







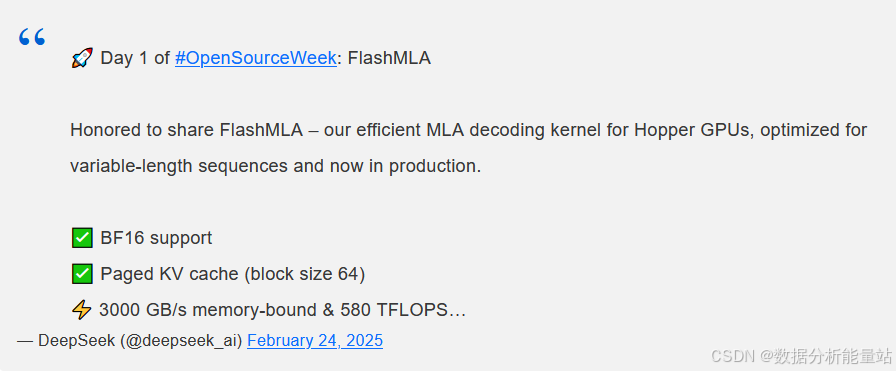
来自DeepSeek的重大消息!该公司正式推出了其首个开源代码库,借助CUDA内核提升大语言模型(LLMs)的速度与效率。此次更新的核心是FlashMLA,这是一种先进的多隐层注意力(MLA)解码内核,专门针对霍珀(Hopper)系列GPU进行了优化。这项技术能更高效地处理可变长度序列,让人工智能模型的托管变得更加流畅、快速。
-
发布亮点
-
BF16支持:BF16(Brain Floating Point 16)是一种16位的浮点数格式,相比传统的32位浮点数格式,它占用的内存更少,在深度学习计算中能加快数据处理速度,同时在许多场景下仍能保持足够的精度。支持BF16意味着在使用该技术进行计算时,可以在内存使用和计算效率之间取得更好的平衡,有助于提升整体性能。
-
Paged KV Cache with a block size of 64:这指的是采用了块大小为64的分页键值(KV)缓存技术。键值缓存常用于存储和快速检索数据,分页技术则可以更灵活地管理内存,按固定大小的块(这里是64)来划分和使用内存,有助于提高内存的使用效率,特别是在处理复杂的数据结构和大量数据时,能够更高效地存储和访问数据,从而提升系统的性能。
-
-
性能表现
在特定的硬件和软件环境下,即运行在配备CUDA 12.6的H800 SXM5 GPU上时,这些优化措施展现出了出色的性能。在内存受限的配置中,数据传输速度可达3000GB/s,这意味着数据在内存中的读写速度非常快,能够快速地为计算提供所需的数据。而在计算受限的场景里,计算能力达到580 TFLOPS(每秒万亿次浮点运算),表明该技术在进行复杂的浮点运算时,具备很强的计算能力。这种高性能使得人工智能推理得到了显著的升级,能够更快速、准确地处理任务。
-
对模型托管的影响
此前,DeepSeek模型已经在使用多隐层注意力(MLA)技术。而现在基于CUDA内核的FlashMLA技术,进一步提升了DeepSeek AI的R1 + V3模型的托管速度。这意味着在实际应用中,使用这些模型来处理任务时,无论是在线服务还是其他需要实时响应的场景,都能够更快地给出结果,提升了用户体验,也为模型在更多领域的应用提供了更好的性能支持。
1 What is FlashMLA?
这段文本围绕FlashMLA展开,从设计目的、硬件需求、精度优化及性能表现等方面进行介绍,旨在阐述其在AI领域的优势与适用性。以下是详细解释:
1. FlashMLA的设计目的与特点
-
专为特定架构设计:FlashMLA是专门针对英伟达Hopper GPU架构打造的优化型MLA解码内核。Hopper作为英伟达下一代架构,性能卓越,而FlashMLA正是为充分发挥该架构优势而设计。
-
注重性能与规模加速:设计过程中高度重视性能,体现了Deepseek致力于大规模加速AI模型的目标。在如今AI应用对处理速度要求极高的背景下,FlashMLA能确保每毫秒都得到高效利用,实现快速且高效的处理,满足各类对时间敏感的AI任务需求。
2. 硬件要求
-
特定GPU需求:运行FlashMLA需要高性能的Hopper架构GPU,如H800 SXM5。这类GPU具备强大的并行计算能力和先进的硬件特性,能支撑FlashMLA实现其高性能计算。
-
软件版本要求:为实现最佳性能,还需搭配CUDA 12.3及以上版本以及PyTorch 2.0及以上版本。CUDA是英伟达推出的并行计算平台和编程模型,高版本通常包含性能优化和新特性;PyTorch则是广泛使用的深度学习框架,其高版本在功能和性能上也有所提升,与FlashMLA协同工作可充分发挥其潜力。
3. 精度与优化
-
BF16精度支持:FlashMLA当前支持BF16(Brain Floating Point 16)精度。BF16是一种16位的浮点数格式,在深度学习计算中,它在保持一定数值稳定性的同时,相比32位浮点数格式能显著减少内存占用,加快数据处理速度,实现计算效率与精度的平衡,适用于AI模型的各类计算任务。
-
分页KV缓存优化:采用块大小为64的分页键值(KV)缓存技术。在大规模模型中,数据的存储和读取管理复杂,这种分页缓存机制通过将数据按固定大小(64字节块)进行划分和管理,能有效提高内存使用效率,减少数据访问延迟,提升模型整体运行效率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











