







项目背景:Our example concerns a big company that wants to understand why some of their best
and most experienced employees are leaving prematurely. The company also wishes to
predict which valuable employees will leave next.
案例说明:
本次案例需要的包包括:
library(plyr) # Rmisc的关联包,若同时需要加载dplyr包,必须先加载plyr包
library(dplyr) # filter()
library(ggplot2) # ggplot()
library(DT) # datatable() 建立交互式数据表
library(caret) # createDataPartition() 分层抽样函数
library(rpart) # rpart()
library(e1071) # naiveBayes()
library(pROC) # roc()
library(Rmisc) # multiplot() 分割绘图区域
数据分析基本步骤:
(1)业务理解;(2)明确业务需求(需求分析);(3)数据获取;(4)数据理解
(5)数据探索分析(数据的描述性分析);(6)数据预处理;(7)建模预测;(8)模型评估与应用
1、业务背景:我们所关心的问题是,为什么一些大的公司里,他们最优秀最有经验的员工会过早的离职?公司希望能够预测这些最有价值的员工接下来是否会离职。
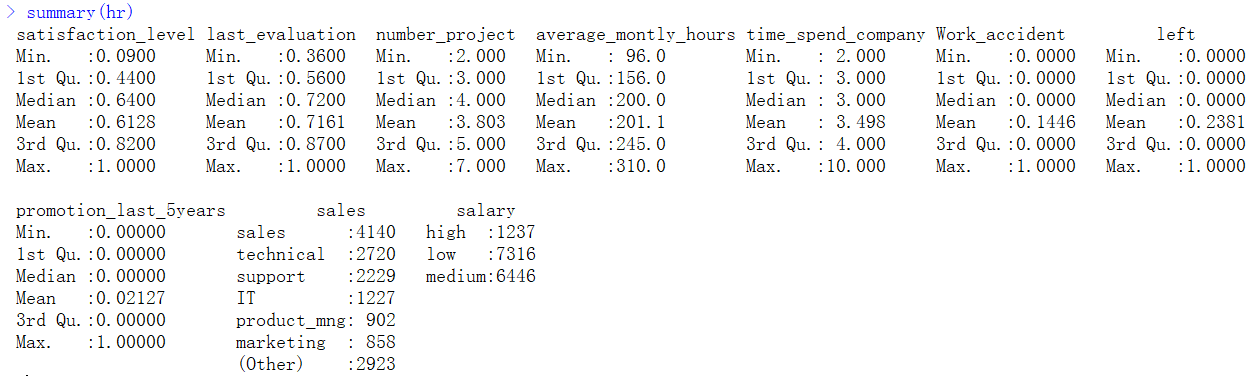
2、数据理解:我们使用的数据是CSV数据文件格式,其中自变量9个,因变量为是否离职。下表对所有变量进行了说明,以便更好的理解数据。

3、数据探索分析:上表备注中的结果是如何得到的?这就是数据探索性分析。以下是对原始数据进行数据探索分析的过程。
(1)观察各个变量的数据结构及主要描述统计量。
hr <- read.csv("E:\\HR_comma_sep.csv")
str(hr)
summary(hr)a. str(hr)用来查看各个变量的数据结构

b. summary(hr)来查看各个变量的主要描述统计量
(2)探索员工对公司满意度、绩效评估和月均工作时长和工作年限与是否离职的关系,并绘制箱线图。
后续我们会用到决策树模型及朴素贝叶斯模型进行预测,模型要求目标变量必须为因子型(分类变量),而我们的数据中,目标变量left为int型,所以,首先我们将其数据类型转化为因子型。
hr$left<-factor(hr$left,levels = c("0","1"))a. 探索员工对公司满意度与是否离职的关系
# 绘制对公司满意度与是否离职的箱线图
box_s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5306
5306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









