







一、感知机
1、感知机概念
给定输入x,权重w,和偏移b,感知机输出:
o
=
σ
(
⟨
w
,
x
⟩
+
b
)
σ
(
x
)
=
{
1
if
x
>
0
0
otherwise
o=\sigma(\langle\mathbf{w}, \mathbf{x}\rangle+b) \quad \sigma(x)=\left\{\begin{array}{ll} 1 & \text { if } x>0 \\ 0 & \text { otherwise } \end{array}\right.
o=σ(⟨w,x⟩+b)σ(x)={10 if x>0 otherwise
各种区别:
感知机输出的离散的类:0或1
线性回归输出的是实数
softmax回归输出的是各个类别的概率
2、训练感知机
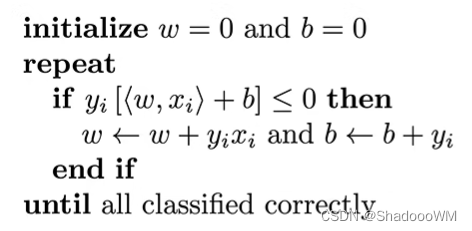
if 预测错误则执行,并更新w,b
等价于使用批量大小为1的梯度下降,使用的损失函数如下:
ℓ
(
y
,
x
,
w
)
=
max
(
0
,
−
y
⟨
w
,
x
⟩
)
\ell(y, \mathbf{x}, \mathbf{w})=\max (0,-y\langle\mathbf{w}, \mathbf{x}\rangle)
ℓ(y,x,w)=max(0,−y⟨w,x⟩)
总结:
- 感知机是一个二分类模型,是最早的AI模型之一。
- 它的求解算法等价于使用批量大小为1的梯度下降。
- 他不能解决XOR函数。
二、多层感知机
1、概念
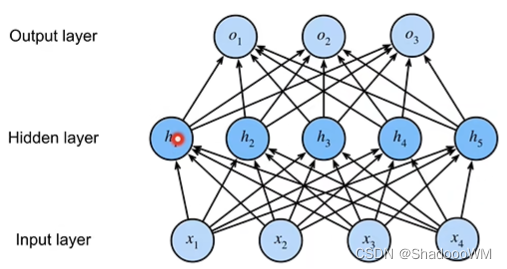
- 多层感知机的的引入原因是感知机无法区分XOR问题,只能产生线性平面,所以使用多层感知机来解决该问题。
- 多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。
2、激活函数
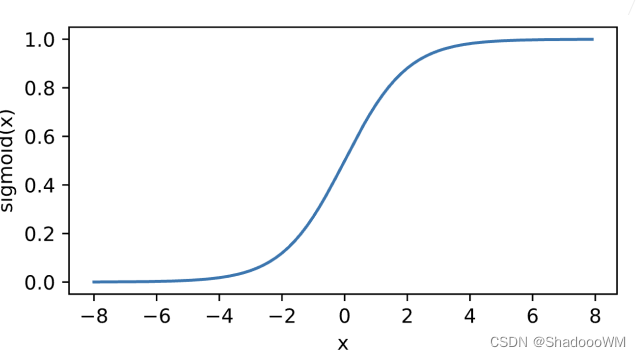
1、Sigmoid函数
将输入投影到 (0,1)
sigmoid
(
x
)
=
1
1
+
exp
(
−
x
)
\operatorname{sigmoid}(x)=\frac{1}{1+\exp (-x)}
sigmoid(x)=1+exp(−x)1
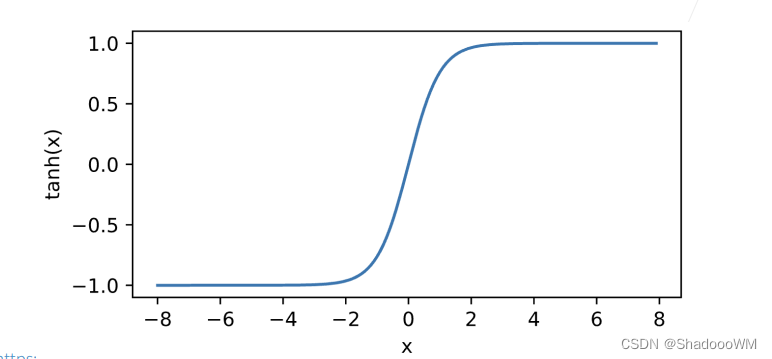
2、tanh函数
将输入投影到(-1.1)
tanh
(
x
)
=
1
−
exp
(
−
2
x
)
1
+
exp
(
−
2
x
)
\tanh (x)=\frac{1-\exp (-2 x)}{1+\exp (-2 x)}
tanh(x)=1+exp(−2x)1−exp(−2x)
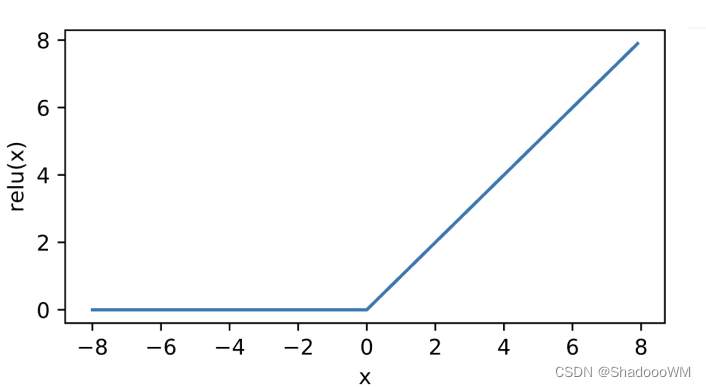
3、Relu函数(常用)
ReLU
(
x
)
=
max
(
x
,
0
)
\operatorname{ReLU}(x)=\max (x, 0)
ReLU(x)=max(x,0)
三、实现多层感知机
1、从0实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(
torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(
torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
#Relu函数的实现
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a) #各个元素相对位置求最大值,结果就是小于0取0大于零取大的值
#实现模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) #矩阵乘法使用@符号
return (H @ W2 + b2)
#定义损失函数使用交叉熵损失函数 在多分类中常用
loss = nn.CrossEntropyLoss()
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
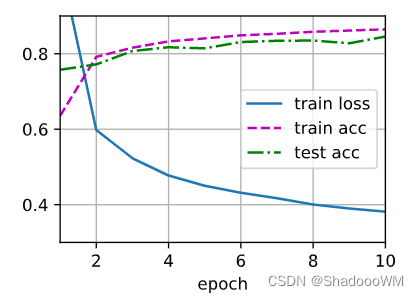
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
2、简洁实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









