







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
系统功能:基于音频视觉角色识别技术,生成详细且连贯的长视频描述。
技术优势:在MovieQA任务中准确率比最强基线Gemini-1.5-pro高9.5%。
应用场景:适用于电影制作、视频内容分析、辅助视障人士等多个领域。
正文(附运行示例)
StoryTeller 是什么
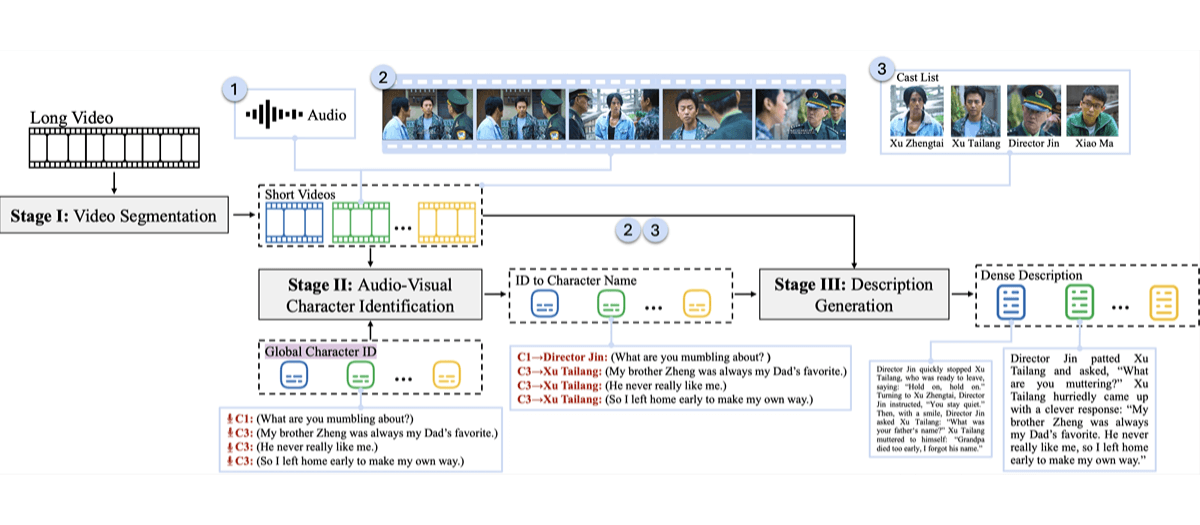
StoryTeller是由字节跳动、上海交通大学和北京大学共同推出的系统,旨在基于音频视觉角色识别技术改善长视频描述的质量和一致性。该系统结合低级视觉概念和高级剧情信息,生成详细且连贯的视频描述。
StoryTeller由视频分割、音频视觉角色识别和描述生成三个主要模块组成。这些模块能够有效处理数分钟长的视频,并在MovieQA任务中展现出比现有模型更高的准确率,比最强基线Gemini-1.5-pro高9.5%的准确率。
StoryTeller 的主要功能
- 视频分割:将长视频切割成多个短片段,保持每个片段的独立性和完整性。
- 音频视觉角色识别:结合音频和视觉信息,识别视频中对话对应的角色。
- 描述生成:为每个视频片段生成详细的描述,整合成整个长视频的连贯叙述。
- 数据集构建:创建并使用MovieStory101数据集,提供长视频描述的训练和测试数据。
- 自动评估:基于MovieQA,用GPT-4自动评估视频描述的准确性和质量。
- 模型训练与微调:训练多模态大型语言模型,提高角色识别和视频描述的准确性。
- 全局解码:确保同一角色在不同视频片段中保持一致的识别结果。
StoryTeller 的技术原理
- 多模态融合:整合视觉(视频帧)、音频(对话)和文本(字幕和描述)信息,全面理解视频内容。
- 音频分离和角色ID分配:用音频嵌入模型对每个对话进行嵌入,基于聚类算法分配全局ID,将相似的音频嵌入分配相同的ID,表示同一角色。
- 音频视觉角色识别模型:用大型语言模型(如Tarsier-7B)结合OpenAI的Whisper-large-v2音频编码器,将每个音频ID映射到特定的角色。
- 全局解码算法:在推理时,确保不同片段中相同角色的全局ID映射到一致的角色名称,提高角色识别的准确性。
- 视频描述生成:用识别结果作为输入,基于大型语言模型生成每个片段的详细描述,并整合成完整的视频描述。
如何运行 StoryTeller
1. 生成视频帧和音频文件
python script/preprocess/preprocess.py
- 输入视频路径:data/video
- 输出帧路径:data/frame
- 输出音频路径:data/audio
2. 将3分钟视频片段分割成小段
pip install scenedetect
scenedetect -i movie.mp4 -o data/raw_data/scene_detect -q detect-adaptive -t 2.0 list-scenes
python script/scene_split/scene_split.py
python script/scene_split/update_scene_split.py
3. 生成每个角色的参考照片
对于MovieQA数据集,已提供每个片段的演员列表。对于其他电影,可以从IMDb获取演员列表并使用面部识别算法。
4. 进行全局音频分离
python script/global_diarization/eval_embedding.py --input_file data/global_diarization/embeddings.jsonl
python script/global_diarization/update_diarization.py --input_file data/global_diarization/embeddings.jsonl --output_file data/global_diarization/diarization_id.jsonl
5. 音频视觉角色识别
python script/audio_visual_diarization/gen_infer.py
python tasks/inference_quick_start.py --model_name_or_path checkpoints/Whisper-large-v2-Tarsier-7B-character-identification --input_path data/audio_visual_diarization/data.jsonl --output_path data/audio_visual_diarization/0.jsonl
python script/audio_visual_diarization/alignment.py
python tasks/inference_quick_start.py --model_name_or_path checkpoints/Whisper-large-v2-Tarsier-7B-character-identification --input_path data/audio_visual_diarization/align_data/data.jsonl --output_path data/audio_visual_diarization/correct/0.jsonl
6. 长视频描述生成
python script/long_video_description/gen_infer.py
python tasks/inference_quick_start.py --model_name_or_path checkpoints/Tarsier-7B-description-generation --input_path data/long_video_description/data.jsonl --output_path data/long_video_description/0.jsonl
python dense_description.py
python script/long_video_description/eval_qa_accuracy.py --pred_caption_path result/tarsier/dense_caption_name.json --out_path result/tarsier/qa_name.jsonl
资源
- GitHub 仓库:https://github.com/hyc2026/StoryTeller
- arXiv 技术论文:https://arxiv.org/pdf/2411.07076
- Hugging Face 数据集:https://huggingface.co/datasets/hyc2026/MovieStory101
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









