








文章目录
01 前言
在了解数据仓库前,先贴上一张数据仓库的流程图,本文会逐步讲解下图的各个组件。
1.1 数据仓库流程图
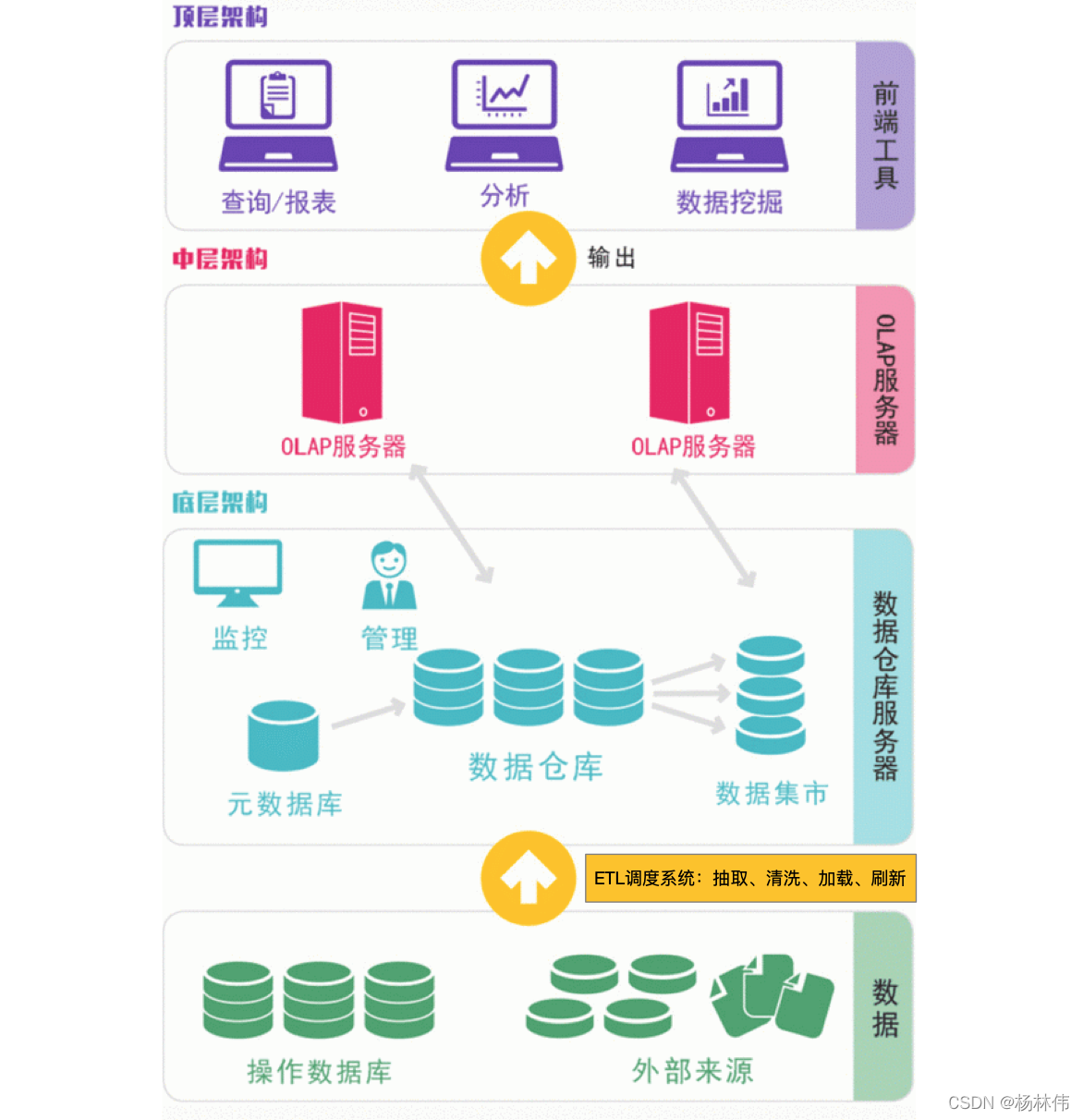
1.2 数据仓库系统图
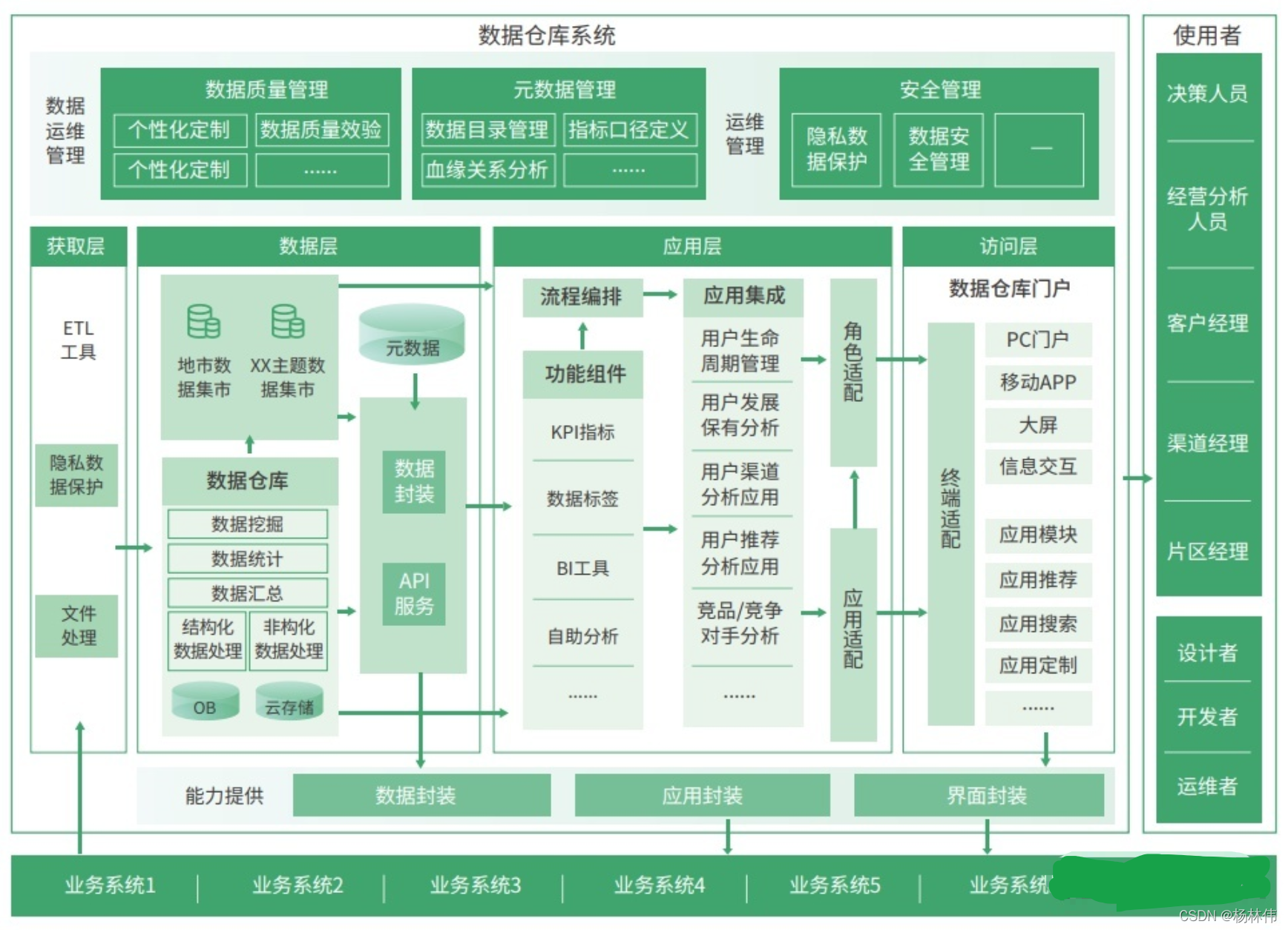
以下是一张中大型企业的很详细的数据仓库架构图(此图来自:https://www.zhihu.com/question/20623931):
02 为何需要数据仓库?
在我们的日常开发中,很多时候一个业务可能涉及多张表,举个例子:
比如我们做了一个图书管理系统,有以下几张表:
| 表名 | 逻辑表名 | 备注 |
|---|---|---|
| 图书主表 | t_book | 图书主要信息,例如“书名” |
| 图书价格表 | t_book_price | 图书价格信息,关联t_book表 |
| 图书作者表 | t_book_author | 图书作者表,关联t_book表 |
如果我们要同时查询 “书名”、“价格”、“作者”并整理成一条数据返回,这个时候,我们需要用到了联表查询,但是随着业务的庞大,数据量暴增,联表查询的效率会快速下降,那么有什么解决方案吗?这个时候就有了“数据仓库”了!
我们可以把这些几张表的数据根据我们的定义的规则(模型)整合成一条数据存入我们的数据仓库。
传统的 ETL 工作就是把业务数据库中提取、加工、来导入分析性的数据库(数据仓库)。
03 数据仓库概述
3.1 定义
引用:“数据仓库之父比尔·恩门(
Bill Inmon)在1991年出版的“Building the Data Warehouse”(《建立数据仓库》)一书中所提出的定义被广泛接受——数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。”
定义:数据仓库(Data Warehouse,简写为DW或DWH)是一个面向主题的、集成的、相对稳定的、且随时间变化的数据集合,用于支持管理决策。
特点::
- 面向主题:指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关,比如我们可以定义模型自动生成表;
- 相对稳定:数据一旦进入数据仓库,就不能再被改变了,当在操作型系统中把数据改变后,再进入数据仓库就会产生新的记录。这样数据仓库就保留了数据变化的轨迹;
- 集成:数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出来,进行加工与集成,统一与综合(
ETL)之后才能进入数据仓库; - 随时间变化:数据仓库要体现出数据随时间变化的情况,并且可以反映在过去某一个时间点上数据是什么样子的,也就是随时间变化的含义。而传统的操作型系统,只能保存当前数据,体现当前的情况;
- 支持管理决策:数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如:开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
3.2 数据仓库与传统数据库对比
下面我整理了 传统数据库(DB) 与 数据仓库(DW ) 的对比表格:
| 类型 | 数据仓库(DW) | 传统数据库(DB) |
|---|---|---|
| 作用 | 数据分析 | 事务处理 |
| 结构 | 相对简单的(Denormalized)表格结构,存储结构相对松散,多冗余数据。 | 相对复杂的表格结构,存储结构相对紧致,少冗余数据 |
| 读写 | 一般只是读优化 ,并行查询(要进行找Node的location之类的预运算) | 读和写都有优化 |
| 查询 | 相对复杂的read query,单次作用于相对大量的数据(历史数据) | 相对简单的read/write query,单次作用于相对的少量数据 |
| 存储空间 | 可能存在大量冗余重复的数据 | 主表与次表保存数据 |
| 市面产品 | AWS Redshift, Greenplum, Hive | MySQL, Oracle, SqlServer |
04 数据目录
A data catalog is a metadata management tool designed to help organizations find and manage large amounts of data – including tables, files and databases – stored in their ERP, human resources, finance and e-commerce systems as well as other sources like social media feeds. - https://searchdatamanagement.techtarget.com
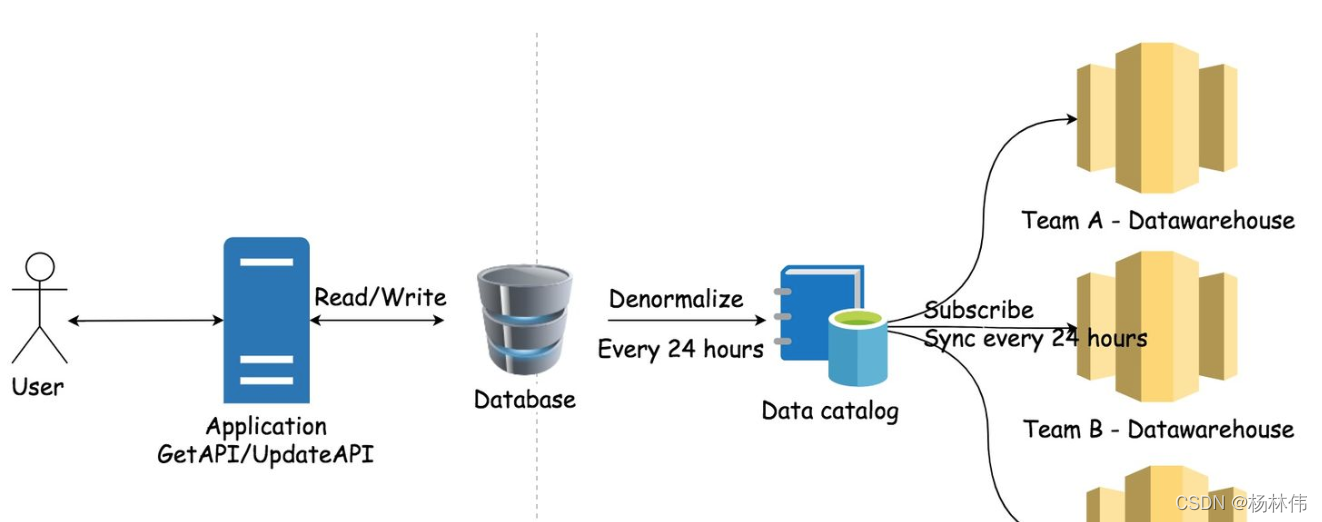
如果有很多不同的组需要共享同一个Datawarehouse,那么他们的脚本可能会相互影响,那么这个时候就用到了数据目录(Data Catalog)的概念。
数据目录:通过数据目录储存元数据,然后发布出去让不同组的数据仓库都可以同步这个数据。这样,每个不同组的数据仓库都拿到了同样的Denormalized数据,但是却相互独立开了。如下图(摘自知乎:https://www.zhihu.com/question/20623931):
数据目录(分区)有如下好处:
- 数据装载
- 数据访问
- 数据存档
- 数据删除
- 数据监控
- 数据存储
05 数据仓库分层
下面来了解一下数仓的一些概念ODS,DM,DWD,DWS,DIM,附上一张自己整理的图:
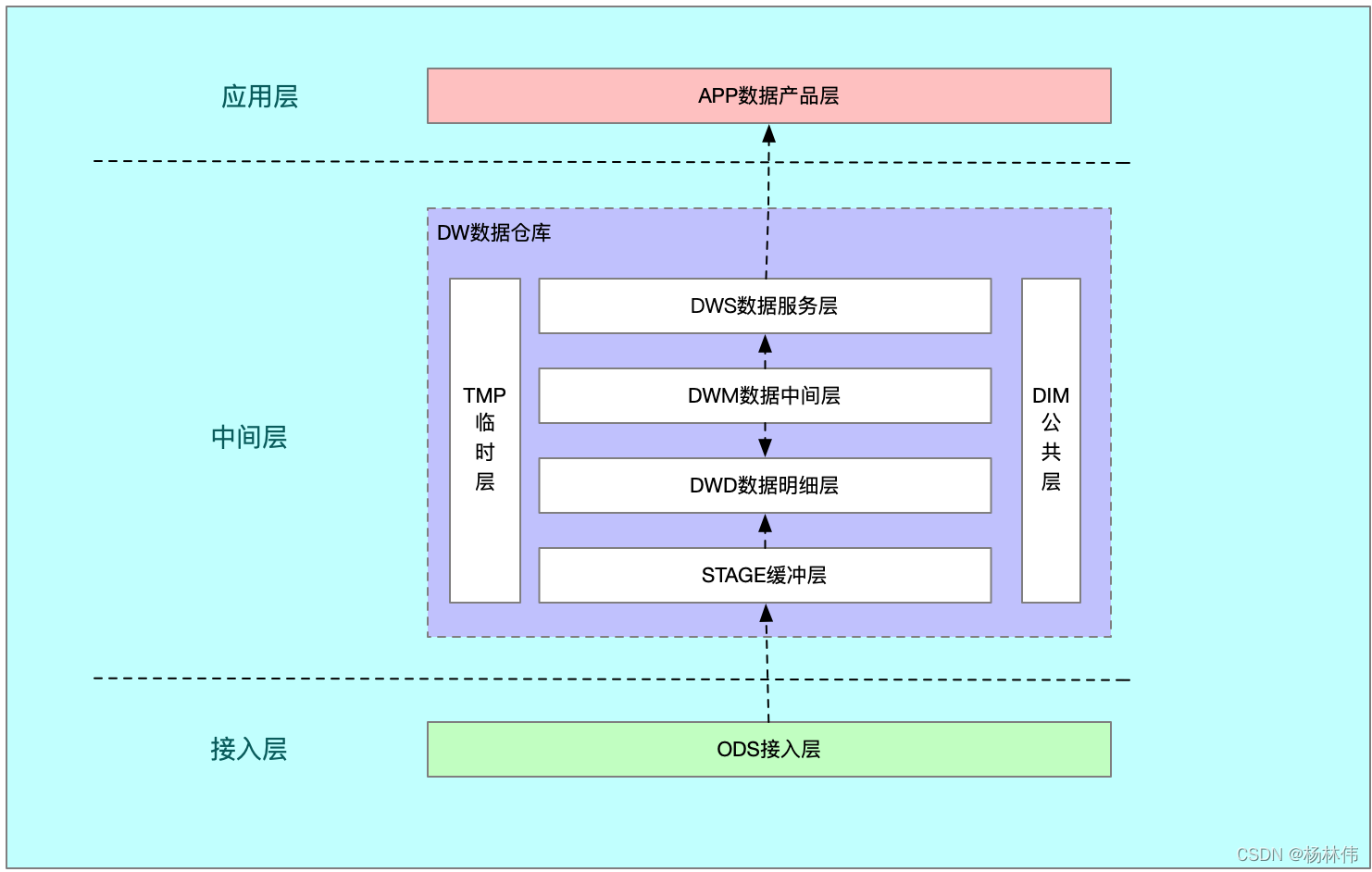
5.1 ODS层
数据从源表拉过来,进行etl(比如`mysql 映射到hive,那么到了hive里面就是ods层),但是,这一层面的数据却不等同于原始数据。在源数据装入这一层时,要进行诸如:
- 去噪:例如有一条数据中人的年龄是 1000 岁,这种属于异常数据,就需要提前做一些处理
- 去重:例如在个人资料表中,同一
ID却有两条重复数据,在接入的时候需要做一步去重 - 字段命名规范
- 。。。。。。
5.2 DW数据仓库层
DW就是数据仓库层,我们从ODS层获取数据,然后写入DW,在写入DW之前,需要按照主题建立各种数据模型,因此DW可以细分为:
- 数据明细层:DWD(Data Warehouse Detail)
- 数据中间层:DWM(Data WareHouse Middle)
- 数据服务层:DWS(Data WareHouse Servce)或 DM(Data Market数据集市)
5.2.1 STAGE临时缓冲层
概念:STAGE 层就类似于一个临时缓存区,屏蔽对业务系统的干扰,一般与业务系统保持一致,一般都会有数据老化机制,不用长期保存,不对外开放数据。
5.2.1 DWD数据明细层
DWD 概念:是数据仓库的细节数据层,是对stage层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中,明细层跟stage层的粒度一致,属于分析的公共资源(部分数据直接来自kafka,部分数据为接口层数据与历史数据合成);
5.2.2 DWM数据中间层
概念:轻度汇总层数据仓库中DWD层和DWS层之间的一个过渡层次,是对DWD层的生产数据进行轻度综合和汇总统计(可以把复杂的清洗,处理包含,如根据PV日志生成的会话数据)。
轻度综合层与DWD的主要区别在于二者的应用领域不同:
DWD的数据来源于生产型系统,并未满意一些不可预见的需求而进行沉淀;- 轻度综合层则面向分析型应用进行细粒度的统计和沉淀
| 分类 | 描述 |
|---|---|
| 数据生成方式 | 由明细层按照一定的业务需求生成轻度汇总表。明细层需要复杂清洗的数据和需要MR处理的数据也经过处理后接入到轻度汇总层 |
| 日志存储方式 | 内表,parquet文件格式 |
| 日志删除方式 | 长久存储 |
| 表schema | 一般按天创建分区,没有时间概念的按具体业务选择分区字段 |
| 库与表命名 | 库名(dwb)、表名(初步考虑格式为:dwb日期业务表名,待定) |
| 旧数据更新方式 | 直接覆盖 |
5.2.3 DWS数据服务层
概念:又称数据集市DM或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
| 分类 | 描述 |
|---|---|
| 数据生成方式 | 由轻度汇总层和明细层数据计算生成 |
| 日志存储方式 | 使用impala内表,parquet文件格式 |
| 日志删除方式 | 长久存储 |
| 表schema | 一般按天创建分区,没有时间概念的按具体业务选择分区字段 |
| 库与表命名 | 库名(dm)、表名(初步考虑格式为:dm日期业务表名,待定 ) |
| 旧数据更新方式 | 直接覆盖 |
5.2.4 DIM公共层
概念:DIM层是数据仓库数据中,各层公用的维度数据,比如:省市县数据。
5.3 APP数据产品层
概念:应用层(数据产品层)是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql、ES中使用,如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
| 分类 | 描述 |
|---|---|
| 数据生成方式 | 由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层 |
| 日志存储方式 | 使用impala内表,parquet文件格式 |
| 日志删除方式 | 长久存储 |
| 表schema | 一般按天创建分区,没有时间概念的按具体业务选择分区字段 |
| 库与表命名 | 库名(暂定apl),表名(另外根据业务不同,不限定一定要一个库,其实就叫app_)就好了 |
| 旧数据更新方式 | 直接覆盖 |
06 ETL调度系统
6.1 ETL概述
对接入数据仓库的数据进行清洗、数据仓库各层间数据流转都需要大量的程序任务来操作,这些任务一般都是定时的,并且之间都是有前后依赖关系的,为了能保证任务的有序执行,就需要一个ETL调度系统来管理。
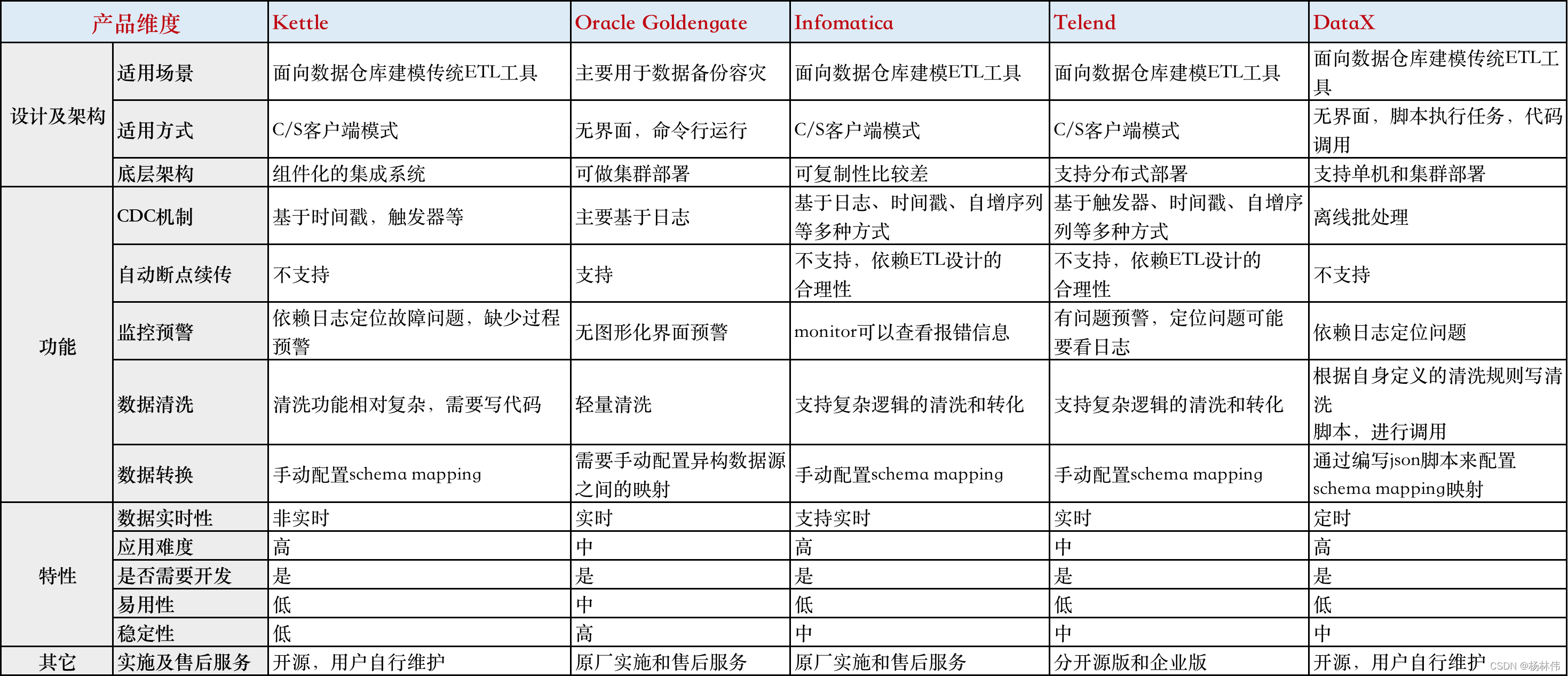
6.2 ETL工具选型
辛苦整理,有需要的童鞋直接私聊
07 元数据管理
元数据概念:
- 描述数据的数据叫做元数据;
- 元数据信息一般包括表名、表描述信息、所在数据库、表结构、存储位置等基本信息;
- 元数据还有表之间的血缘关系信息、每天的增量信息、表结构修改记录信息等等。
数据仓库中有大量的表,元数据管理的意思就是用来收集、存储、查询数据仓库中元数据,这为数据使用方提供了极大的便利。
08 OLAP(联机分析处理)
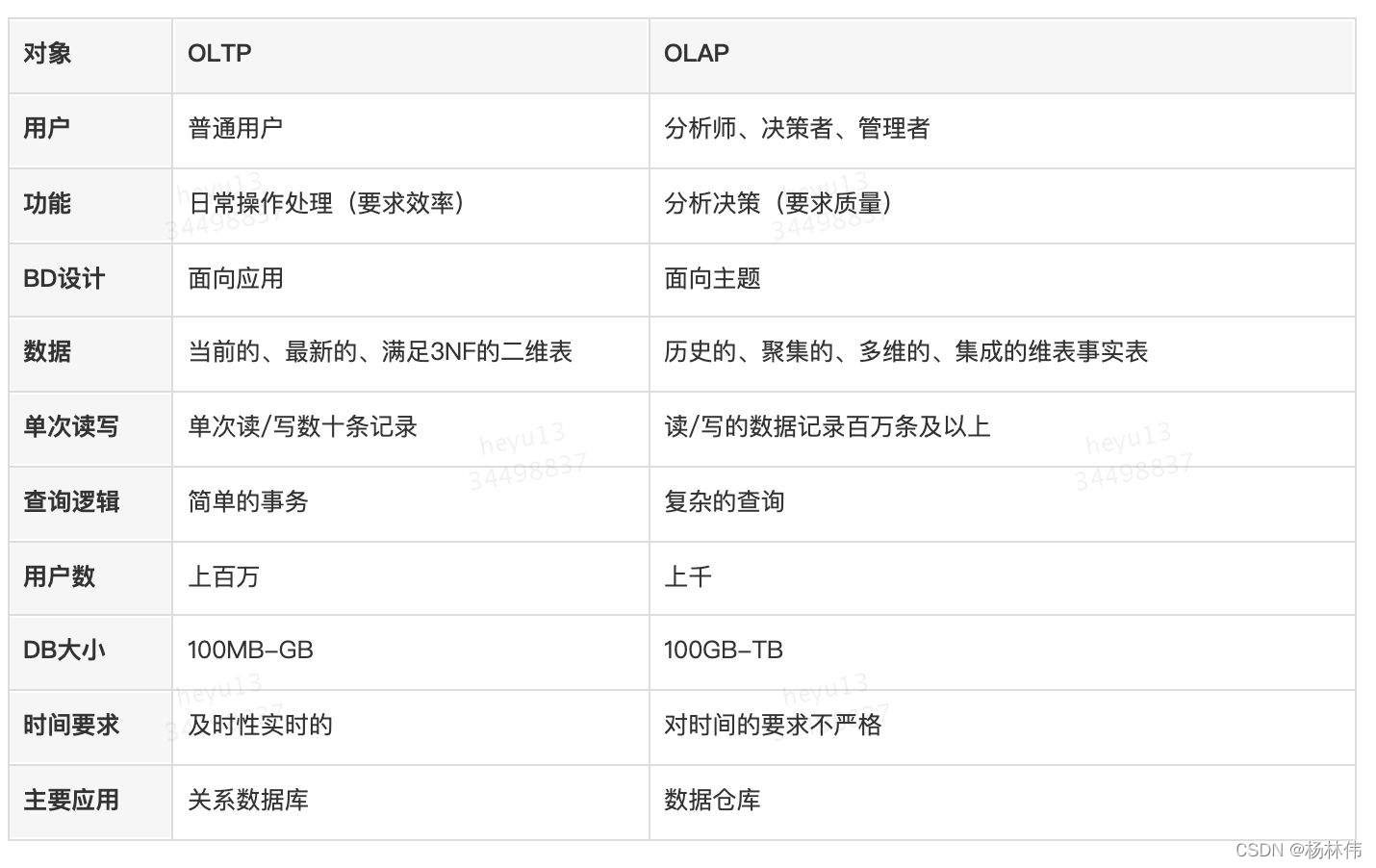
数据库与数据仓库的区别实际就是
OLTP与OLAP的区别。
OLTP:操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
OLAP :分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策(例如:智库,风控平台,BI平台),从决策中减少智商税。
它们两者间的不同点:
OLAP主流开源引擎有:Hive、Sparksql、Presto、Kylin、Impala、Druid、Clickhouse 等,由于不是本文的重点,大家可以去看《各个OLAP 引擎详细对比介绍》
09 文末
本文主要参考了以下的文献并结合自己的理解写出来的:

















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









