







前言
本章对ES中的核心概念做进一步的讲解
方法
1.文档
在之前的讲解中,我们将索引理解为关系数据库的表,而文档是索引中的数据,所以我们自然的理解为关系数据库中的一条数据。
由于在ES中存在文档类型(Type)的概念,所以一个索引中所存储的文档结构上可能是不同的。
如果上面的解释你仍然不是很理解,那么简单点——索引(index)就是数据库,文档类型(Type)就是表,文档(Document)是其中的数据,这样是不是容易理解些了呢
当我们查询数据的时候,文档的结构是这个样子的:
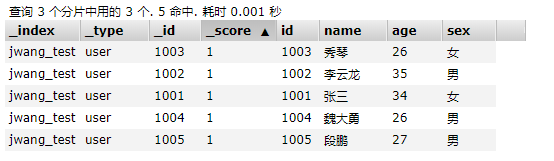
其中,id,name,age,sex我们都了解,这个是我们自己设置的,那么其他的又是什么呢?
我们称之为元数据(Metedata):
- _index:代表一个document存储在哪个index中。类似的数据(document)放在同一个index,不同类型的数据放在不同的index。
- 索引名必须是小写,不能用下划线(_)开头,不能包含逗号。
- _type:代表document属于index下 的哪个类别(type)。一个index通常包含多个type。type名称可以大写或小写,不能用下划线(_)开头,不能包含逗号。
- _id:代表document的唯一标识,与index和type一起确定一个唯一的document。可以手动指定,也可es自动生成。手动指定:PUT /index/type/id 自动生成: PUT /index/type/ 生成base64编码的20长度的字符串ID,分布式集群下不可能重复。
- _score:相关度分数:匹配程度,分数越高越相关。
2.查询响应
1)pretty
我们之前创建索引也好,增加文档数据也好,使用的都是Postman或者谷歌的插件
那么我们尝试使用浏览器直接查询会怎么样呢?
浏览器下输入网址http://localhost:9200/jwang_test/user/_search,观察效果:

很显然,这实在是太难看了,这也是我们为什么用其他工具的原因。。
但是ES提供了对应的参数pretty对我们的显示结果做了美化!输入网址http://localhost:9200/jwang_test/user/_search?pretty,观察效果:

由局部的显示我们可以发现它为我们做了json的格式化操作,显得一目了然!
2)指定响应字段——?_source
有些时候我们并不需要将文档中的全部字段显示出来,那么我们应该怎么做呢?
范例:仅显示id和name
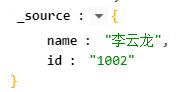
GET http://localhost:9200/jwang_test/user/1002?_source=id,name
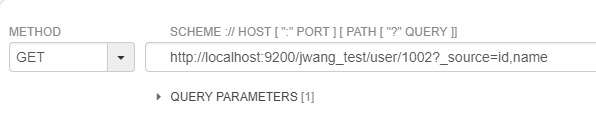
响应结果如下:
3)只显示原始字段,不需要显示元数据信息——/_source
有些时候我们并不需要将文档中的元数据显示出来,那么我们应该怎么做呢?
GET http://localhost:9200/jwang_test/user/1002/_source
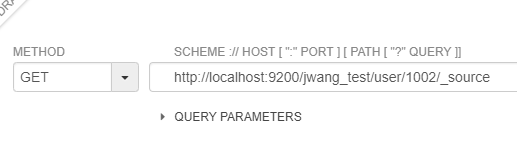
响应结果如下:

3.判断文档是否存在
有时候,我们需要判断某个文档是否存在,而不是查询它的内容!
语法:HEAD /{索引名称}/{文档类型}/{文档id}
范例:查询id为1001和1006的文档是否存在
我们首先查询一下我们jwang_test索引库中的所有文档:
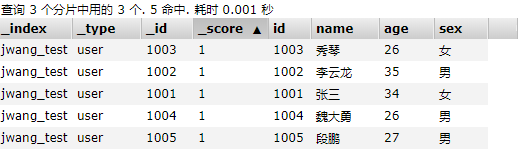
查询id为1001:
http://localhost:9200/jwang_test/user/1001
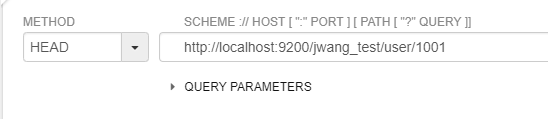
响应状态码为200则代表存在:

查询id为1006结果为:
4.批量操作
1)批量查询:_mget
范例:查询id为1002和1003的文档数据
POST http://localhost:9200/jwang_test/user/_mget
{
"ids":["1002","1003"]
}查询结果如下所示:

2)批量添加:_bulk
语法格式:
{action:{metedata}}\n
{source body}\n
{action:{metedata}}\n
{source body}\n
......注意:每条数据后需要加换行,最后一行也要加
范例:新增三条数据
{"create":{"_index":"jwang_test","_type":"user","_id":"1006"}}
{"id":"1006","name":"楚云飞","age":30,"sex":"男"}
{"create":{"_index":"jwang_test","_type":"user","_id":"1007"}}
{"id":"1007","name":"孙德胜","age":33,"sex":"男"}
{"create":{"_index":"jwang_test","_type":"user","_id":"1008"}}
{"id":"1008","name":"田雨","age":26,"sex":"女"}
发起请求:POST http://localhost:9200/jwang_test/user/_bulk
再次查询结果如下,可见我们批量添加成功!
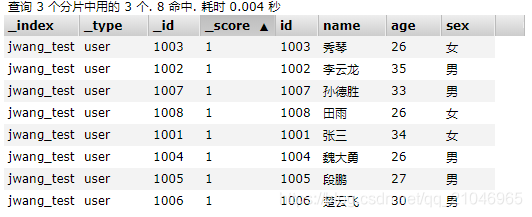
2)批量删除:_bulk
{"delete":{"_index":"jwang_test","_type":"user","_id":"1006"}}
{"delete":{"_index":"jwang_test","_type":"user","_id":"1007"}}
{"delete":{"_index":"jwang_test","_type":"user","_id":"1008"}}
这样就可以将上面的数据删除,这里我就不演示了。
5.分页
在ES默认的搜索中,默认最多返回10条数据,多了不再返回。
那么这个时候就需要用到我们的分页操作了!
参数:
size:每页显示的结果数量
from:跳过多少结果数
我们先来看看我们目前索引中的所有数据:
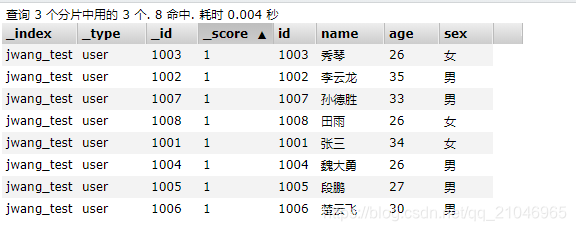
范例:每页显示三条数据,显示第一页
发起请求:POST http://localhost:9200/jwang_test/user/_search?size=3&from=0
请求结果如下:

范例:每页显示四条数据,显示第二页
发起请求:POST http://localhost:9200/jwang_test/user/_search?size=4&from=4
请求结果如下:

6.映射
前面我们创建了索引之后,我们可以直接往里面添加索引信息。
我们知道,关系型数据库添加数据必须要定义表的字段类型,我们在ES中还并没有发现这个设定。不要着急!
如果我们没有指定字段类型的话,ES会默认给我们的字段赋上相应的类型哦!
| JSON数据 | ES中的数据类型 |
|
| boolean |
| Whole number:123 | long |
| Floating Point:123.123 | double |
| string,valid date:"2019-10-20" | date |
| string | text |
ES支持的基本数据类型:
字符串 : text, keyword
text:存储数据的时候,会自动分词,并生成索引
keyword:存储数据的时候,不会分词,而是直接整个词拿去建索引
整数 : byte, short, integer, long
浮点数 : float、double
布尔型 : boolean
日期 : date
知道了上面这些,那我们就可以创建指定数据类型结构的索引了
范例:创建指定类型结构的索引
发起请求:PUT http://localhost:9200/jwang1
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 0
}
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"hobby": {
"type": "text"
}
}
}
}查询索引的映射信息:
GET http://localhost:9200/jwang1/_mapping
反馈的结果如下:


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









