






本博客暂时只做自己的学习笔记,所以部分细节并不会展开,如果有看官对这部分内容感兴趣,还请移步去看吴恩达的教学视频,这里奉上链接:改善深层神经网络
一、 首先介绍指数加权平均方法,对于一系列输入数据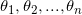
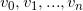
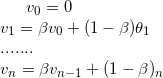
得到如下图所示
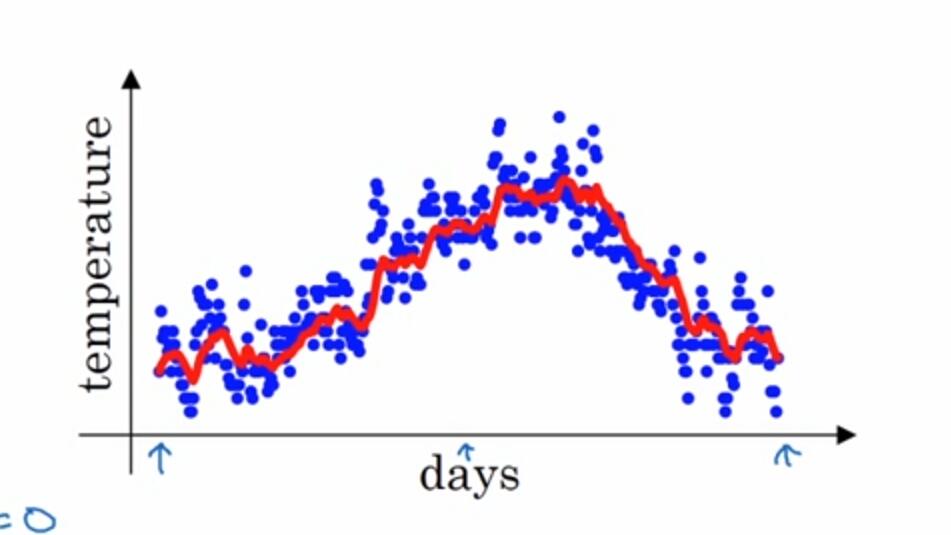
其中蓝色的点是输入数据,红色点是加权平均后的数据。不过在实际计算过程中,会在初始的加权过程产生偏差,如下图
我们希望得到的曲线是绿色那根,但实际上我们计算出来的是紫色的,基于此,我们希望对原来的计算方法做出偏差修正:
二、基于指数加权平均方法,对原来的mini batch梯度下降法做出改进,称为Momentum梯度下降法或动量梯度下降法
我们已经知道,在mini batch梯度下降法中,下降方向是会产生噪声的,如下图,我们总希望在搜索过程中,在y轴方向的搜索步长较小,而在x轴方向搜索步长较大,而在mini batch梯度下降法中,产生的搜索步长在y轴方向是反复震荡的,虽然每次的搜索步长都挺大,但是若干次加权平均后的y方向的搜索步长是很小的,这正符合我们的需求,这就是所谓的Momentum梯度下降法了。
具体做法是,在第t次迭代中,我们用mini-batch梯度下降法求得的梯度
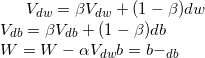
在这里,我们当然可以对上述算法加一个偏移修正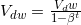
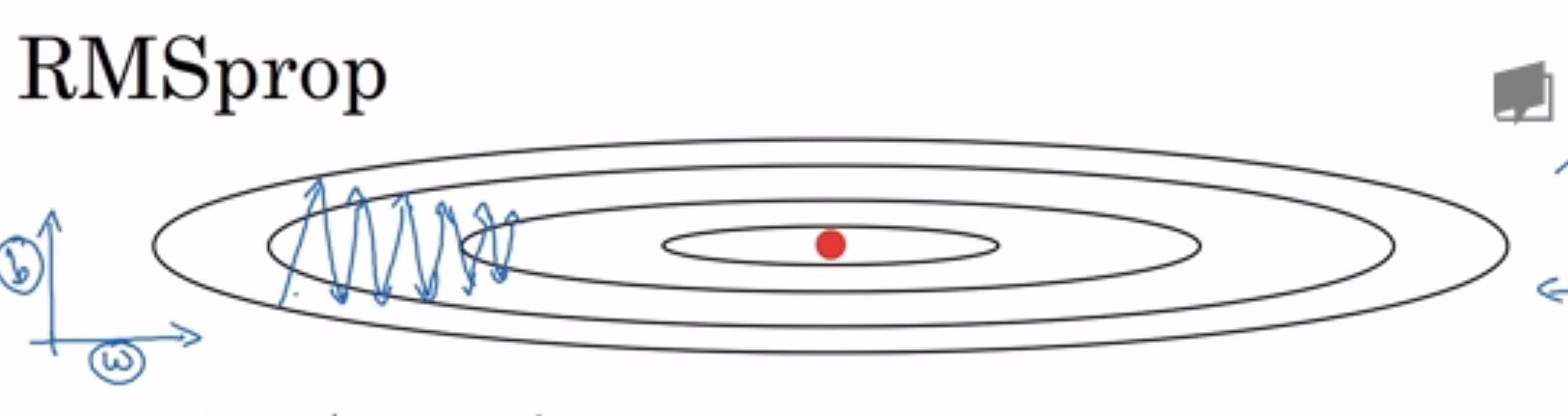
三、RMSprop (root mean square prop)
与Momentum梯度下降法类似,在梯度下降过程中,我们希望在搜索方向震荡很大的维度下降步长取小一点,而在搜索方向震荡较小的维度,搜索步长要大一点。对下述例子,搜索方向在y轴方向(在这个例子中是参数b的方向)反复震荡,导致每一步迭代搜索步长虽然都很大,但在若干次迭代之后实际上的目标函数值下降的很少,所以我们希望产生一系列新的下降梯度减小这种震荡。
定义:
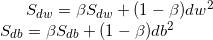
我个人理解上述两个指标是为了衡量在过去若干步中搜索方向的震荡程度,如果该值较大,我们应该考虑减小搜索步长,反之同理,所以一个自然的想法就是在用原来的梯度除以该值,得到RMSprop方法:
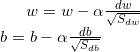
四、最后介绍一下Adam算法,实际上Adam算法就是Momentum算法和RMSprop算法结合的产物,直接上算法。
首先初始化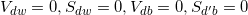
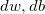
然后计算:
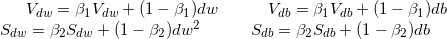
注意!在使用Adam算法时要使用偏差修正!!!
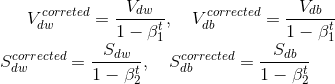
最后更新参数:
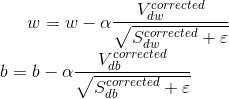















 6161
6161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









