







正则表达式
正则表达式是一个特殊的字符序列,利用事先定义好的一些特定字符以及它们的组合组成一个“规则”,检查一个字符串是否与这种规则匹配来实现对字符的过滤与匹配
使用正则表达式需要导入re模块(import re)
re模块中的findall()方法
以列表的形式返回所有能匹配的子串,若未找到,则返回空列表
元字符
与自身不匹配,而是表明应和一些特殊的东西匹配,或会影响重复次数的特殊字符
常用的正则表达式元字符
- .:除换行符意外的任意字符
import re
s = 'hello world'
print(re.findall(r'.',s))
运行结果:

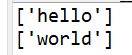
- [ ]:指定字符集
注:元字符在“[ ]”中不起作用;“[ ]”中若有“^”则表示补集
import re
s = 'hello world'
print(re.findall('[hello]',s))
s1 = '1234a'
print(re.findall('[0-9]',s1)) #[0-9]表示0到9之间的整数
运行结果:
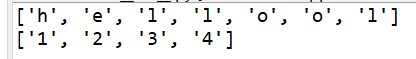
- ^:匹配行首,匹配以“^”后的字符开头的字符串
$:匹配行尾,匹配以$前面的字符结束的字符串
import re
s = 'hello world'
print(re.findall('^hello',s))
print(re.findall('world$',s))
运行结果:
-
\:可以加不同的字符以表示不同的特殊意义

-
*:匹配位于*之前的字符或子模式的0次或多次出现
+:匹配位于+之前的字符或子模式的1次或多次出现
import re
s = 'a ab abb abbb'
print(re.findall('ab*',s))
print(re.findall('ab+',s))
运行结果:

- ?:匹配位于?之前的0个或1个字符
注:当“?”紧随其他限定符之后时,匹配模式是“非贪心的”,即匹配搜索到尽可能短的字符串
import re
s = 'a ab abb abbb'
print(re.findall('ab?',s))
print(re.findall('ab+?',s))
运行结果:

- {m,n}:至少有m个变量,至多有n个重复
注:忽略m表示0个重复,忽略n表示无穷个重复
import re
s = 'a ab abb abbb'
print(re.findall('ab{0,1}',s))
print(re.findall('ab{0,}',s))
print(re.findall('ab{,0}',s))
运行结果:
















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









