







 超级会员免费看
超级会员免费看
文章目录
Joy_caption
Joy_caption 是一个专注于图像转文本描述的模型,设计目标是生成高质量、详细且符合语义逻辑的自然语言描述。其核心优势在于深度学习技术的应用,能够精准捕捉图像中的细节,并生成流畅、易于理解的文本输出。对于需要高精度内容描述的场景,例如教育、内容创作或文学分析,这款模型提供了一个可靠的解决方案,非常适合对图像有深入语义理解需求的用户。
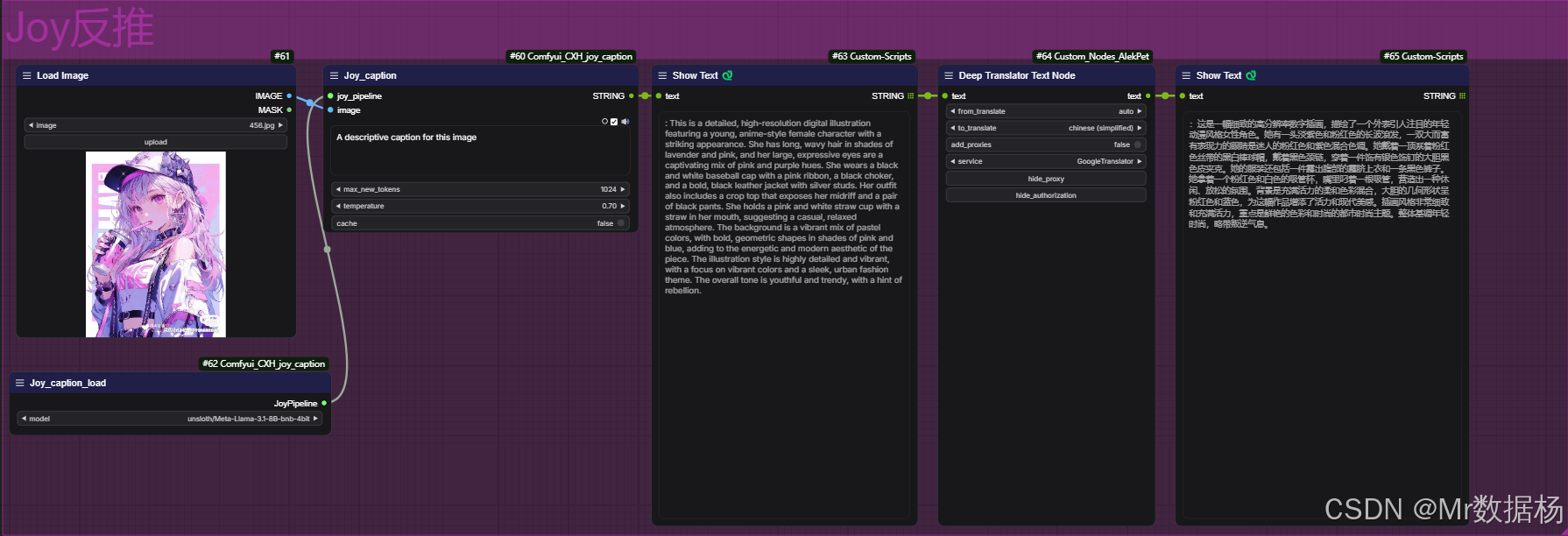
SD选用模型
unsloth/Meta-Llama-3.1-8B-bnb-4bit 和 meta-llama/Meta-Llama-3.1-8B 是基于Meta-Llama 3.1的两种实现版本,具有一致的参数规模(8B)和文本生成能力。两者主要通过存储效率、推理速度以及精度表现等方面的差异,满足从轻量化到高精度的多样化需求。以下是针对这两个模型的详细对比表。
| 模型名称 | 存储需求 | 内存使用 | 推理速度 | 精度表现 | 功能描述 | 应用场景 | 模型 |
|---|

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3627
3627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











