







什么是推荐?
推荐,就是根据个人偏好,对某个人进行个性化推荐。
- 在线购物的商品推荐
- 热门网站的推荐
- 音乐推荐
- 电影、电视的推荐
通常,我们会询问朋友有什么好看的电影,当然正常人都会询问和自己有着相同爱好的人。那么有一种算法叫做协同过滤:就是找到和目标用户有着相同爱好的人,然推荐给目标用户,这些有相同爱好的人喜欢的物品。本文主要就是讲这个算法。
推荐电影的例子
下面,我们通过一个实际的小例子来完成这个过程,这个例子是关于用户电影的。
用户的历史操作
#一个字典,第一个key是人名,value是又是一个字典,字典里面是key电影名,value是评分
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}用数字来代表行为是一个非常关键的手段。这样才编程的进行运行,如下图所示:
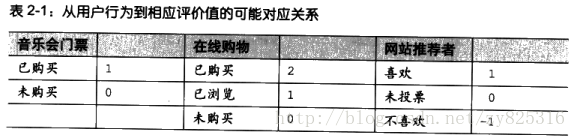
基于用户的协同过滤
协同过滤:就是找到和目标用户有着相同爱好的人,然推荐给目标用户,这些有相同爱好的人喜欢的物品。本文主要就是讲这个算法。
计算用户相似度
那么现在我们已经有了用户数据了,下一步就是:找出爱好相同的用户。专业术语:寻找相近用户或者相似度高的用户。下面介绍三种计算相似度的体系:
- 欧几里得距离
- 皮尔逊相关度
- Tanimoto系数
欧几里得距离
实际上,欧几里得距离非常直观,对于某两部电影,所有的用户都对其有着评分,我们以一个电影为x轴、一个电影为y轴,将每个人的对两个电影的评分画在坐标系中,直接考察每对用户的直线距离,距离近的相似度高。比如电影:dupree和snake,可以画出的图如下所示:

虽然这幅图只使用了二维坐标系,但实际上三维、四维都是同样的道理。
求两点间直线的距离,我相信大家都知道怎么算吧?三维、四维、n维的其实和二维的一个道理,都是两点差的平方和,再开方。注意:两点是指两个用户。在二维中就有x,y轴两个差值的平方和,而在n维中,就是n个差值的平方和。在本题中,对于两用户,必须是共同评过分的电影才有计算的意义。求出平方和再开方就是直线距离了。现在两用户越相邻距离越小,但是我们希望得到的是用户越相邻,数值越大,(0-1之间),故我们对最后的结果加1再求倒数就可以了。试想:如果两点重合,距离为1,再求倒数则是0被除,所以必须要加一。而如果两点距离越远,求倒数后值越小,符合我们的要求。解释清楚之后,让我们来看一看代码:
from math import sqrt
#利用欧几里得计算两个人之间的相似度
def sim_distance(prefs,person1,person2):
#首先把这个两个用户共同拥有评过分电影给找出来,方法是建立一个字典,字典的key电影名字,电影的值就是1
si={}
for item in prefs[person1]:
if item in prefs[person2]:
si[item]=1
#如果亮着没有共同之处
if len(si)==0:return 0
#计算所有差值的平方和
sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2) for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sqrt(sum_of_squares))
print sim_distance(critics,'Lisa Rose','Claudia Puig')最后一句代码可以计算两个实例。
皮尔逊相关度评价

图中superman电影的坐标为(3.0,5.0),这是因为用户Gene Seymour对其的评分为5,而mick lasalle的评分为3.考虑所有的点:我们画一条线,叫最佳拟合线:画的原则是尽可能地靠近图中所有的坐标点。就是上图的线,试想一种情况就是两个用户的评分完成一样,我们将得到一条线:所有点都在线上,而且线的角度是45度。这时,两个用户的兴趣完全相同,我们称之为1,我想别的拟合线与之对比即可看出差距吧。
我来看一种情况较好的时候:上图的相关系数为0.4,下图为0.75

公式如下:其中X和Y分别是个数相同的数组或者是列表(python),相当于算出了两个数组之间的perason相关度。
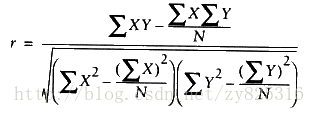
请看代码:
#返回两个人的皮尔逊相关系数
def sim_pearson(prefs,p1,p2):
si={}
for item in prefs[p1]:
if item in prefs[p2]: si[item]=1
#得到列表元素的个数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4552
4552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









