






RAG 技术概述
定义
RAG(Retrieval Augmented Generation)是一种结合了检索(Retrieval)和生成(Generation)的技术,旨在通过利用外部知识库来增强大型语言模型(LLMs)的性能。它通过检索与用户输入相关的信息片段,并结合这些信息来生成更准确、更丰富的回答。
解决LLMs在处理知识密集型任务时可能遇到的挑战,如,生成幻觉(hallucination)、过时知识、缺乏透明及可追溯的推理过程。提供更准确的回答、降低成本、实现外部记忆。
应用场景
问答系统、文本生成、信息检索、图片描述
RAG工作原理
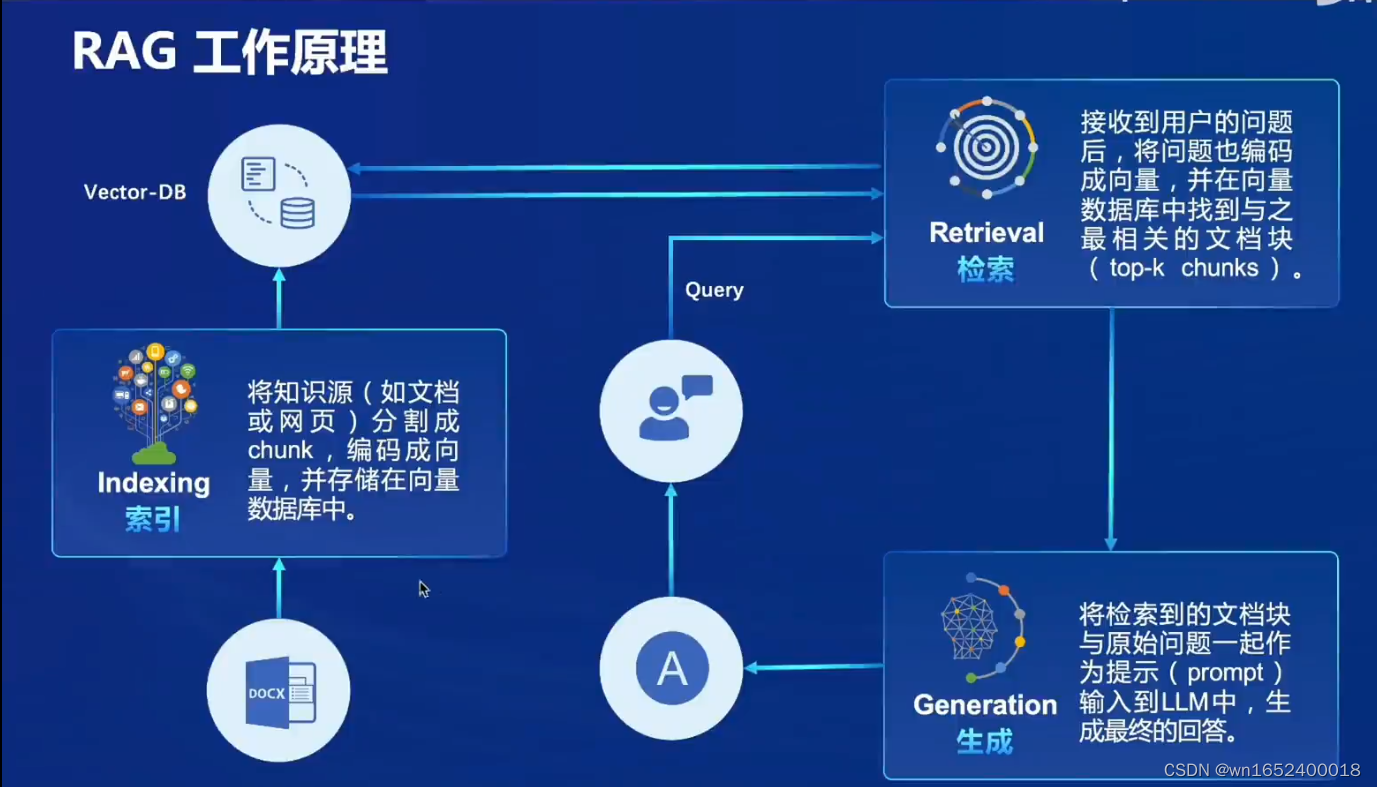 索引(index)、检索(retrieval)、生成(generation)是经典RAG的三个组成部分。索引负责将知识源(如文档或网页)分割成chunk,编码成向量,并存储在向量数据库中;检索负责在接收到用户的问题后,将问题也编码成向量,并在向量数据库中找到与之最相关的文档块(top-k chunks );生成部分负责将检索到的文档块与原始问题一起作为提示(prompt)输入到LLM中,生成最终的回答。
索引(index)、检索(retrieval)、生成(generation)是经典RAG的三个组成部分。索引负责将知识源(如文档或网页)分割成chunk,编码成向量,并存储在向量数据库中;检索负责在接收到用户的问题后,将问题也编码成向量,并在向量数据库中找到与之最相关的文档块(top-k chunks );生成部分负责将检索到的文档块与原始问题一起作为提示(prompt)输入到LLM中,生成最终的回答。
向量数据库(Vector-DB)也是RAG的一个重要的概念。在索引阶段它被用来存储数据,将文本及其他数据通过其他预训练的模型转换为固定长度的向量表示,这些向量能够捕捉文本的语义信息;在检索阶段,根据用户的查询向量,使用向量数据库快速找出最相关的向量的过程通常通过计算余弦相似度或其他相似性度量来完成,检索结果根据相似度得分进行排序最相关的文档将被用于后续的文本生成。
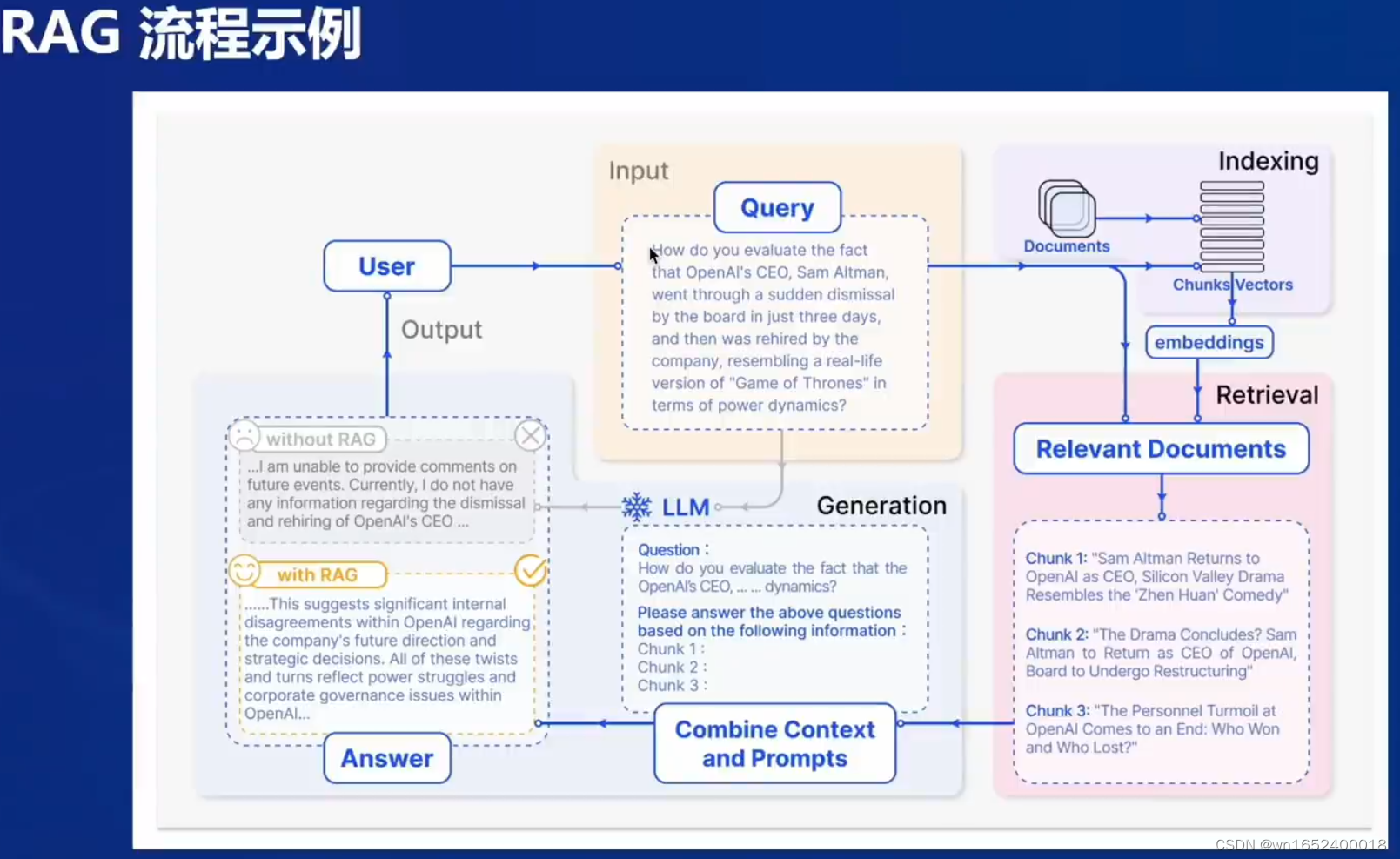 示例中用户询问一件三天前发生的事情,模型没有在该数据上训练过。怎么看待Sam Altman 被解雇又火速回归的事情。在没有RAG的情况下模型说不知道该事情。在RAG的加持下,检索模块检索到了关于该事件的信息,将该信息和用户的体温一并送给大模型后,大模型可以准确回答该问题。
示例中用户询问一件三天前发生的事情,模型没有在该数据上训练过。怎么看待Sam Altman 被解雇又火速回归的事情。在没有RAG的情况下模型说不知道该事情。在RAG的加持下,检索模块检索到了关于该事件的信息,将该信息和用户的体温一并送给大模型后,大模型可以准确回答该问题。
RAG的发展进程
RAG的概念最早是由Meta(Facebook)的Lewis等人在2020《Retrieval-Augmented Generation forKnowledge-Intensive NLp Tasks》中提出的。
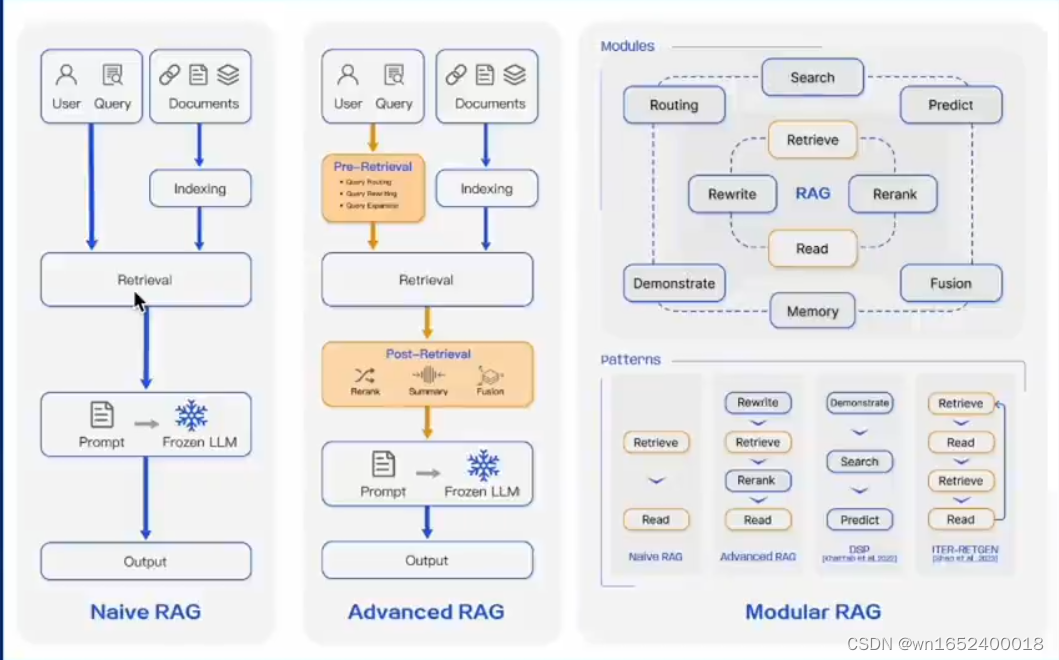 Naive RAG:就是前文中介绍的朴素的RAG,一般被用在问答系统、信息检索相关应用。
Naive RAG:就是前文中介绍的朴素的RAG,一般被用在问答系统、信息检索相关应用。
Advanced RAG:在三个基础模块之外,在检索前后都进行了增强。在检索之前对用户的提问进行了路由、扩展、重写的处理,对于检索到的信息进行重排序、总结、融合等处理,使得对信息收集和处理的效率更高。是的RAG可以在摘要生成、内容推荐的场景下应用。
Modular RAG:将RAG的基础部分和后续优化技术和功能模块化,可以根据实际业务定制,完成如多模态任务、对话系统等更高级的应用。
RAG常见优化方法
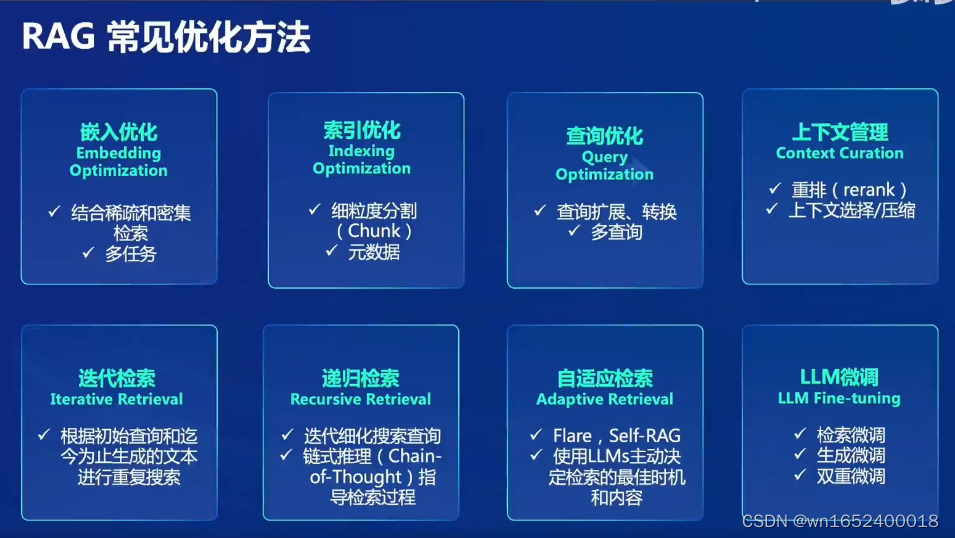
- 嵌入优化,结合稀疏编码器、密集编码器以及多任务的方式来增强嵌入的性能。
- 索引优化,增强数据粒度、优化索引结构、添加元数据、对齐优化和混合检索等策略来提成检索性能。
- 查询优化,通过查询扩展和转换来使用户的原始问题更清晰,跟适合检索任务。例如采用多查询方法,通过大模型生成的提示工程来扩展查询。
- 上下文管理,通过重排,上下文管理、压缩来减少检索信息的冗余,提升大模型的效率。例如用小的语言模型来过滤不重要的标记,或者训练信息提取器、信息压缩器。
- 迭代检索,在RAG过程中,根据检索结果多次迭代检索知识,为大模型提供全面的基础知识。
- 递归检索,通过迭代细化搜索查询来改进搜索结果的深度和相关性,使用到链式推理(CoT)指导检索过程,并根据检索结果细化推理过程。
- 自适应检索,指食用Flare、Self-RAG等让大模型自主决定检索的最佳时机和内容。
- 大模型微调,包多检索微调、生成微调、双重微调。根据场景、数据进行有针对性的微调。
RAG vs. 微调
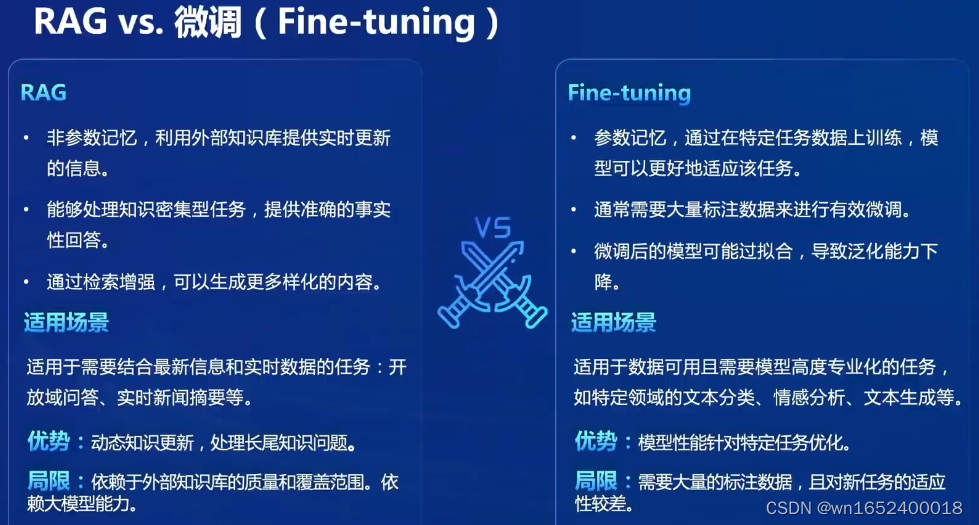
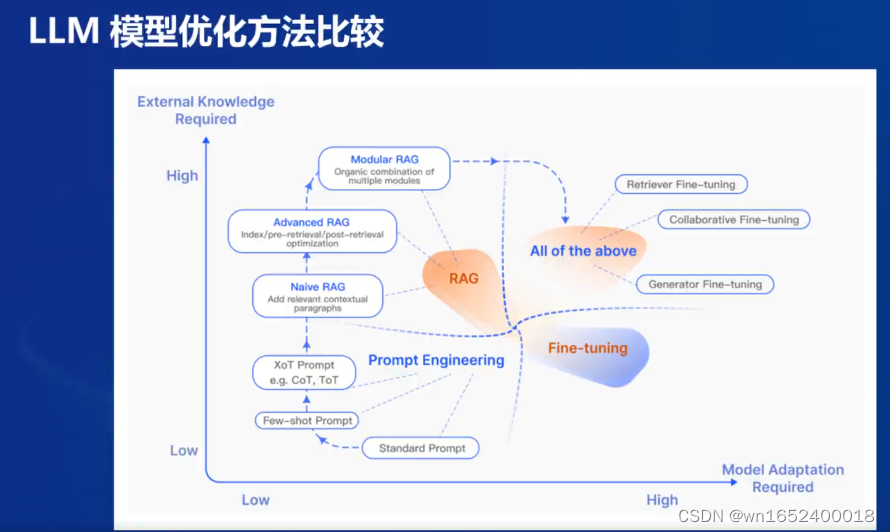
大模型优化常见的方法有Few-shot promt、XoT prompt等提示工程方法,RAG,微调,以及综合以上几种方法。上图在任务对外部知识的需求和任务对模型适配度的需求两个方面比较了几种优化方法。可见RAG适用于高外部知识需求、模型适配度需求不高的场景。
RAG的评估框架和基准测试
经典评估指标:
1. 准确率(Accuracy)
2. 召回率(Recall)
3. F1分数(F1 Score)
4. BLEU分数(用于机器翻译和文本生成)
5. ROUGE分数(用于文本生成的评估)
RAG 评测框架: 对抗噪音的鲁棒性、拒答能力、融合能力、真实性、回答问题的相关度、总结能力、纠错能力等多维度的评估。
1. 基准测试-RGB、RECALL、CRUD
2. 评测工具-RAGAS、ARES、TruLens

















 2494
2494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









