






今天给大家带来爬虫的简单实例教程。
大家肯定有在网上下载图片的经历,遇到自己喜欢的图片,就想要保存下来,大家会怎么下载,是鼠标右键菜单保存图片吗?
图片一两张还好,但是如果有很多张,那这种操作就显得费手了。所以这里带来一篇python爬虫的实例,只要三个步骤,通过这里的学习,你可以掌握图片的批量下载而且可以根据自己的喜好,搜索下载自己需要的图片。
首先,我们来设置python的运行环境,去下载并安装python,window用户浏览器打开https://www.python.org/downloads/windows/,打开页面如下:
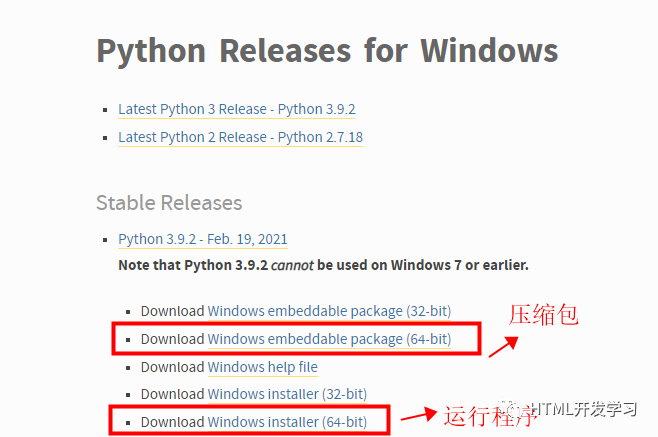
根据自己电脑选择64位或者32位,以64位为例,上面的是整个压缩包,需要解压,下面的是安装的运行程序,下载后点击直接安装,两个都可以,下载压缩包解压后找到python.exe,双击运行,然后一路点击下一步就好,完成安装,然后再来验证有没有安装成功,window用户按window+R键,输入cmd,打开命令行窗口,输入python -V查看python的版本,如果有版本出现则安装成功,否则再重新安装一遍,MAC用户可以省略,MAC自带python运行环境。
接下来,我们来找图片资源,以百度为例,我们打开百度,搜索表情包,再点击百度图片进入图片页面,如图:

然后,按F12打开开发者模式,然后,再点击一次搜索,然后按下图一次点击操作,
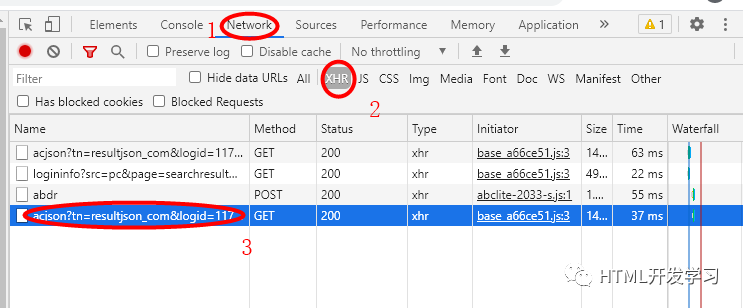
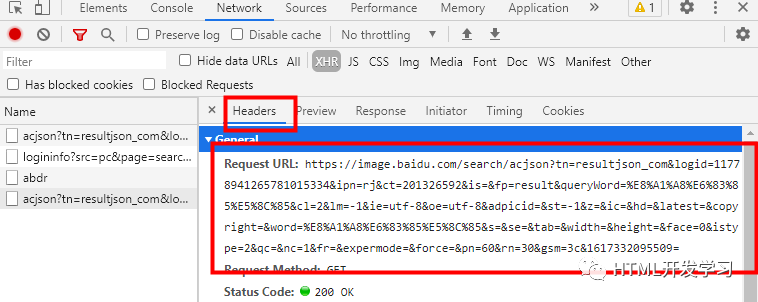
然后,可以看到,并点击Headers,找到Request URL,这个就是我们需要的图片请求地址,把https这段保存下来,然后要稍微处理一下,在记事本中保存然后找到&queryWord=%E8%A1%A8%E6%83%85%E5%8C%85&和&word=%E8%A1%A8%E6%83%85%E5%8C%85&,把=和&之间的这段替换掉:'+ss+',即&queryWord='+ss+'&和&word='+ss+'&。
然后,我们来写代码,桌面打开记事本,复制下面代码并保存:
import requestsimport osfrom urllib import parseimport jsonss = parse.quote('表情包')uu = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=11546144348521348843&ipn=rj&ct=201326592&is=&fp=result&queryWord='+ss+'&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word='+ss+'&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1614927275508='print(uu)kv = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36"}response = requests.get(uu, headers = kv, allow_redirects=False)arr = (response.json())['data']print(arr)for item in arr:#img = item.get('middleURL')#print(item)img = item['middleURL']imgUrl = imgprint(imgUrl)root = "./Pic/表情包/" #保存的路径path = root + str(item.get('fromPageTitleEnc'))+'.jpg' #获取img的文件名try:if not os.path.exists(root): #判断是否存在文件并下载imgos.mkdir(root)if not os.path.exists(path):read = requests.get(imgUrl).contentwith open(path, "wb")as f:f.write(read)f.close()print("文件保存成功!")else:print("文件已存在!")except:print("文件爬取失败!")
上面这段代码,uu后面的就是我们在上一步中得到的请求处理好地址,然后代码中ss等号后面的括号里填写我们想要搜索图片的关键词,保存好后我们再来修改下文件名,为getPic.py,后缀一定是py。
最后,我们来运行代码,以window用户为例,window+R输入cmd打开命令行,输入cd Desktop回车,输入py getPic.py回车,就可以在命令行看到图片下载的情况,
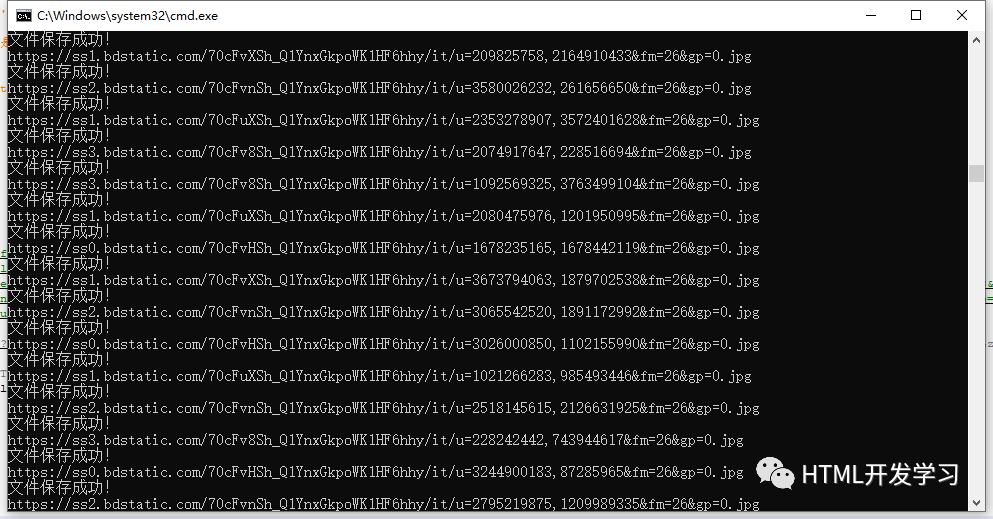
命令行停止响应后,即完成下载,然后你会在桌面发现多了一个文件夹Pic,里面有个表情包的文件夹,这里就是我们在百度上爬取下来的表情包的图片了。大家也可以搜索其他关键词,例如:小姐姐等 。
。
如果你想爬取其他网站的图片,也是可以的从第二步开始,先找请求路径,然后把代码中的uu替换掉就好了,大家赶紧试试吧。
以上内容来自微信公众号 ‘HTML开发学习’,会分享一些前端的学习心得及总结,欢迎大家关注。
















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









