







银行信贷业务场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,评分卡打出的分数越高,客户的信用等级越高,风险越小。通常,有”四张卡“来评判个人的信用程度:A卡,B卡,C卡和F卡。常说的“评分卡”主要是指A卡,又称为申请者评级模型,金融机构用于判断是否应该借钱给一个新用户。今天主要研究A卡模型建模和代码实现,模型开发主要流程如下。
我们使用Kaggle的GiveMeSomeCredit数据集,该数据集有十个维度的数据和标注数据(即好客户或坏客户),15万条数据。
| 序号 | 维度指标 | 含义 |
| 1 | SeriousDlqin2yrs | 好客户和坏客户 |
| 2 | RevolvingUtilizationO fUnsecuredLines | 无担保放款的循环利用 |
| 3 | age | 借款人年龄 |
| 4 | NumberOfTime30-59Days PastDueNotWorse | 30-59天预期但是没有发展更坏的次数 |
| 5 | DebtRatio | 负债率 |
| 6 | MonthlyIncome | 月收入 |
| 7 | NumberOfOpenCredit LinesAndLoans | 开放贷款(如汽车贷款或抵押贷款)和信用贷款数量 |
| 8 | NumberOfTimes90DaysLate | 90天预期次数 |
| 9 | NumberRealEstate LoansOrLines | 不动产贷款数量 |
| 10 | NumberOfTime60-89Days PastDueNotWorse | 60-89天预期但是没有发展更坏的次数 |
| 11 | NumberOfDependents | 家属人数(不包括自己) |
一、数据加载和清洗
该数据集一共有15万客户的特征,而且每个客户都有标注的优质或非优质的信息,因此属于监督学习。该分类既有连续特征,也有离散特征,而且数据中存在一些异常值和缺失值。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import seaborn as sns
from scipy import stats
import statsmodels.api as sm
from sklearn import metrics
import copy
# 1.读取训练数据
training_data = pd.read_csv("GiveMeSomeCredit/cs-training.csv", index_col=0)
# 2.查看数据缺失情况
missing_values = training_data.isnull().sum()
# 月收入和家属人数两个变量的缺失较多
# SeriousDlqin2yrs 0
# RevolvingUtilizationOfUnsecuredLines 0
# age 0
# NumberOfTime30-59DaysPastDueNotWorse 0
# DebtRatio 0
# MonthlyIncome 29731
# NumberOfOpenCreditLinesAndLoans 0
# NumberOfTimes90DaysLate 0
# NumberRealEstateLoansOrLines 0
# NumberOfTime60-89DaysPastDueNotWorse 0
# NumberOfDependents 3924
# 3、使用中位数填充缺失值
for col in ['MonthlyIncome', 'NumberOfDependents']:
training_data[col] = training_data[col].fillna(training_data[col].median())
missing_values = training_data.isnull().sum()
# 4.删除重复的行,数据条数变成149192条
training_data = training_data.drop_duplicates()
# 5.观察数据分布情况,查看异常数据,文字和图标结合能够具体了解数据情况
training_data.describe()
for col in training_data.columns:
plt.title(col)
plt.hist(training_data[col])
plt.show()
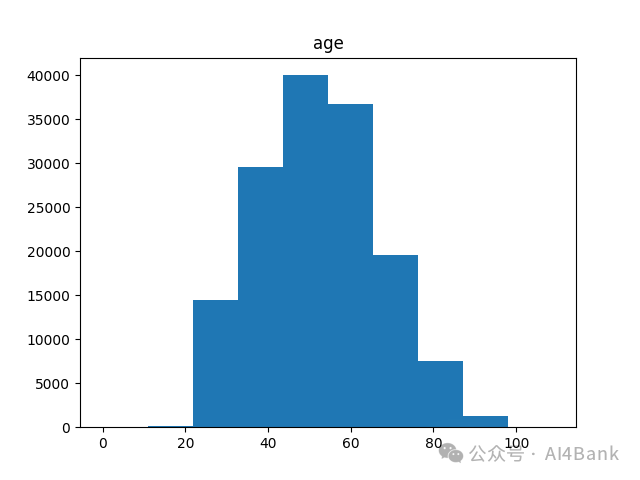
print(training_data[col].value_counts().sort_index())比如年龄分布情况,describe()输出结果,0岁明显是不合理数据。
0 121 15922 36523 58724 777...102 3103 3105 1107 1109 2Name: count, Length: 86, dtype: int64
下图展示每个年龄段的分布情况看,也符合正常情况。
处理以上发现的异常数据:
# 6.处理异常值
# 删除变量NumberOfTime30-59DaysPastDueNotWorse、NurmberOfTimes90DaysLate、NumberOfTime60-89DaysPastDueNotWorse的异常值
# 删除生日为0的异常数据
training_data = training_data[training_data['age'] > 0]
training_data = training_data[training_data['NumberOfTime30-59DaysPastDueNotWorse'] < 90]
training_data = training_data[training_data['NumberOfTime60-89DaysPastDueNotWorse'] < 90]
training_data = training_data[training_data['NumberOfTimes90DaysLate'] < 90]
# 好客户设为1,违约客户为0
training_data['SeriousDlqin2yrs'] = 1 - training_data['SeriousDlqin2yrs']查看变量之间的相关性, NumberOfTime3059DaysPastDueNotWorse,
NNumberOfTimes90DaysLate和NumberOfTime6089DaysPastDueNotWorse
这三个特征和目标变量有较强的相关性
corr = training_data.corr()
xticks = ['x0', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10']
yticks = list(corr.index)
figure = plt.figure()
ax1 = figure.add_subplot(1, 1, 1)
sns.heatmap(corr, annot=True, cmap='rainbow', ax=ax1, annot_kws={'size': 10, 'color': 'blue'})
ax1.set_xticklabels(xticks, rotation=0, fontsize=10)
ax1.set_yticklabels(yticks, rotation=0, fontsize=10)
plt.show()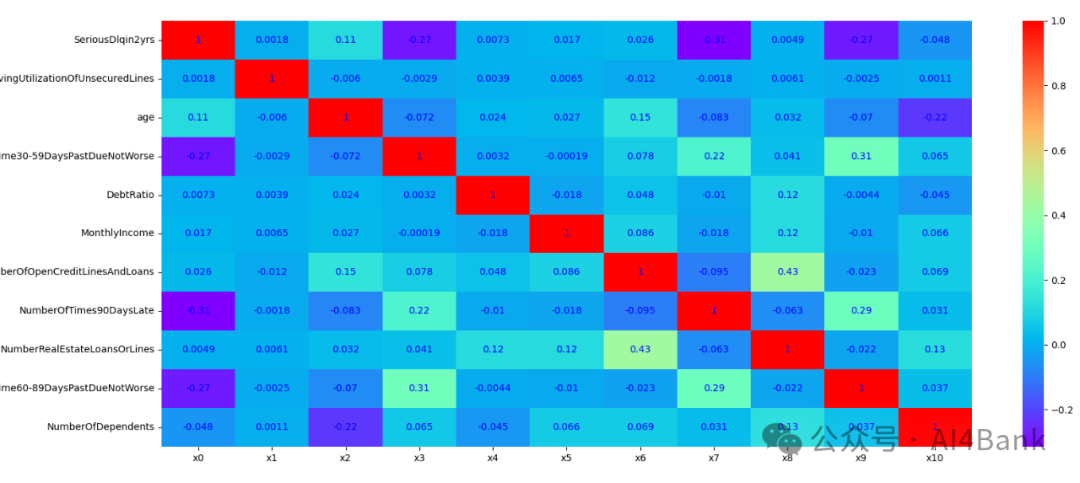
为了验证模型性能,将数据切分化为训练集和测试集,测试集取原数据的30%。这样基础的数据就准备好了。
# 特征变量和目标变量
X = training_data.iloc[:, 1:] # 特征变量,从第二列到最后一列
y = training_data.iloc[:, 0] # 目标变量,假设在第一列
# 分割数据为训练集和测试集 测试数据比例30%
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=0)二、数据分箱处理
建模之前,一般需要对特征变量进行离散化,特征离散化后,模型会更稳定,尤其是采用 logsitic 建立评分卡模型时,必须对连续变量进行离散化。而特征离散化处理通常采用的就是分箱法,数据分箱简单说就是对数据进行分组。类似将60分以下设置为不及格、60-75及格,76-85良好,86-100优秀。
定义自动分箱函数,基于IV(Information Value)和WOE(Weight of Evidence)两个指标来进行的。WOE是一种衡量某个分箱中好坏样本分布相对于总样本分布的指标。它通过对数转换来量化这种分布差异,使得WOE值能够直观地反映该分箱对于区分好坏样本的能力。IV则是基于WOE计算得出的一个汇总指标,用于衡量整个特征(经过分箱处理后)对于预测目标变量的信息量。IV值越高,说明该特征对于预测目标变量的贡献越大。
def mono_bin(target_y, target_x, n=10):
r = 0
good = target_y.sum()
bad = target_y.count() - good
while np.abs(r) < 1:
# 后面报错You can drop duplicate edges by setting the 'duplicates' kwarg,所以回到这里补充duplicates参数
# pd.qcut(X, n)表示平均分成n组,每组样例个数一致
d1 = pd.DataFrame({"X": target_x, "Y": target_y, "Bucket": pd.qcut(target_x, n, duplicates="drop")})
d2 = d1.groupby('Bucket', observed=True)
view_group(d2)
# 计算斯皮尔曼相关系数
r, p = stats.spearmanr(d2.mean().X, d2.mean().Y)
print("打印 r & p")
print(r)
print(p)
n = n - 1
d3 = pd.DataFrame()
d3['min'] = d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe'] = np.log((d3['rate']/good)/((1-d3['rate'])/bad))
d3['goodattr'] = d3['sum']/good
d3['badattr'] = (d3['total']-d3['sum'])/bad
iv = ((d3['goodattr'] - d3['badattr'])*d3['woe']).sum()
d4 = (d3.sort_values(by='min')).reset_index(drop=True)
woe = list(d4['woe'].round(3))
cut = []
cut.append(float('-inf'))
for i in range(1, n+1):
qua = target_x.quantile(i / (n + 1))
cut.append(round(qua, 4))
cut.append(float('inf'))
return d4, iv, cut, woe对RevolvingUtilizationOfUnsecuredLines、age、DebtRatio和MonthlyIncome四个特征使用自动分箱进行分类。
x1_d, x1_iv, x1_cut, x1_woe = mono_bin(train_y, train_X.RevolvingUtilizationOfUnsecuredLines, n=10)
x2_d,x2_iv, x2_cut, x2_woe = mono_bin(train_y, train_X.age, n=10)
x4_d,x4_iv, x4_cut, x4_woe = mono_bin(train_y, train_X.DebtRatio, n=20)
x5_d,x5_iv, x5_cut, x5_woe = mono_bin(train_y, train_X.MonthlyIncome, n=10)查看RevolvingUtilizationOfUnsecuredLines等四个变量数据分箱结果。
print("RevolvingUtilizationOfUnsecuredLines分箱结果:")
print("分布:\n", x1_d)
print("信息价值:", x1_iv)
print("分箱边界:", x1_cut)
print("权重证据:", x1_woe)
print("age分箱结果:")
print("分布:\n", x2_d)
print("信息价值:", x2_iv)
print("分箱边界:", x2_cut)
print("权重证据:", x2_woe)
print("DebtRatio分箱结果:")
print("分布:\n", x4_d)
print("信息价值:", x4_iv)
print("分箱边界:", x4_cut)
print("权重证据:", x4_woe)
print("MonthlyIncome分箱结果:")
print("分布:\n", x5_d)
print("信息价值:", x5_iv)
print("分箱边界:", x5_cut)
print("权重证据:", x5_woe)
RevolvingUtilizationOfUnsecuredLines分箱结果:
分布:
min max sum total rate woe goodattr badattr
0 0.000000 0.030330 25613 26078 0.982169 1.364035 0.262983 0.067226
1 0.030330 0.153982 25549 26078 0.979715 1.232583 0.262326 0.076478
2 0.153984 0.554850 24748 26077 0.949036 0.279535 0.254102 0.192135
3 0.554884 22198.000000 21484 26078 0.823836 -1.102225 0.220589 0.664161
信息价值: 1.0023316721381719
分箱边界: [-inf, 0.0303, 0.154, 0.5549, inf]
权重证据: [1.364, 1.233, 0.28, -1.102]
age分箱结果:
分布:
min max sum total rate woe goodattr badattr
0 21 33 10437 11748 0.888407 -0.570215 0.107163 0.189533
1 34 40 11365 12523 0.907530 -0.360938 0.116691 0.167414
2 41 45 10360 11299 0.916895 -0.243890 0.106372 0.135752
3 46 50 12005 13053 0.919712 -0.206343 0.123262 0.151511
4 51 54 9375 10117 0.926658 -0.108330 0.096258 0.107272
5 55 59 11369 12019 0.945919 0.216891 0.116732 0.093971
6 60 64 11431 11939 0.957450 0.468820 0.117369 0.073442
7 65 71 10242 10543 0.971450 0.882359 0.105160 0.043516
8 72 109 10810 11070 0.976513 1.082763 0.110992 0.037589
信息价值: 0.23886599687451782
分箱边界: [-inf, 33.0, 40.0, 45.0, 50.0, 54.0, 59.0, 64.0, 71.0, inf]
重证据: [-0.57, -0.361, -0.244, -0.206, -0.108, 0.217, 0.469, 0.882, 1.083]
DebtRatio分箱结果:
分布:
min max sum ... woe goodattr badattr
0 0.000000 0.241430 32728 ... 0.129519 0.336037 0.295215
1 0.241433 0.575269 32578 ... 0.053584 0.334497 0.317045
2 0.575274 329664.000000 32088 ... -0.162863 0.329466 0.387740
[3 rows x 8 columns]
信息价值: 0.01571318952535218
分箱边界: [-inf, 0.2414, 0.5753, inf]
权重证据: [0.13, 0.054, -0.163]
MonthlyIncome分箱结果:
分布:
min max sum total rate woe goodattr badattr
0 0.0 3901.0 23768 26081 0.911315 -0.314988 0.244040 0.334394
1 3902.0 5400.0 33993 36337 0.935493 0.029513 0.349026 0.338875
2 5401.0 7424.0 14798 15817 0.935576 0.030888 0.151940 0.147318
3 7425.0 3008750.0 24835 26076 0.952408 0.351554 0.254995 0.179413
信息价值: 0.05547386590422709
分箱边界: [-inf, 3901.0, 5400.0, 7424.0, inf]
权重证据: [-0.315, 0.03, 0.031, 0.352]
其他不能最优分箱的变量使用人工选择的方式进行,自定义分箱,同时计算WOE(Weight of Evidence)和 IV(Information Value)。
pinf = float('inf') # 正无穷大
ninf = float('-inf') # 负无穷大
cutx3 = [ninf, 0, 1, 3, 5, pinf]
cutx6 = [ninf, 1, 2, 3, 5, pinf]
cutx7 = [ninf, 0, 1, 3, 5, pinf]
cutx8 = [ninf, 0, 1, 2, 3, pinf]
cutx9 = [ninf, 0, 1, 3, pinf]
cutx10 = [ninf, 0, 1, 2, 3, 5, pinf]
def woe_value(d1):
return;NumberOfTime30-59DaysPastDueNotWorse人工分箱。
d1_x1 = d1.loc[(d1['Bucket'] <= 0)]
d1_x1.loc[:, 'Bucket'] = "(-inf,0]"
d1_x2 = d1.loc[(d1['Bucket'] > 0) & (d1['Bucket'] <= 1)]
d1_x2.loc[:, 'Bucket'] = "(0,1]"
d1_x3 = d1.loc[(d1['Bucket'] > 1) & (d1['Bucket'] <= 3)]
d1_x3.loc[:, 'Bucket'] = "(1,3]"
d1_x4 = d1.loc[(d1['Bucket'] > 3) & (d1['Bucket'] <= 5)]
d1_x4.loc[:, 'Bucket'] = "(3,5]"
d1_x5 = d1.loc[(d1['Bucket'] > 5)]
d1_x5.loc[:, 'Bucket'] = "(5,+inf)"
# 合并所有子集,将所有子集合并回一个DataFrame
d1 = pd.concat([d1_x1, d1_x2, d1_x3, d1_x4, d1_x5])
# 调用了woe_value函数,并传入了合并后的DataFrame d1。
# 返回每个桶的WOE值(x3_woe)、信息价值(IV,x3_iv)和其他描述性统计信息(x3_d)
x3_d, x3_iv, x3_woe = woe_value(d1)
# 定义桶的边界
# 定义了一个列表,它描述了Bucket列的数值范围边界。这些边界与前面为子集设置的字符串值相对应
x3_cut = [float('-inf'), 0, 1, 3, 5, float('+inf')]依次处理NumberOfOpenCreditLinesAndLoans,NumberOfTimes90DaysLate,NumberRealEstateLoansOrLines,NumberOfTime60-89DaysPastDueNotWorse,NumberOfDependents。
# 与上面类似,这里列出部分代码
x6_d, x6_iv, x6_woe = woe_value(d1)
x6_cut = [float('-inf'), 1, 2, 3, 5, float('+inf')]
x7_d, x7_iv, x7_woe = woe_value(d1)
x7_cut = [float('-inf'), 0, 1, 3, 5, float('+inf')]
x8_d, x8_iv, x8_woe = woe_value(d1)
x8_cut = [float('-inf'), 0, 1, 2, 3, float('+inf')]
x9_d, x9_iv, x9_woe = woe_value(d1)
x9_cut = [float('-inf'), 0, 1, 3, float('+inf')]
x10_d, x10_iv, x10_woe = woe_value(d1)
x10_cut = [float('-inf'), 0, 1, 2, 3, 5, float('+inf')]根据各变量的IV值来选择效果较好的变量。
informationValue = []
informationValue.append(x1_iv)
informationValue.append(x2_iv)
informationValue.append(x3_iv)
informationValue.append(x4_iv)
informationValue.append(x5_iv)
informationValue.append(x6_iv)
informationValue.append(x7_iv)
informationValue.append(x8_iv)
informationValue.append(x9_iv)
informationValue.append(x10_iv)
print(informationValue)
index = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10']
index_num = range(len(index))
ax = plt.bar(index_num, informationValue, tick_label=index)
plt.show()图形如下。
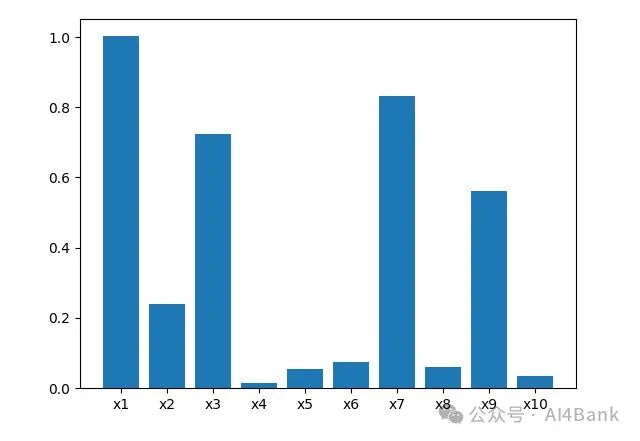
IV值判断变量预测能力的标准。
< 0.02: unpredictive
0.02 to 0.1: weak
0.1 to 0.3: medium
0.3 to 0.5: strong
> 0.5: suspicious对于X4,X5,X6,X8,以及X10而言,IV值都比较低,因此可以舍弃这些预测能力较差的特征,只选择X1,X2,X3,X7,X9。
三、WOE化数据
我们现在已经有了我们的箱子,接下来我们要做的是计算各箱的WOE,并且把WOE替换到我们的原始数据中,因为我们将使用WOE后的数据来建模,我们希望获取的是”各个箱”的分类结果,即评分卡上各个评分项目的分类结果。
def trans_woe(var, var_name, x_woe, x_cut):
woe_name = var_name + '_woe'
for i in range(len(x_woe)):
if i == 0:
var.loc[(var[var_name] <= x_cut[i + 1]), woe_name] = x_woe[i]
elif (i > 0) and (i <= len(x_woe) - 2):
var.loc[((var[var_name] > x_cut[i]) & (var[var_name] <= x_cut[i + 1])), woe_name] = x_woe[i]
else:
var.loc[(var[var_name] > x_cut[len(x_woe) - 1]), woe_name] = x_woe[len(x_woe) - 1]
return var
# 仅保留WOE转码后的变量
x1_name = 'RevolvingUtilizationOfUnsecuredLines'
x2_name = 'age'
x3_name = 'NumberOfTime30-59DaysPastDueNotWorse'
x7_name = 'NumberOfTimes90DaysLate'
x9_name = 'NumberOfTime60-89DaysPastDueNotWorse'
train_X = trans_woe(train_X, x1_name, x1_woe, x1_cut)
train_X = trans_woe(train_X, x2_name, x2_woe, x2_cut)
train_X = trans_woe(train_X, x3_name, x3_woe, x3_cut)
train_X = trans_woe(train_X, x7_name, x7_woe, x7_cut)
train_X = trans_woe(train_X, x9_name, x9_woe, x9_cut)
train_X = train_X.iloc[:,-5:]四、建模和验证
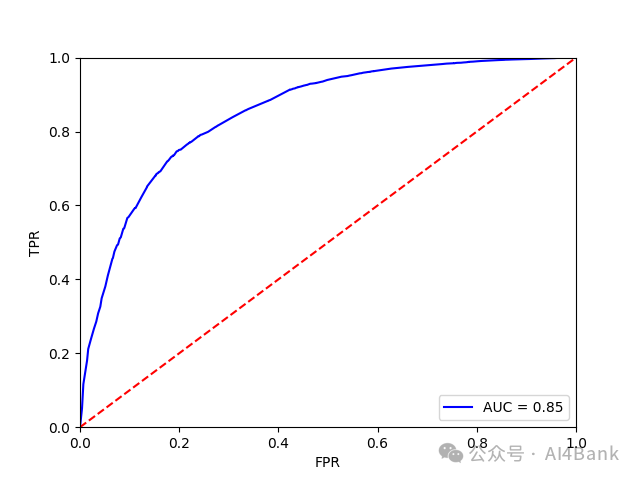
我们使用前面学习的逻辑回归模型(银行人从零开始学大模型(二):逻辑回归模型)。模型建立后,导入测试集的数据,画出ROC曲线判断模型的准确性。
调用STATSMODEL包来建立逻辑回归模型
X1 = sm.add_constant(train_X)
# 使用train_y(训练数据的标签)和X1(带有常数项的特征矩阵)来创建一个逻辑回归模型实例
logit = sm.Logit(train_y, X1)
# 拟合模型
# fit()方法执行了最大似然估计来估计模型的参数(包括截距和系数)
result = logit.fit()
# 打印出模型的摘要,包括每个系数的估计值、标准误差、z值、p值以及模型的R-squared值、对数似然值等信息
print(result.summary())
# 导入测试集的数据,画出ROC曲线判断模型的准确性
# 对测试集进行woe转化
test_X = trans_woe(test_X, x1_name, x1_woe, x1_cut)
test_X = trans_woe(test_X, x2_name, x2_woe, x2_cut)
test_X = trans_woe(test_X, x3_name, x3_woe, x3_cut)
test_X = trans_woe(test_X, x7_name, x7_woe, x7_cut)
test_X = trans_woe(test_X, x9_name, x9_woe, x9_cut)
test_X = test_X.iloc[:, -5:]
# 拟合模型,画ROC曲线,AUC=0.85,效果较好
X3 = sm.add_constant(test_X)
resu = result.predict(X3)
fpr, tpr, threshold = metrics.roc_curve(test_y, resu)
rocauc = metrics.auc(fpr, tpr)
plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('TPR')
plt.xlabel('FPR')
plt.show()
Optimization terminated successfully.
Current function value: 0.185077
Iterations 8
Logit Regression Results
==============================================================================
Dep. Variable: SeriousDlqin2yrs No. Observations: 104311
Model: Logit Df Residuals: 104305
Method: MLE Df Model: 5
Date: Tue, 20 Aug 2024 Pseudo R-squ.: 0.2415
Time: 10:25:24 Log-Likelihood: -19306.
converged: True LL-Null: -25451.
Covariance Type: nonrobust LLR p-value: 0.000
============================================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------------------------------
const 2.6187 0.015 173.518 0.000 2.589 2.648
RevolvingUtilizationOfUnsecuredLines_woe 0.6454 0.015 42.155 0.000 0.615 0.675
age_woe 0.4871 0.032 15.098 0.000 0.424 0.550
NumberOfTime30-59DaysPastDueNotWorse_woe 0.5436 0.015 35.239 0.000 0.513 0.574
NumberOfTimes90DaysLate_woe 0.5605 0.013 41.736 0.000 0.534 0.587
NumberOfTime60-89DaysPastDueNotWorse_woe 0.4168 0.017 24.606 0.000 0.384 0.450
============================================================================================================大家记住上面的coef系数,后面会用到。
五、建立评分卡
我们将Logistic模型转换为标准评分卡的形式。
Score = p + q * log(odds)log(odds),对数几率即逻辑回购模型中的截距,lr.coef常数。p和q为常熟,p是补偿,p是刻度。在建立标准评分卡之前,需要选取几个评分卡参数:基础分值、 PDO(比率翻倍的分值)和好坏比。PDO为20 (每高20分好坏比翻一倍)。定义 p 和 q,设1/60的对数几率时指定分数为600,pdo=20,那么1/30的对数几率则为620。
600 = p + q*log(1/60)620 = p + q*log(1/30)
计算得到p和q分别如下:
p = 600 - 20 * np.log(60) / np.log(2)q = 20 / np.log(2)
计算基础分值,得到557分。
x_coe = [2.6187, 0.6454, 0.4871, 0.5436, 0.5605, 0.4168]# 计算基础分数 baseScore 557baseScore = round(p + q * x_coe[0], 0)print(baseScore)
计算每个分箱区间的输入数据对应的“+”或“-”分数。
# 定义 get_score 函数,计算每个分箱区间的输入对应的分数
def get_score(coe, woe, factor):
scores = []
for w in woe:
score_1 = round(coe * w * factor, 0)
scores.append(score_1)
return scores
x1_score = get_score(x_coe[1], x1_woe, q)
x2_score = get_score(x_coe[2], x2_woe, q)
x3_score = get_score(x_coe[3], x3_woe, q)
x7_score = get_score(x_coe[4], x7_woe, q)
x9_score = get_score(x_coe[5], x9_woe, q)
print(x1_score, x2_score, x3_score, x7_score, x9_score)得到不同分箱具体分数如下:
score = [[25.0, 23.0, 5.0, -21.0],
[-8.0, -5.0, -3.0, -3.0, -2.0, 3.0, 7.0, 12.0, 15.0],
[8.0, -14.0, -27.0, -37.0, -42.0],
[6.0, -32.0, -44.0, -55.0, -52.0],
[3.0, -22.0, -32.0, -39.0]]建立自动评分计算能力。
# 建立自动评分函数,使得当输入x1,x2,x3,x7,x9的值时可以返回评分数
cut_t = [x1_cut, x2_cut, x3_cut, x7_cut, x9_cut]
# 建立查找表,计算具体分数
# 输入数据区间:[[-inf, 0.0303, 0.154, 0.5549, inf],
# [-inf, 33.0, 40.0, 45.0, 50.0, 54.0, 59.0, 64.0, 71.0, inf]
# [-inf, 0, 1, 3, 5, inf],
# [-inf, 0, 1, 3, 5, inf],
# [-inf, 0, 1, 3, inf]]
# 对应分数段:[[25.0, 23.0, 5.0, -21.0]
# [-8.0, -5.0, -3.0, -3.0, -2.0, 3.0, 7.0, 12.0, 15.0]
# [8.0, -14.0, -27.0, -37.0, -42.0]
# [6.0, -32.0, -44.0, -55.0, -52.0]
# [3.0, -22.0, -32.0, -39.0]]
def compute_score(x):
tot_score = baseScore
cut_d = copy.deepcopy(cut_t)
for j in range(len(cut_d)):
cut_d[j].append(x[j])
cut_d[j].sort()
for i in range(len(cut_d[j])):
if cut_d[j][i] == x[j]:
tot_score = score[j][i-1] + tot_score # 每个分箱区间对应的分数加上基础分即总分数
return tot_score评分卡示意如下:
| 变量 | 分段 | 得分 |
| 基础分 | 557 | |
| 借款人 年龄 | <=33 | -8 |
| (33,40] | -5 | |
| ... |
简单测试数据:
sample = [0.3, 44, 3, 3, 5]
print(compute_score(sample)) # 357分以上是逻辑回归在零售信贷或消费信贷中的具体应用,了解整个数据加工、建模、设计评分卡、自动计算调用评分模型的过程中各个节点的具体工作,尤其是数据清洗和加工,是模型开发中非常重要和繁琐的工作。当然,本模型开发过程还有很多优化的内容,比如好坏客户数据不平衡问题、空数据填充、数据分箱技术等,有兴趣的可以进一步研究。

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











