







文章目录
01 引言
在前面的博客,我们已经对Flink的程序模型里的Source使用有了一定的了解了,有兴趣的同学可以参阅下:
- 《Flink教程(01)- Flink知识图谱》
- 《Flink教程(02)- Flink入门》
- 《Flink教程(03)- Flink环境搭建》
- 《Flink教程(04)- Flink入门案例》
- 《Flink教程(05)- Flink原理简单分析》
- 《Flink教程(06)- Flink批流一体API(Source示例)》
本文开始继续讲解Flink程序模型对里面的Transformation。

02 Transformation
Transformation的官方API文档在:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/

操作概览如下图:

整体来说,流式数据上的操作可以分为四类:
- 第一类是 “对于单条记录的操作”:比如筛除掉不符合要求的记录(
Filter操作),或者将每条记录都做一个转换(Map操作); - 第二类是 “对多条记录的操作”:比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过
Window将需要的记录关联到一起进行处理; - 第三类是 “对多个流进行操作并转换为单个流”:例如,多个流可以通过
Union、Join或Connect等操作合到一起,这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作; - 第四类是 “DataStream 还支持与合并对称的拆分操作”:即把一个流按一定规则拆分为多个流(
Split操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
2.1 基本操作
2.1.1 API 解析
| 分类 | 描述 | 示意图 |
|---|---|---|
| map | 将函数作用在集合中的每一个元素上,并返回作用后的结果 | 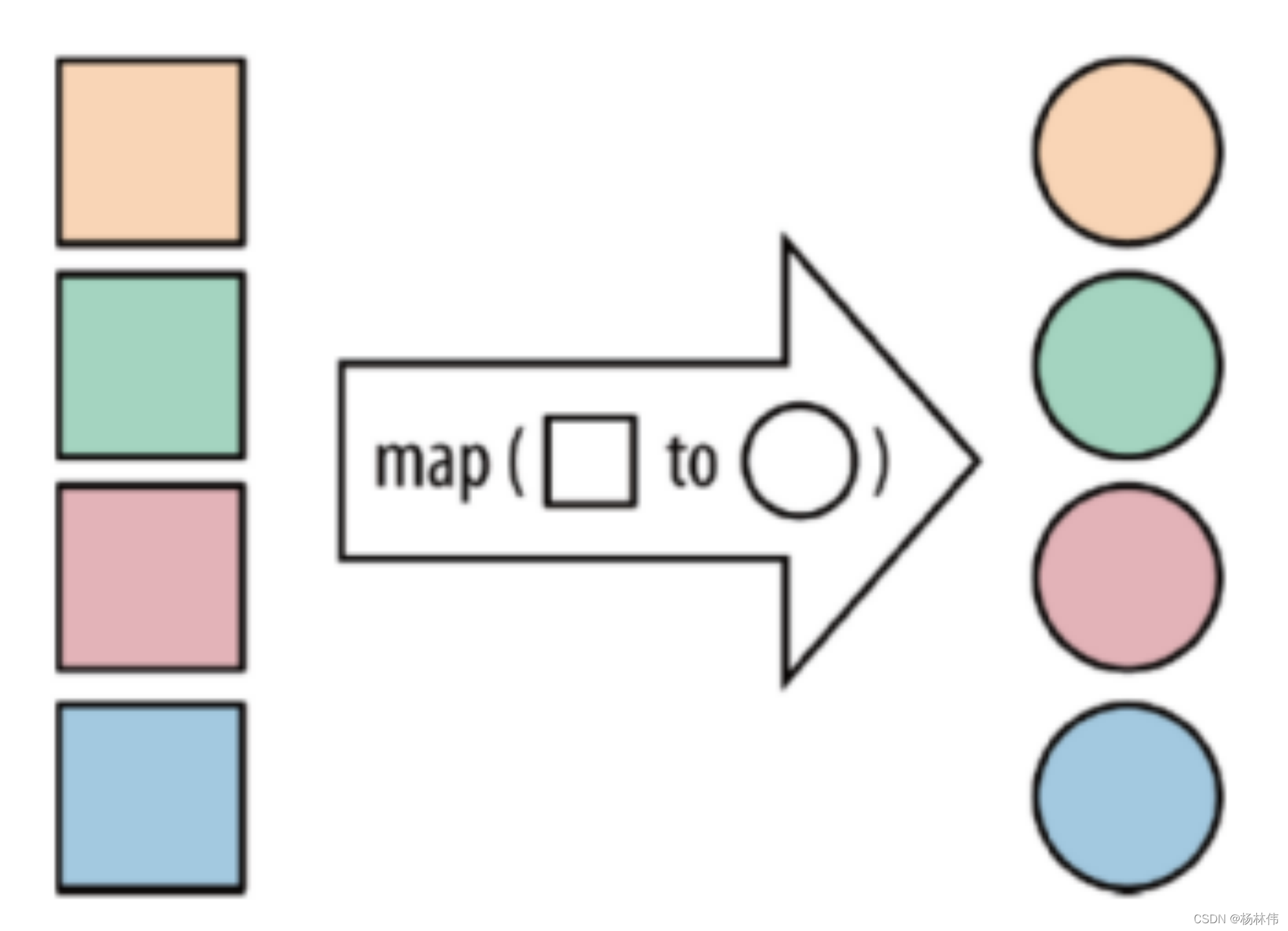 |
| flatMap | 集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果 | 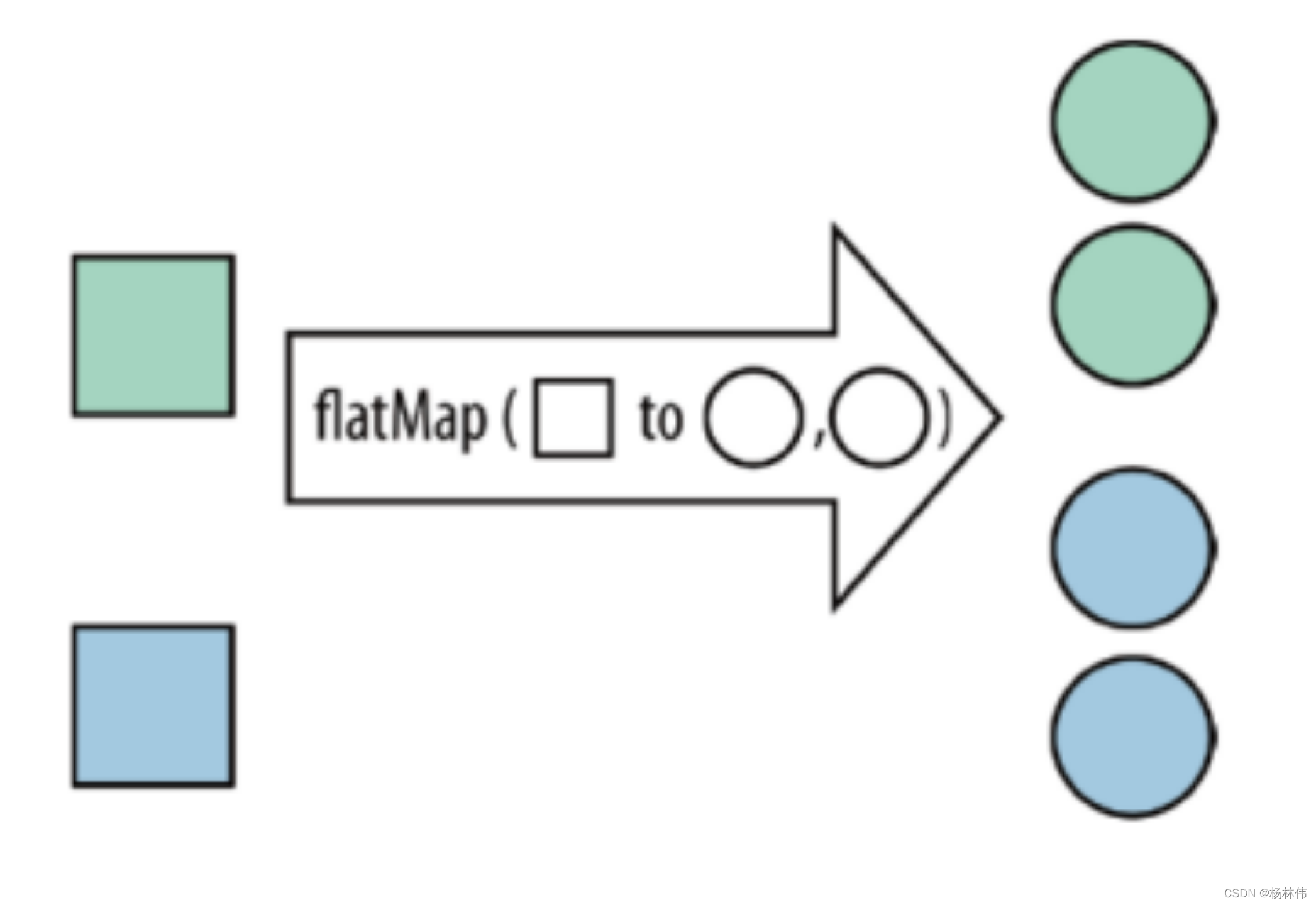 |
| keyBy | 按照指定的key来对流中的数据进行分组,前面入门案例中已经演示过(注意: 流处理中没有groupBy,而是keyBy ) | 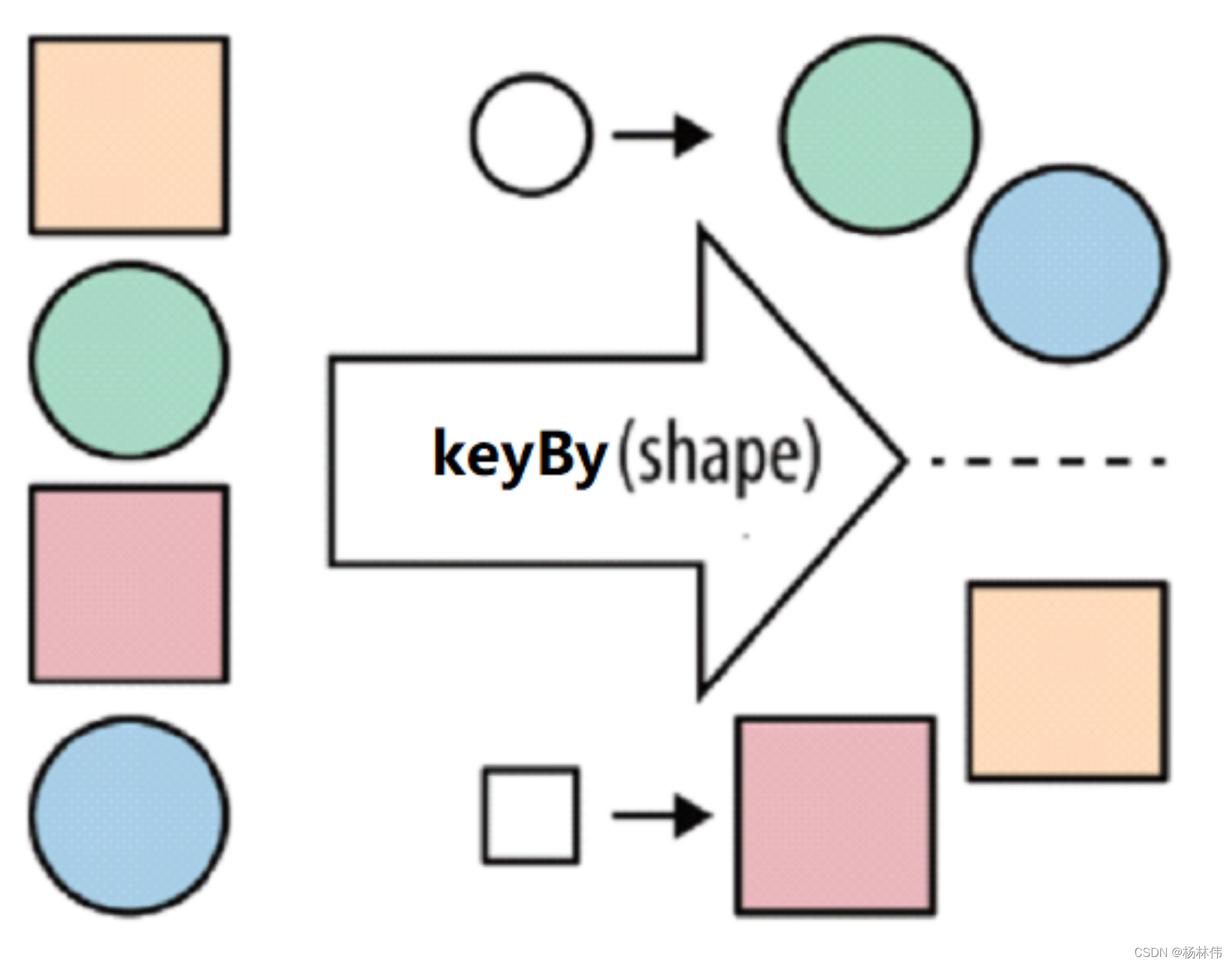 |
| filter | 按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素 | 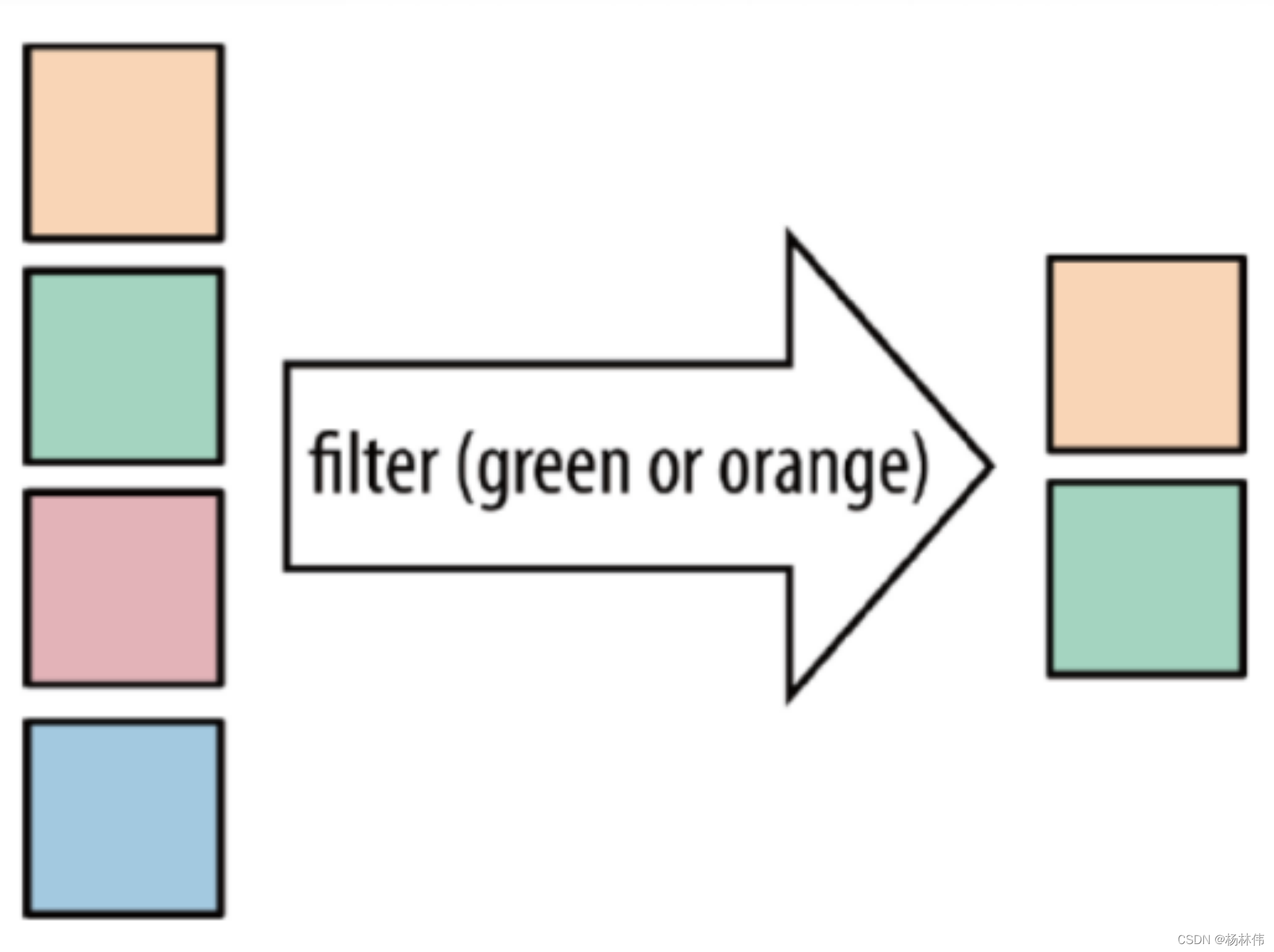 |
| sum | 按照指定的字段对集合中的元素进行求和 | 无 |
| reduce | 对集合中的元素进行聚合 | 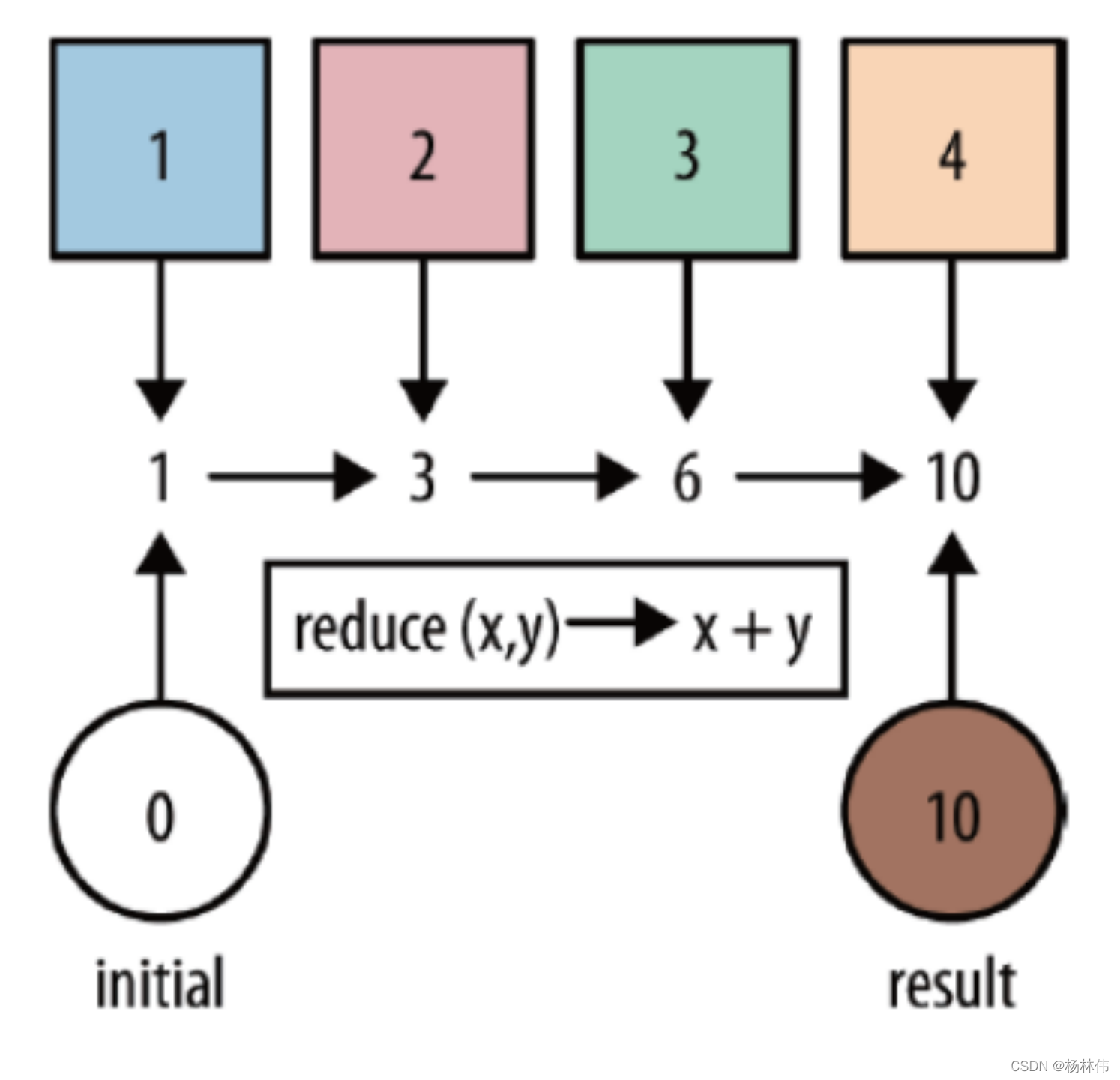 |
2.1.2 示例代码
示例代码如下:
/**
* Transformation-基本操作
*
* @author : YangLinWei
* @createTime: 2022/3/7 3:36 下午
*/
public class TransformationDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStream<String> linesDS = env.fromElements("ylw hadoop spark", "ylw hadoop spark", "ylw hadoop", "ylw");
//3.处理数据-transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
DataStream<String> filtedDS = wordsDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return !value.equals("ylw");
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = filtedDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
DataStream<Tuple2<String, Integer>> result1 = groupedDS.sum(1);
DataStream<Tuple2<String, Integer>> result2 = groupedDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value1.f1);
}
});
//4.输出结果-sink
result1.print("result1");
result2.print("result2");
//5.触发执行-execute
env.execute();
}
}
运行结果:

2.2 合并
2.2.1 union
union:union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重。

2.2.2 connect
connect:connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:
- connect只能连接两个数据流,
union可以连接多个数据流。 - connect所连接的两个数据流的数据类型可以不一致,
union所连接的两个数据流的数据类型必须一致。 - 两个
DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。

2.2.3 示例代码
现在有一个需求:将两个String类型的流进行union,将一个String类型和一个Long类型的流进行connect。
示例代码:
/**
* Transformation- union和connect
*
* @author : YangLinWei
* @createTime: 2022/3/7 3:44 下午
*/
public class TransformationDemo02 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//3.Transformation
DataStream<String> result1 = ds1.union(ds2);//合并但不去重 https://blog.csdn.net/valada/article/details/104367378
ConnectedStreams<String, Long> tempResult = ds1.connect(ds3);
//interface CoMapFunction<IN1, IN2, OUT>
DataStream<String> result2 = tempResult.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String value) throws Exception {
return "String->String:" + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long->String:" + value.toString();
}
});
//4.Sink
result1.print();
result2.print();
//5.execute
env.execute();
}
}
运行结果:

2.3 拆分
2.3.1 API
拆分用到的API:
Split就是将一个流分成多个流(注意:split函数已过期并移除);Select就是获取分流后对应的数据;Side Outputs:可以使用process方法对流中数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中。
2.3.2 示例代码
需求:对流中的数据按照奇数和偶数进行分流,并获取分流后的数据。
示例代码如下:
/**
* Transformation -拆分
*
* @author : YangLinWei
* @createTime: 2022/3/7 3:50 下午
*/
public class TransformationDemo03 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//3.Transformation
/*SplitStream<Integer> splitResult = ds.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
//value是进来的数字
if (value % 2 == 0) {
//偶数
ArrayList<String> list = new ArrayList<>();
list.add("偶数");
return list;
} else {
//奇数
ArrayList<String> list = new ArrayList<>();
list.add("奇数");
return list;
}
}
});
DataStream<Integer> evenResult = splitResult.select("偶数");
DataStream<Integer> oddResult = splitResult.select("奇数");*/
//定义两个输出标签
OutputTag<Integer> tag_even = new OutputTag<Integer>("偶数", TypeInformation.of(Integer.class));
OutputTag<Integer> tag_odd = new OutputTag<Integer>("奇数") {
};
//对ds中的数据进行处理
SingleOutputStreamOperator<Integer> tagResult = ds.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception {
if (value % 2 == 0) {
//偶数
ctx.output(tag_even, value);
} else {
//奇数
ctx.output(tag_odd, value);
}
}
});
//取出标记好的数据
DataStream<Integer> evenResult = tagResult.getSideOutput(tag_even);
DataStream<Integer> oddResult = tagResult.getSideOutput(tag_odd);
//4.Sink
evenResult.print("偶数");
oddResult.print("奇数");
//5.execute
env.execute();
}
}
运行结果:

2.4 分区
2.4.1 rebalance重平衡分区
类似于Spark中的repartition,但是功能更强大,可以直接解决数据倾斜。
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成:

所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散):

示例代码如下:
/**
* Transformation -rebalance
* @author : YangLinWei
* @createTime: 2022/3/7 4:05 下午
*/
public class TransformationDemo04 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC).setParallelism(3);
//2.source
DataStream<Long> longDS = env.fromSequence(0, 100);
//3.Transformation
//下面的操作相当于将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
//接下来使用map操作,将数据转为(分区编号/子任务编号, 数据)
//Rich表示多功能的,比MapFunction要多一些API可以供我们使用
DataStream<Tuple2<Integer, Integer>> result1 = filterDS
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//获取分区编号/子任务编号
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
DataStream<Tuple2<Integer, Integer>> result2 = filterDS.rebalance()
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//获取分区编号/子任务编号
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
//4.sink
//result1.print();//有可能出现数据倾斜
result2.print();//在输出前进行了rebalance重分区平衡,解决了数据倾斜
//5.execute
env.execute();
}
}
运行结果如下:
-
发生数据倾斜:

-
使用rebalance:
2.4.2 其它分区
| 类型 | 描述 |
|---|---|
| dataStream.global(); | 全部发往第一个task |
| dataStream.broadcast(); | 广播 |
| dataStream.forward(); | 上下游并发度一样时,一对一发送 |
| dataStream.shuffle(); | 随机均匀分配 |
| dataStream.reblance(); | Round-Robin(轮流分配) |
| dataStream.recale(); | Local Round-Robin(本地轮流分配) |
| dataStream.partitionCustom(); | 自定义单播 |
说明:
- recale分区:基于上下游
Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。
举例:
- 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。
- 若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
示例代码如下:
/**
* Transformation -partiton
*
* @author : YangLinWei
* @createTime: 2022/3/7 4:17 下午
*/
public class TransformationDemo05 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> linesDS = env.fromElements("hello me you her", "hello me you", "hello me", "hello");
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
//3.Transformation
DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();
DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();
DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();
DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();
DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();
DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();
DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
return key.equals("hello") ? 0 : 1;
}
}, t -> t.f0);
//4.sink
//result1.print();
//result2.print();
//result3.print();
//result4.print();
//result5.print();
//result6.print();
result7.print();
//5.execute
env.execute();
}
}
运行结果如下:

03 文末
本文主要讲解Flink批流一体API中的Transformation用法,谢谢大家的阅读,本文完!















 7728
7728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









