









 提出LPN轻量级网络,结合Attention机制与Depthwise卷积,实现高效姿态检测。在COCO数据集上取得68.7 AP的成绩,参数量仅2.7M,1.0 GFLOPs,CPU环境下达17 FPS。
提出LPN轻量级网络,结合Attention机制与Depthwise卷积,实现高效姿态检测。在COCO数据集上取得68.7 AP的成绩,参数量仅2.7M,1.0 GFLOPs,CPU环境下达17 FPS。
论文地址:https://arxiv.org/abs/1911.10346
代码地址:https://github.com/zhang943/lpn-pytorch
论文总结
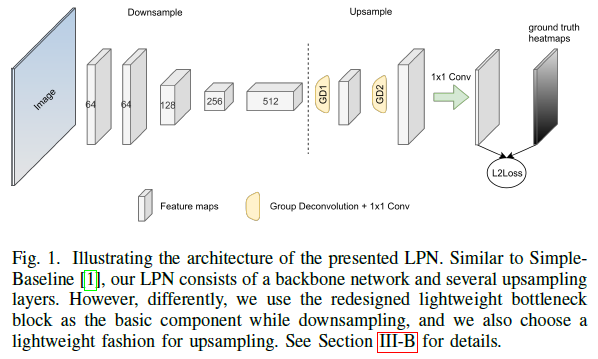
本文网络名叫LPN。本文的核心目的,其实也就是实现轻量级的姿态检测网络。其做法方式也相对比较传统和简单,实际上就是对backbone进行轻量级设计。网络架构如下图所示:在Downsample的部分,样式和ResNet-18是一样的,但实际上采用的是ResNet-50的结构(bottleneck block),只是将expansion设置为了1。在轻量级网络的设计之后,为了维持高分辨率,将stage4的下采样移去了,即512 channel 和256 channel 具有一样的feature map size。在上采样部分,由于少了一个下采样,所以只有两个deconv。为了减轻网络的“重量”,使用 group deconv。
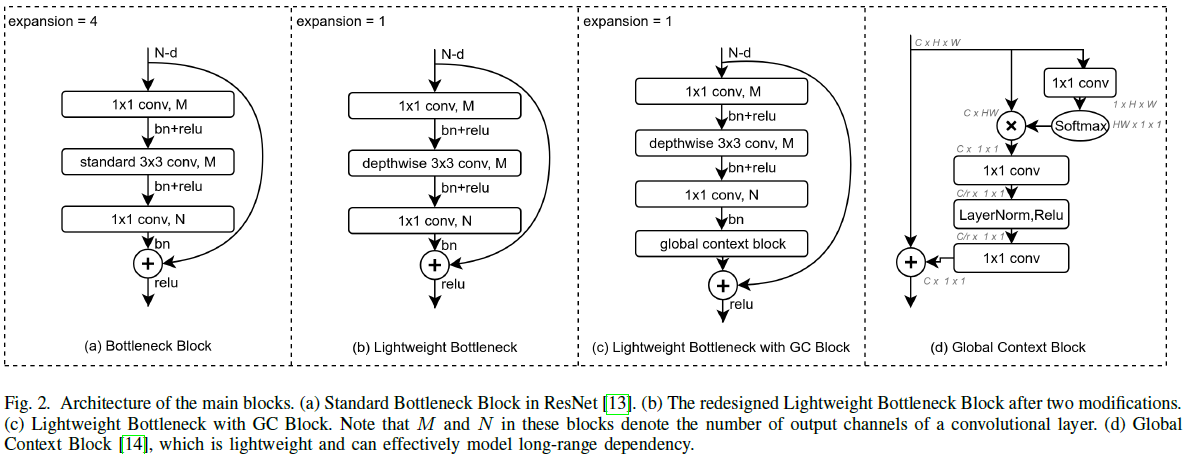
在网络的细节部分,如下图所示:本文的backbone,初步设计是将bottleneck中的 3 ∗ 3 3*3 3∗3卷积变成depthwise 3 ∗ 3 3*3 3∗3卷积。在轻量级网络的设计下,觉得网络的学习能力可能不够,故添加了attention机制,即下图(c)和(d)。采用的attention模块是GC block。
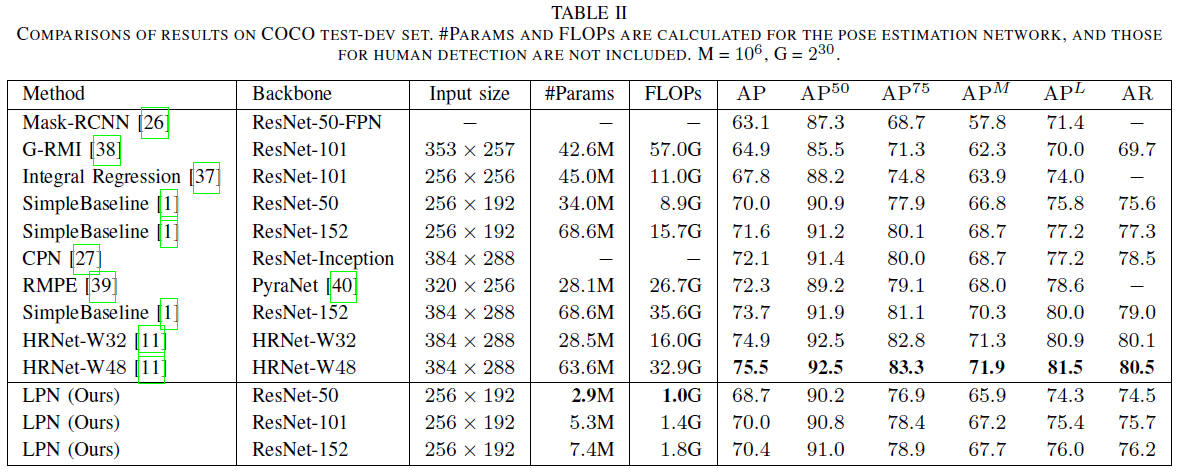
LPN-50,在COCO test-dev上能有 68.7 68.7 68.7的AP,但只有 2.7 M 2.7M 2.7M的参数量, 1.0 1.0 1.0 GFLOPs。在没有GPU的情况下,在Intel i7-8700K CPU上达到了 17 17 17 FPS的运行速度。
在heatmap得到坐标的后处理方面,作者对Soft-argmax(这是对Argmax做的一个改进)做了进一步改进,变成了 β \beta β-Soft-Argmax,能够有效减缓heatmap中大数量的0值对Softmax造成的影响。
论文介绍
本文的轻量级网络,采用的是attention + depthwise的结构,主体框架为ResNet50这样的结构。与此同时,由于一般采用的backbone都是在ImageNet有预训练的,而新的轻量级backbone没有预训练参数。所以,为了得到一个较好的性能,作者不打算在ImageNet预训练backbone(太耗时),而是选择使用周期性学习率方案去学习网络。更新学习率的方案如下图所示:第一个阶段,正常按照epoch数衰减lr;第二个阶段,选择最好的一个模型,在重新选择在某个epoch上(reset)进行重新学习;重复第二个阶段。
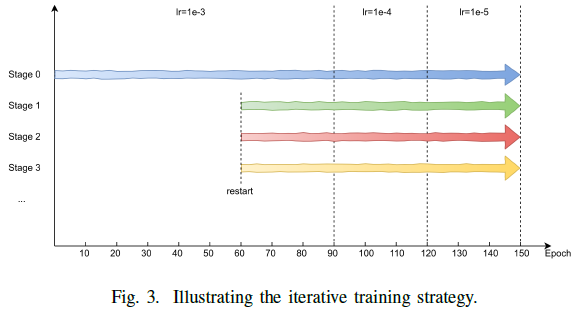
作者说,通过这样周期学习的模型性能,比直接在ImageNet预训练backbone的模型性能好。
轻量级backbone设计
如下图所示,bottleneck block的参数量,为 1 ∗ 1 ∗ N ∗ M + 3 ∗ 3 ∗ M ∗ M + 1 ∗ 1 ∗ M ∗ N 1*1*N*M+3*3*M*M+1*1*M*N 1∗1∗N∗M+3∗3∗M∗M+1∗1∗M∗N一般来说,如果不考虑downsample的那个block,输入channel和输出channel 数量是一样的,而且 e x p a n s i o n = 4 expansion=4 expansion=4,即 N = 4 ∗ M N=4*M N=4∗M。那么上述公式就变成: 17 ∗ M ∗ M 17*M*M 17∗M∗M作者所做的第一个轻量级操作,是将bottleneck block的 3 ∗ 3 3*3 3∗3卷积变成depthwise 3 ∗ 3 3*3 3∗3卷积。作者所做的第二个轻量级操作,是将 e x p a n s i o n expansion expansion 设置为了 1 1 1。这样减少了channel数,从原来的[256,512,1024,2048]变成了[64,128,256,512]。因此 depthwise-bottleneck的参数量变成了 2 ∗ ( 1 ∗ 1 ∗ M ∗ M ) + 3 ∗ 3 ∗ M 2*(1*1*M*M)+3*3*M 2∗(1∗1∗M∗M)+3∗3∗M。减少的参数量为 2 ∗ M ∗ M + 3 ∗ 3 ∗ M 17 ∗ M ∗ M ≈ 2 17 \frac{2*M*M+3*3*M}{17*M*M} \approx \frac{2}{17} 17∗M∗M2∗M∗M+3∗3∗M≈172
轻量级poseNet设计
SimpleBaseline使用了3个deconv,而本文的LPN替换deconv为group deconv和 1 1 1个 1 ∗ 1 1*1 1∗1卷积。group的大小为 c h a n n e l i n channel_{in} channelin和 c h a n n e l o u t channel_{out} channelout的最大公约数。
直观上来说,上采样前如果能保持高分辨率特征是有益的,但大多数网络考虑到了计算负担的问题都讲feature map下采样到了低分辨率(比如 6 ∗ 8 , 4 ∗ 4 6*8,4*4 6∗8,4∗4)。为了在轻量级网络上保持高分辨率,作者选择了移除layer4的下采样和一个group deconv(backbone 中更高channel的运行还是有的,只是feature map size没有减少)。即后两个stage中的feature map是一样的。
后处理
在后处理上,作者认为argmax的方式会有精度损失,又觉得soft-argmax会导致关键点预测的置信度太低了(因为ground truth都是在0-1之间的, e 0 = 1 , e 1 = e e^0=1,e^1=e e0=1,e1=e,而heatmap中0的部分太多了,会导致softmax后关键点置信度低)。softmax的公式为 S k ( x , y ) = e H k ( x , y ) ∑ x ∑ y e H k ( x , y ) S_k(x,y)=\frac{e^{H_k(x,y)}}{\sum_x\sum_ye^{H_k(x,y)}} Sk(x,y)=∑x∑yeHk(x,y)eHk(x,y)经过作者的改进,得到了一个 β \beta β-Soft-argmax方案,即如下公式:能有效减缓heatmap中0的数量带来的影响。 S k ( x , y ) = e β H k ( x , y ) ∑ x ∑ y e β H k ( x , y ) S_k(x,y)=\frac{e^{\beta H_k(x,y)}}{\sum_x\sum_ye^{\beta H_k(x,y)}} Sk(x,y)=∑x∑yeβHk(x,y)eβHk(x,y)
论文实验
训练策略
在COCO上训练。LPN所有参数都是标准差为0.001的零均值高斯随机初始化。使用Adam优化器,batch size为32,初始学习率为1e-3,在第90个120个epoch上衰减10倍。在后续的retrain阶段,使用上一个阶段的最好的模型作为初始化,然后设置学习率为1e-3,在第60个epoch开始。每个阶段训练150个epoch,一共有7个阶段。
将人体检测框固定到一个比率(比如 height : width = 4 : 3),然后再依据box从图片中crop。crop下来的bbox通过resize成固定大小(256*192),作为网络的输入。数据增强操作包括:随机旋转( ± \pm ± 40°),随机旋转( ± \pm ± 30%),水平翻转。训练都在1080Ti GPU上进行。
测试
采用两阶段top-down下的范式,使用人体检测器检测人体实例,然后检测关键单。使用的人体检测器和SimpleBaseline一样。测试时,使用flip image预测heatmap,与origin heatmap进行平均操作。在推理的时候, β \beta β-Soft-argmax中的 β \beta β设为160。
在validation set的结果,如下图所示:本文有三个版本的lightweight pose network(LPN-50,LPN-101,LPN-152),就和SimpleBaseline一样。对比Hourglass和CPN,LPN-50都有更好的表现。
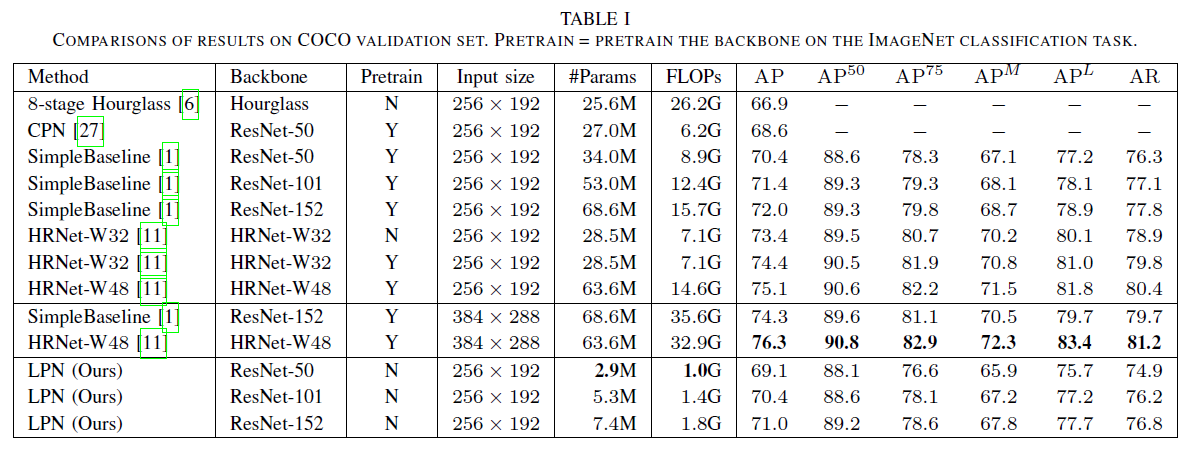
在test-dev上的结果,如下图所示:本文并没有像其他方法一样增加更高分辨率作为输入。
消融学习
在COCO val2017上进行消融学习,所有的输入分辨率都为 256 ∗ 192 256*192 256∗192。
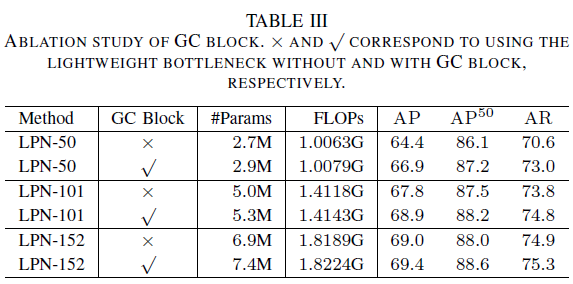
GC block。使用没有GC block的lightweight bottleneck和有GC block的进行对比,学习策略只有第一阶段,没有后续的重复训练。后处理也没有使用 β \beta β-Soft-Argmax。表现如下图所示:可以看出,GC block在小网络的提升比在大网络上要明显,对于LPN-50是2.5个点,对于LPN-101是1.1个点,对于LPN-152是0.4个点。
迭代训练策略。如表Ⅰ所示,对于HRNet-W32来说,使用ImageNet训练的pre-trained参数能提升1个点。从下表中可以看出,本文的迭代训练策略,能带来的提升比使用预训练模型要高。比如,对于LPN-50来说提升了2.02个点;对于LPN-101来说,提升了1.4个点;对于LPN-152来说,提升了1.5个点。这不小的提升,也意味着轻量级网络很难训练,可能是因为它们更容易陷入局部极小值。
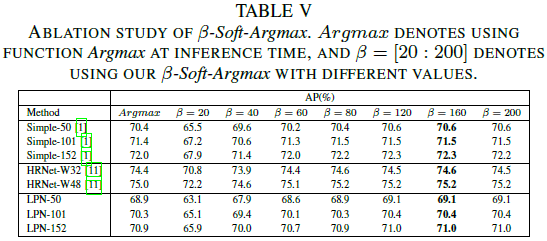
β \beta β-Soft-Argmax。在不同网络上,进行了不同 β \beta β值的测试,表现如下图所示。可以看到,当 β \beta β值较小的时候,它是没有帮助的,甚至是有害的,但随着 β \beta β值的提升能获得明显的受益。当 β \beta β值大于 120 120 120时,这提升趋近于饱和。最终选择了 β \beta β值为 160 160 160。最大的提升是在Simple-150上,带来了 0.3 0.3 0.3的提升,其他的在 0.1 0.1 0.1到 0.3 0.3 0.3之间。
推理速度
FLOPs,浮点运算的数量(float-point operations),是衡量网络计算复杂度使广泛使用的度量标准。但这不是一个严格的指标,也不是我们真正关心的,我们关心的是运行速度等。在非GPU平台下,Inter Core i7-8700K CPU(3.70GHz * 12)。
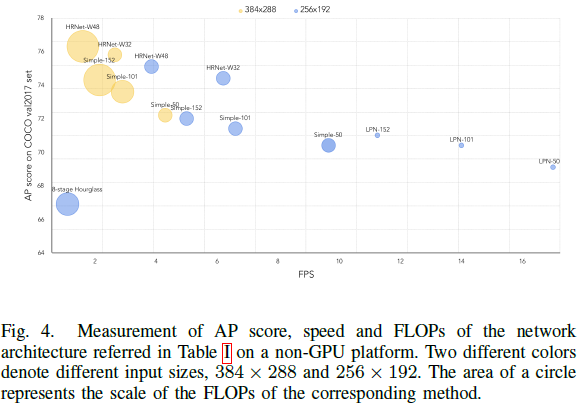
下图是AP值和运行速度的图:可以发现,即时有更低FLOPs的模型,其运行速度也不一定块。比如Simple-152(15.7 GFLOPs)的FLOPs就比HRNet-W48(14.6 GFLOPs)要更多,但Simple-152也是更快一些的,因为HRNet-W48有平行计算。

















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









