







系列文章目录
1.Cache相关知识介绍
目录
前言
使用M7内核的MCU,为提升性能,此系列文章记录对STM32H7的MPU和Cache的学习。
本文主要写的关于Cache的相关知识,非上板应用。
文中参考的相关手册下载链接:Cache相关资料手册资源-CSDN文库
一、Cache的介绍
1.1 为什么需要Cache
现在常用的微控制器的主频高达几百MHz,而目前的主要存储器设备主要为动态存储器(容量大,速度比静态慢),其工作的频率低于CPU的主频。那么,如果指令和数据都放在主存储器中,整个系统的性能将受到存储器的制约,因此在CPU和存储器之间增加一个高速缓冲区(Cache)充当中间角色,就能提高对存储器的平均访问速度,从而提高系统的存储性能。
以STM32H7x3为例,如下图为系统框架图,从图中可知,DTCM和ITCM是紧密耦合内存,其速度和内核的速度一致,而AXI SRAM挂在AXI总线上,SRAM1、SRAM2、SRAM3挂在D2域的AHB总线上,SRAM4和Bkp SRAM挂在D3域的AHB总线上。
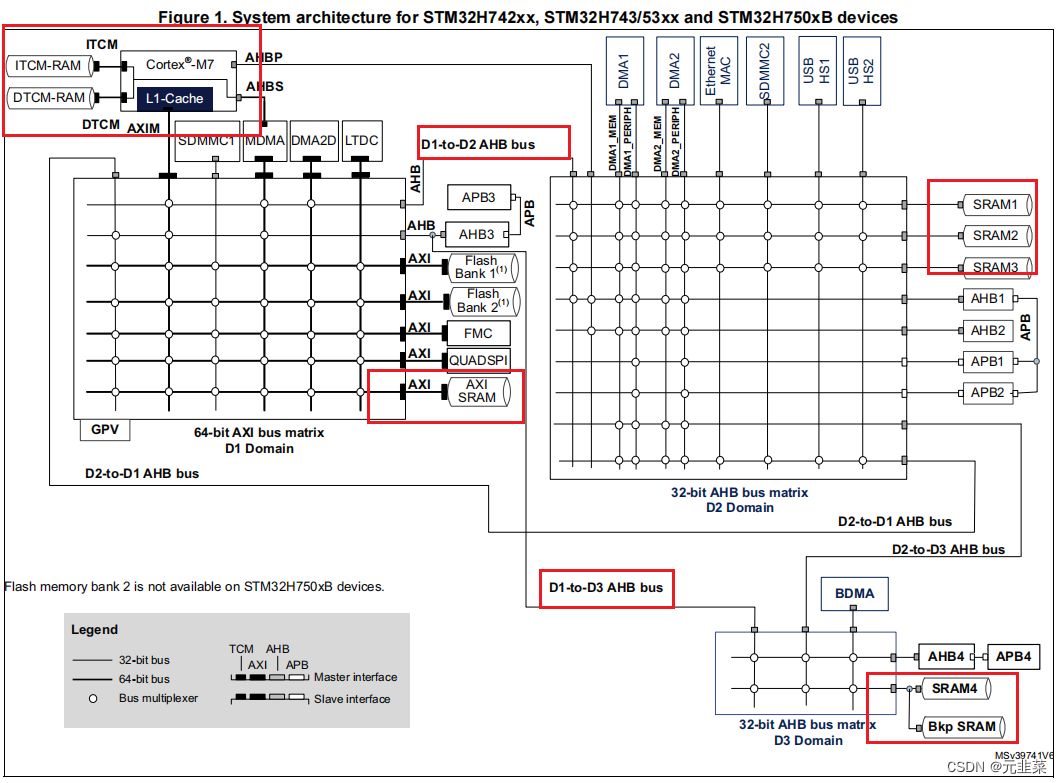
在规格书中,可以看到内核主频达480MHz,而AHB和AXI总线最大只能达240MHz,是主频的一半,故除了DTCM和ITCM两块内存,其他的RAM最大频率只能为240MHz,当CPU要访问这些内存时,需要降频处理,这直接限制了系统的性能
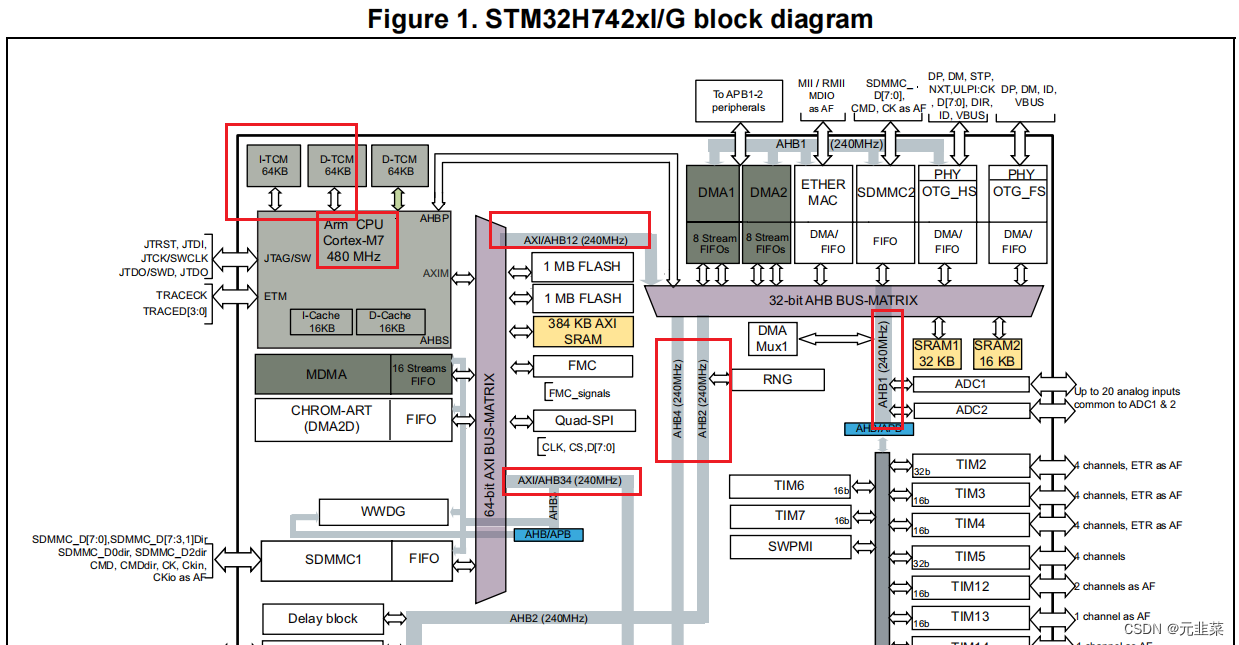
为了解决这个问题,就引入Cache缓存。如果每次CPU要读写SRAM区的数据,都能够在Cache里面进行,自然是最好的,实现了240MHz到480MHz的飞跃(提高了CPU对存储器的平均访问速度),但同时也会引入一些问题:
①完美实现频率的飞跃实际是做不到的,因为数据Cache大小是有限的,总有用完的时候。
②由于数据将存在在不同的物理位置,故有可能会造成数据的不一致性。
1.2 Cache相关概念
1.2.1 块(Cache line)
Cache 与主存储器之间以块(cache line)为单位进行数据交换,Cache 在逻辑上被划分为若干 cache line,对应着一组存储器的位置,因此,Cache 与主存储器交换数据的最小粒度就是 cache line。
以STM32H74x为例:
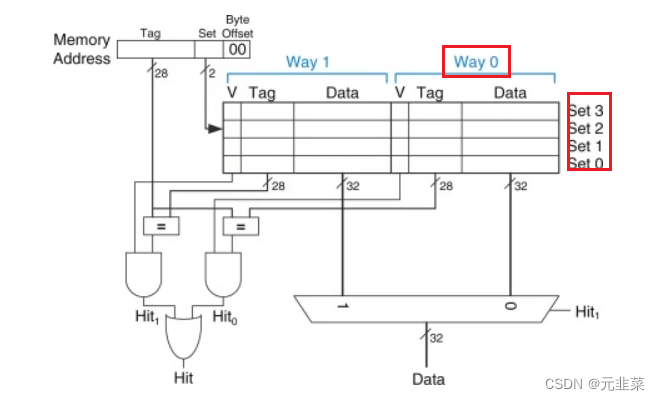
这个系列有指令cache和数据cache,大小均为16kb的缓存空间,可缓存指令和数据。所有Cortex®-M7上的L1缓存被分成32字节的行。每行都标有一个地址。数据缓存是4路集合关联的(每组4行),指令缓存是2路集合关联的。这是一种硬件折衷,以避免必须用地址标记每行。


每个way可以理解为页,数据Cache有四个way,相当于4个页,每个页16Kb/4=4Kb,
而又每一行为32字节,故有4Kb/32byte=128行。这里每个cache line的大小就为32字节。
set的理解:所有way的同一行。
1.2.2 时钟局部性和空间局部性
高速缓冲存储器是全部用硬件来实现的,因此,它不仅对应用程序员是透明的,而且对系统程序员也是透明的。Cache 与主存储器之间以块(cache line)为单位进行数据交换。当 CPU 读取数据或者指令时,它同时将读取到的数据或者指令保存到一个 cache 块中。这样当 CPU 第2次需要读取相同的数据时,它可以从相应的 cache 块中得到相应的数据。因为 cache 的速度远远大于主存储器的速度,系统的整体性能就得到很大的提高。实际上,在程序中通常相邻的一段时间内 CPU 访问相同数据的概率是很大的,这种规律称为时间局部性。
不同系统中,cache 的块大小也是不同的。通常 cache 的块大小为几个字。这样当 CPU 从主存储器中读取一个字的数据时,它将会把主存储器中和 cache 块同样大小的数据读取到 cache 的一个块中。比如,如果 cache 的块大小为4个字,当CPU从主存储器中读取地址为 n 的字数据时,它同时将地址为 n、n+1、n+2、n+3 的4个字的数据读取到 cache 中的一个块中。这样,当 CPU 需要读取地址为 n、n+1、n+2 或者 n+3 的数据时,它可以从 cache 中得到该数据,系统的性能将得到很大的提高。实际上,在程序中,CPU 访问相邻的存储空间的数据的概率是很大的,这种规律称为空间局部性。
1.2.3 Cache Hit 和 Cache Miss
- Cache命中(Cache Hit)——CPU要访问的数据/指令已经存在缓存里;
- Cache未命中(Cache Miss)——CPU要访问的数据/指令不在缓存里;
如果发生 cache miss 并且 cache 未满,则在 cache 中发现一个位置,并把新的缓存数据存到这个位置。如果 cache 已满,则要通过 cache 替换策略进行 cache line 的替换,腾出空闲的位置后,再将新的缓存数据存到这个位置。
1.2.4 WA、WT、RA、WB
WA即write through(透写),写数据时同时更新缓存和存储器,缓存行不被标记为“dirty。这样,当某一个 cache line 需要替换时,就不必将其中的数据写到主存储器中去了,新调入的块可以立即把这一块覆盖掉。这种方式,对写操作性能没有提升,因为还是需要降频对存储器进行写操作,但可以避免数据的不一致性。
WB即write back(回写)——写数据时,只更新缓存,然后将 cache line 标记为“dirty”,当这个缓存行被新的缓存行替换,或者手动 clean (API函数)的时候,再将数据写到存储器中。这种方法不会及时更新最新数据到存储器中,当DMA等其他CPU访问这块内存时,可能会出现数据不一致性。
Dirty 是标记那些需要写回到存储器中的缓存数据。当一个“dirty”的缓存行被新的缓存行替代时,就需要从缓存中移除一个缓存行(cache line),为新的数据腾位置,这个过程称为驱逐(Eviction)。
RA即读操作分配 cache,当进行数据写操作时,如果 cache 未命中,只是简单地将数据写入主存中。只有在数据读取时,才进行 cache 内容预取。
WA即写操作分配 cache,当进行数据写操作时,如果 cache 未命中,cache 系统将会进行 cache 内容预取,从主存中将相应的块读取到 cache 中相应的位置,并执行写操作,把数据写入到 cache 中。对于写通类型(WT)的 cache,数据将会同时被写入到主存中,对于写回类型(WB)的 cache 数据将在合适的时候写回到主存中。
由于写操作分配 cache 增加了 cache 内容预取的次数,它增加了写操作的开销,但同时可能提高 cache 的命中率,因此这种技术对于系统的整体性能的影响与程序中读操作和写操作数量有关。
二、Cache的工作流程
2.1.工作原理
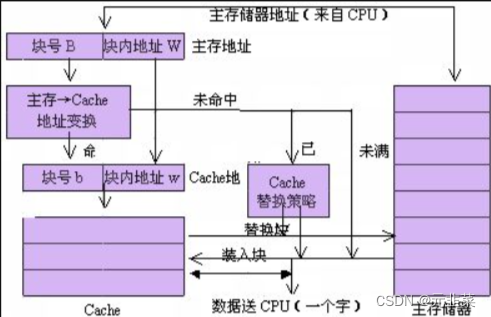
流程大致如下:
①CPU发送需要读取的地址,存储在主存地址寄存器中。
②地址变换模块将主存地址变换为Cache地址,存储在Cache地址寄存器中。
③如果Cache命中,则在Cache中找到数据,直接返回给CPU。根据实现WT、WB的方式和Cache的替换策略,在合适的时候将数据写回存储器。
如果Cache为命中,则将主存地址发给主存储器,从主存储器中得到或写入数据,并根据Cache替换策略(分满和未满两种情况),将主存储器的数据缓存到Cache中。
三、数据不一致性问题
因为有了Cache的存在,同一个地址上的数据就可能存在在多个区域Cache、主存储器等。
因此,对这块地址上数据操作时,在其他副本的数据就不是最新的,没有及时更新。
例子:假设CPU对RAM地址0x2000~0x2100这块地址都赋值为0x0A,而这块地址已经在Cache,那么CPU就会这些数据写在Cache里面,而RAM上这块地址的数据,并没有任何变化,如果此时DMA去这块地址搬运数据,那么搬运到的就不是最新数据。(WB模式会出现,WT模式不会出现)
反过来同理,DMA更新了数据,而Cache中没有更新,CPU去Cache取的不是最新数据
以下为摘录:
(1)地址映射关系变化造成的数据不一致
当系统中使用了 MMU 时,就建立了虚拟地址到物理地址的映射关系。如果查询 cache 时进行的相联比较使用的是虚拟地址,则当系统中虚拟地址到物理地址的映射关系发生变化时,可能造成 cache 中数据和主存中数据不一致的情况。
(2)指令 cache 的数据一致性问题
当系统中采用独立的数据 cache 和指令 cache 时,一些操作序列可能造成指令不一致的情况。
四、参考文献
例说STM32F7高速缓存——Cache一致性问题(一)-CSDN博客
言简意赅的介绍M7内核的Cache工作流程,摸爬滚打半年的经验总结 - STM32H7 - 硬汉嵌入式论坛 - Powered by Discuz! (armbbs.cn)



















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











