






相关文档:
论文链接: https://arxiv.org/abs/2005.11401
课程链接: Tutorial/huixiangdou at camp2 · InternLM/Tutorial · GitHub
视频链接: 茴香豆:搭建你的 RAG 智能助理_哔哩哔哩_bilibili
RAG是一种在LLM中广泛使用的支持库外挂。如下图,基于特定知识,我们维护了一个向量数据库,用户的提问会被转换为增强的提示词,然后传入LLM中。

谈到RAG,最重要的两个词是: retrieval 和 Generation,然后是indexing和query。
关于论文的创新点,作者提到:我们实现了模型参数(parametric-memory generation model)和non-parametric memory(就是RAG)的结合。
We endow pre-trained, parametric-memory generation models with a non-parametric memory through a general-purpose fine-tuning approach which we refer to as retrieval-augmented generation (RAG).
既然反复提到“non-parametric”(22次),虽然它确实是个很老的概念了,但是考虑到它在这种文章中反复提到的频率,作者是不是应该解释一下?
parametric memory指的是把知识存储在一个分布中,最简单的,比如,我们用高斯分布来表达一个数据时,这就是一种 parametric method,而Bert,GPT这类模型,都是把知识存储在权重中。
non-parametric 指的是retrieval-based memories,这种方法的好处是支持不是存放在权重中,而是通过query的机制从知识库去获取。令人困惑的是,RAG的构造也包括了Bert等编码器结构,难道这些不算是参数化吗?
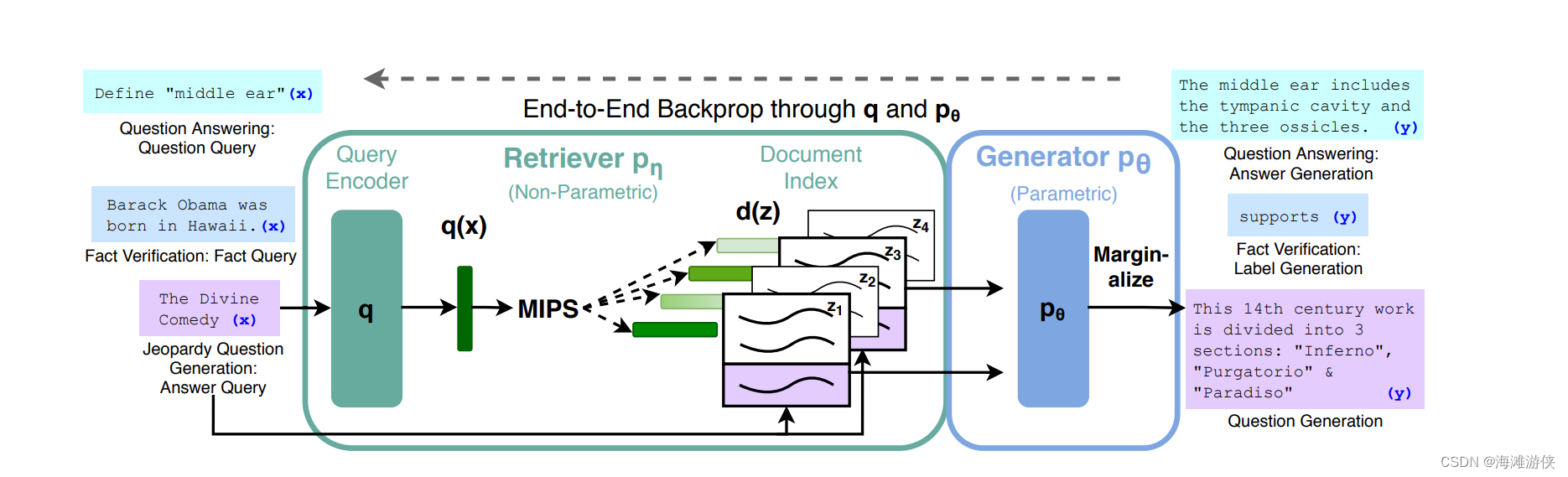
从图可知, RAG包含retriever 和 generator。我们把retrieve的文档作为latent ariable。我们提出了两种方法去学习生成文字的分布。分别为RAG-Sequence(基于相同文件预测), 和RAG-Token,基于不同文档预测。
其中,Retrever(DPR)是基于编码器的结构。比如Bert。而Generator基于Encoder-decoder的结构,比如Bart。
retriever可以用于提取文档,建立index信息,然后把index信息称为non-parametric memory信息。
而关于Generator,它是基于encoder-decoder的结构,


总结:
我不喜欢RAG的思路,号称是non-parametric的方法,实际上也引入了编码器解码器的结构去解决额外难题,另外,RAG的显存占用多大呢?















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









