







首先从sklearn里面载入iris数据集
如下所示
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2[150 rows x 5 columns]
可以看到有4列为特征,最后一列为类别
这里为了画图方便仅使用了Sepal_Length 和Petal_Width 两列

可以看到特征和结果相关性挺高的
假如没有标签,看起来可以用kmeans解决,最后用kmeans看能不能得到类似的一个结果
# -*- coding: utf-8 -*-
import glob
from collections import defaultdict
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
def plot_scatter(df, name, centers=None, title=None):
'''
画图
'''
plt.figure()
plt.scatter(df['Sepal_Length'], df['Petal_Width'], c=df['Species'])
plt.xlabel('Sepal_Length')
plt.ylabel('Petal_Width')
plt.legend()
if centers:
plt.scatter([i[0] for i in centers], [i[1] for i in centers], c='r')
if title:
plt.title(title)
plt.savefig(name)
def distance(point_a, point_b):
'''
欧氏距离计算
'''
return np.sqrt(sum((np.array(point_a) - np.array(point_b)) ** 2))
def k_means(points, k):
centers = [points[i] for i in range(k)]
dict_ = []
iter_num = 0
while True:
point_dict = defaultdict(list)
for point in points:
distances = [distance(center, point) for center in centers]
class_ = np.argmin(distances)
dict_.append({'Sepal_Length': point[0], 'Petal_Width': point[1], 'Species': class_}, )
point_dict[class_].append(point)
print({k: len(v) for k, v in point_dict.items()})
new_centers = [np.array(points).mean(axis=0) for class_, points in point_dict.items()]
dis = (np.array(new_centers) - centers)
if abs(dis.mean()) <= 0.0002:
break
else:
centers = new_centers
plot_scatter(pd.DataFrame(dict_), f'kmeans_{iter_num}.png', centers, iter_num)
iter_num += 1
def png2jif():
'''
迭代生成的png转为动图
'''
file_names = glob.glob('*.png')
from PIL import Image
im = Image.open(file_names[0])
images = []
for file_name in file_names[1:]:
images.append(Image.open(file_name))
im.save('gif.gif', save_all=True, append_images=images, loop=1, duration=500, comment=b"aaabb")
def get_iris_df():
iris = load_iris()
iris_d = pd.DataFrame(iris['data'], columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_d['Species'] = iris.target
iris_d.dropna(inplace=True)
return iris_d
if __name__ == '__main__':
iris_df = get_iris_df()
plot_scatter(iris_df, 'raw.png')
print(iris_df)
points = iris_df[['Sepal_Length', 'Petal_Width']].values
k = 3
k_means(points, k)
png2jif()
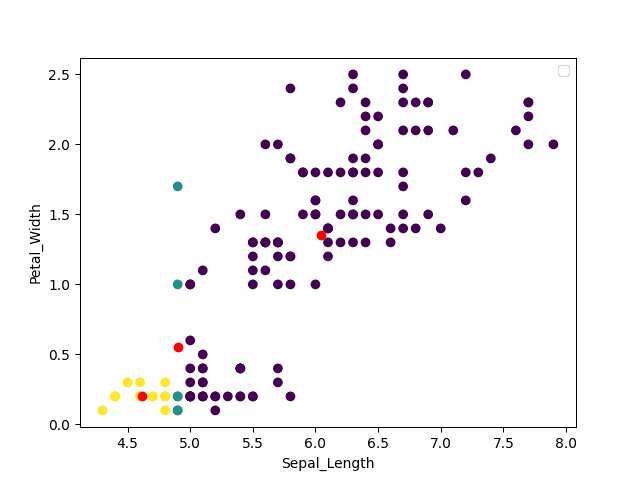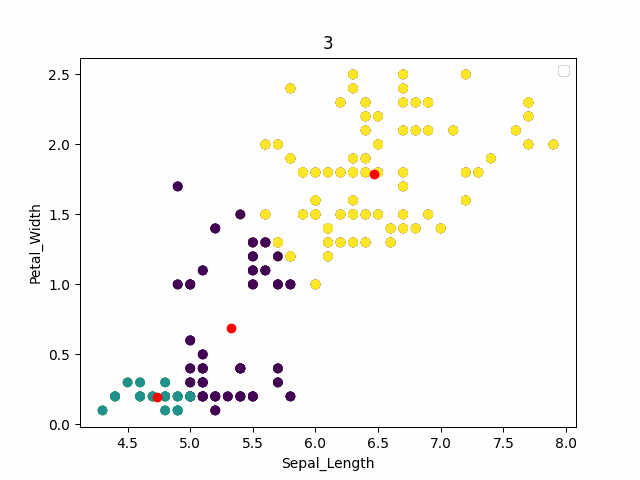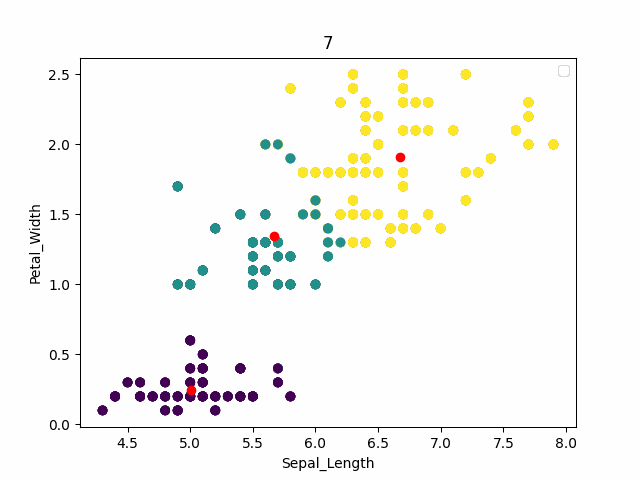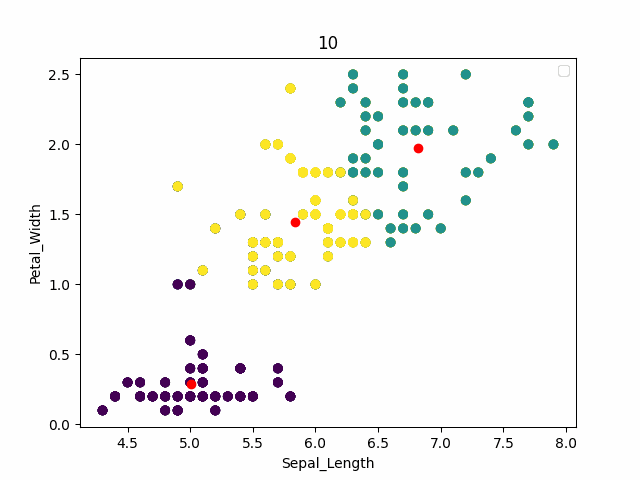
红色为中心点,可以看到通过kmeans可以得到一个和原始结果相近的一个结果















 5291
5291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









