?)
对于理解非参数模型的一个好例子是k近邻算法,其目标是基于k个最相近的模式对新的数据做预测。这种理论对于目标函数的形式,除了相似模式的数目以外不作任何假设。
四、最后:
常见的参数机器学习模型有:
1、逻辑回归(logistic regression)
2、线性成分分析(linear regression)
3、感知机(perceptron)(假设分类超平面是wx+b=0)
参数机器学习算法有如下优点:
1、简洁:理论容易理解和解释结果。
2、快速:参数模型学习和训练的速度都很快。
3、数据更少:通常不需要大量的数据,在对数据的拟合不很好时表现也不错。
参数机器学习算法的局限性:
1、拘束:以指定的函数形式来指定学习方式。
2、有限的复杂度:通常只能应对简单的问题。
3、拟合度小:实际中通常无法和潜在的目标函数完全吻合,也就是容易出现欠拟合。
常见的非参数机器学习模型有:
1、决策树
2、朴素贝叶斯
3、支持向量机(SVM的例子中,SVM的参数α数目和样本数目相同,从定义看来,因为参数数目和样本规模相当,所以属于无参数模型。当然,SVM通过得到支撑向量的方式,只有若干样本的参数α不为0,从这个角度,SVM还属于“稀疏模型”,这又属于另外一码事了。)
4、神经网络
非参数机器学习算法的优势有:
1、可变性:可以拟合许多不同的函数形式。
2、模型强大:对于目标函数不做假设或者作出很小的假设。
3、表现良好:对于训练样本数据具有良好的拟合性。
非参数机器学习算法的局限性:
1、需要更多数据:对于拟合目标函数需要更多的训练数据。
2、速度慢:因为需要训练很多的参数,所以训练过程通常比较慢。
3、过拟合:有较高的风险发生过拟合,对于预测的效果解释性不高。
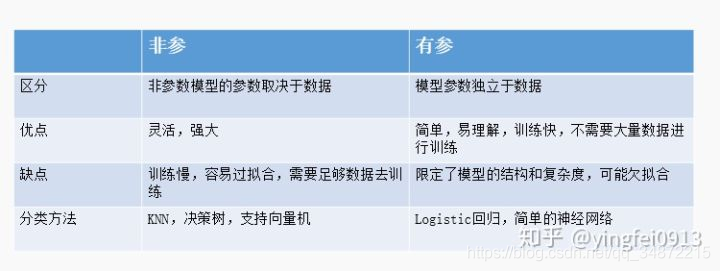
问题:非参数模型是不是没有目标函数?不是,比如决策树有目标函数,但没有具体形式,不像线性回归那样。
总结:
参数模型通常假设总体服从某个分布,这个分布可以由一些参数确定,如正态分布由均值和标准差确定,在此基础上构建的模型称为参数模型,包括逻辑回归,线性成分分析,感知机等。
非参数模型对于总体的分布不做任何假设或者说是数据分布假设自由,只知道其分布是存在的,所以就无法得到其分布的相关参数,只能通过非参数统计的方法进行推断。包括决策树,朴素贝叶斯,SVM,神经网络。
需要注意,感知机是参数模型,神经网络是非参数模型。
还有知乎的解答,但很遗憾不能转载:

参考资料:
(1)版权声明:本文为CSDN博主「qq_34872215」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/qq_34872215/article/details/100045336
(2)知乎解答 https://www.zhihu.com/question/22855599
(3)汇总不同解答的博客 https://blog.csdn.net/sinat_27652257/article/details/80543604
新手入门, 如果有不正确之处还请大佬指正。


















 5167
5167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









