







摘要
开放世界目标检测(OWOD)是一项新颖而具有挑战性的计算机视觉任务,可以实现对未知目标的检测。现有方法通常通过额外的目标性分支来估计目标的可能性,但忽略了在语义空间和训练目标上互相对立的目标性和分类边界的冲突。为了解决这个问题,我们提出了一种简单而有效的学习策略,即解耦目标性学习(DOL),它将这两个边界的学习分为合适的解码器层。此外,全面检测未知对象需要大量的注释,但标记所有未知对象既困难又昂贵。因此,我们建议利用最近的大视觉模型(LVM),特别是分割任意模型(SAM),来增强对未知对象的检测。然而,SAM的输出结果包含噪音,包括背景和碎片,因此我们引入了一个辅助监督框架(ASF),使用伪标记和软加权策略来减轻噪音的负面影响。对包括Pascal VOC和MS COCO在内的常见基准进行的大量实验表明了我们方法的有效性。我们提出的未知敏感检测器(USD)在未知回忆率方面优于最近的最先进方法,在M-OWODB上实现了14.3%、15.5%和8.9%的显着改进,在S-OWODB上实现了27.1%、29.1%和25.1%的显着改进。
1. 引言
目标检测(OD)是一项关键的计算机视觉任务,对自动驾驶 [26, 20]、智能医疗 [8, 16] 和智能机器人 [1, 14] 等各个领域都具有重要意义。然而,传统的目标检测方法主要是在封闭集环境下设计和评估的,这极大地限制了它们在实际场景中的适用性。封闭集目标检测方法存在几个局限,例如倾向于将未知对象误分类为已知对象、无法检测未知对象以及随着图像和标签数量增加而无法增量学习。为了解决这些挑战,出现了一个更为严峻的任务,称为开放世界目标检测(OWOD)。在OWOD中,模型不仅需要识别数据集中定义的已知类别的对象,还需要识别潜在的未知对象,即以前未见过的对象。然后,检测到的未知对象被呈现给一个 Oracle,通常是一个人类标注者,他们会标记一些感兴趣的对象。随后,新标记的数据被纳入增量学习范式中,使模型能够快速学习和适应新类别,同时减轻对先前学习类别的灾难性遗忘。
无疑,在OWOD任务的背景下,未知对象的检测具有极其重要的意义。然而,未知对象缺乏标签的情况经常导致它们在训练阶段被误分类为背景,从而导致未知对象的低召回率。为了克服这个问题,现有的OWOD方法已经加入了额外的目标性分支,以区分未知对象和背景。例如,在[15, 7, 22]中,采用了基于能量分数的分类器来区分已知对象和未知对象。在[11, 35, 25, 39]中,采用了伪标记策略,选择置信度较高的前k个区域作为伪标签,以监督目标性分支的训练。在最近的PROB研究中[44],提出了一个两阶段的方法,第一阶段开发了一个目标性概率模型来区分前景和背景,然后在第二阶段训练了一个分类模型来区分具体的类别。值得注意的是,概率模型是在没有负样本的情况下训练的,避免了未知对象和背景之间的混淆。然而,这些方法并没有充分解决学习目标性和分类边界之间的冲突。此外,注释的可用性在未知对象检测的性能中起着关键作用,因为只有在对象得到充分注释时,检测器才能全面检测未知对象。
学习目标性和分类边界的挑战源于语义流形和训练目标之间的固有冲突。目标性边界需要低级语义来全面检测对象,而分类边界依赖于高级语义来准确将对象分类到特定类别。此外,目标性边界旨在最小化已知对象之间的距离,而分类边界旨在最大化不同对象类之间的距离。为了解决这两个主要冲突,我们提出了一种简单而有效的学习策略,称为解耦目标性学习(DOL),通过将这两个边界的学习分开到不同的解码器层来解决这一冲突。具体地,我们将目标性的学习分配给第一个解码器层,它作为一个与类别无关的分类器。随后,其余的解码器层用于细化定位并执行特定类别的分类。通过解耦目标性和分类边界的学习,目标性和分类的特性得到充分释放。
在开发OWOD时面临的另一个挑战是未知对象的有限注释。显然,标记更多的未知对象将扩展检测器检测更广泛对象的能力。然而,由于难以将未知对象与背景区分开来,因此标注未知对象具有挑战性。为了克服这一挑战,我们提出利用大型视觉模型(LVMs)[29, 21, 18, 45]的零样本和开放世界能力,而无需人工注释。具体地,我们利用了最近提出的Segment Anything Model(SAM)[18],它在大规模数据的帮助下可以实现出色的类别无关定位性能。然而,SAM的输出可能包含包含背景和碎片的区域,这可能对未知对象的检测产生不利影响。为了解决这个问题,我们引入了一个辅助监督框架(ASF),它利用目标性分数和预测框与SAM输出框之间的交并比(IoU)作为可靠的指标来过滤噪声。随后,我们利用这些经过滤的未知伪标签作为辅助监督,促进未知对象检测的学习过程,从而实现对未知对象的更全面检测。
总的来说,我们的主要贡献可以概括如下:
- 我们引入了一种简单而有效的学习策略,以解决学习物体性和分类边界之间的固有冲突,提高了已知和未知物体的检测能力,而不会产生额外的成本。
- 我们是首个提出利用SAM的零样本和开放世界能力来解决未知物体的注释困境的,实现了对未知物体的更全面的检测。
- 我们设计了一个通用的框架,有效地减轻了SAM输出中的噪声的负面影响,显著提高了已知和未知物体检测的性能。
- 通过对Pascal VOC和MS COCO数据集的两种广泛使用的数据划分的严格评估,我们提出的方法在未知召回方面取得了显著的改进,树立了OWOD任务的新的最先进水平。
相关工作
2.1 Open-World Object Detection
开放世界物体检测旨在解决传统物体检测中的封闭集和静态学习设置的限制,最近由ORE [15]提出,已经引起了广泛的关注。它可以分为两个子任务,即已知和未知的物体检测,以及增量物体检测 [31, 36]。后者已经作为一个典型的增量学习任务被广泛研究 [41],而前者仍然处于OWOD特定任务的初级阶段。为了检测已知和未知的物体,需要学习两个分类边界:一个是区分物体和背景(即,物体性边界),另一个是将物体区分为特定类别(即,分类边界)。第二个边界的学习是开放集物体检测任务的目标,并且已经在许多工作中被研究 [40, 6, 12, 28],而第一个边界的学习是具有挑战性的,因为我们不能定义所有类别的物体,而且物体性是一个容易混淆的主观概念。类别不明确的物体检测 [27, 38, 17, 30] 是最相关的任务,它将所有的物体视为物体性类别,其他的视为背景类别。然而,它需要大量的数据来使检测更多的物体成为可能 [27, 17]。在OWOD中,关键的挑战是在保持检测已知物体的高精度的同时,全面地检测未知物体。ORE [15] 提出了一个基于能量的模型来识别已知和未知的物体。2B-OCD [34] 提出了一个额外的基于IoU的位置分支,用于更准确地估计物体性。UC-OWOD [35] 提出利用伪标签范式,选择过滤后的top-k潜在未知区域来训练物体性。最近,基于Transformer的方法在学习物体性方面显示出了巨大的潜力,OW-DETR [11] 首先将可变形的DETR [43] 模型适应到OWOD。它利用一个模型驱动的伪标签方案来监督未知物体性的学习。在此之后,CAT [25] 利用选择性搜索算法 [32] 生成类别不明确的辅助提议,产生高召回率的伪标签。另一方面,PROB [44] 提出了一种基于异常检测的方法,它不需要负例,从而避免了背景和未知物体之间的混淆。与上述方法不同,本文揭示了在学习物体性和分类边界时产生的冲突问题,并提出利用SAM来缓解OWOD中的注释困境。
2.2 Large Visual Model
大型语言模型(LLMs)[5, 2],如ChatGPT [3]的成功,展示了大规模模型的优越性和重要性。因此,研究社区对大型视觉模型(LVMs)给予了相当大的关注。例如,CLIP [29]已经成为一个关键的进步,它通过构建图像-文本对,弥合了自然语言处理(NLP)和计算机视觉(CV)领域之间的鸿沟,提供了一种模拟开放世界视觉空间的新颖解决方案,具有令人印象深刻的零样本和泛化能力。除了分类任务外,LVMs还扩展到了物体检测 [27, 10, 19] 和分割 [18, 45],在开放世界设置中取得了显著的性能改进。最近,Segment Anything Model (SAM) [18] 在开放环境中展示了强大的零样本分割能力,可以使用适当的提示(如点和框)来分割任何东西。值得注意的是,在SAM的“everything”模式中,它可以利用一个n × n的采样点网格覆盖整个图像,每个点生成一个掩膜来分割潜在的物体,这可以提供高召回率的辅助提议,使OWOD方法能够检测到更多的物体。然而,SAM的结果可能包含对未知物体检测有害的背景和碎片。本文通过利用伪标签和软加权策略来解决这个问题,减轻噪声的负面影响,同时仍然从SAM的高召回率未知提议中受益。
3.方法
我们提出了USD,它适应了DDETR [43] 模型用于开放世界物体检测,配合我们提出的分离的物体性学习策略和辅助监督框架。在第3.1节中,我们介绍了OWOD的问题,并简要概述了我们的基线方法PROB [44]。在第3.2节中,我们深入探讨了学习物体性和分类边界之间的固有冲突,并提出了我们的解决方案来缓解这个冲突。此外,在第3.3节中,我们展示了SAM输出中的噪声问题,并描述了我们的方法来减轻其负面影响。图1展示了USD的概览,这是一个基于变压器的开放世界检测器,具有强大的对未知物体的感知能力。
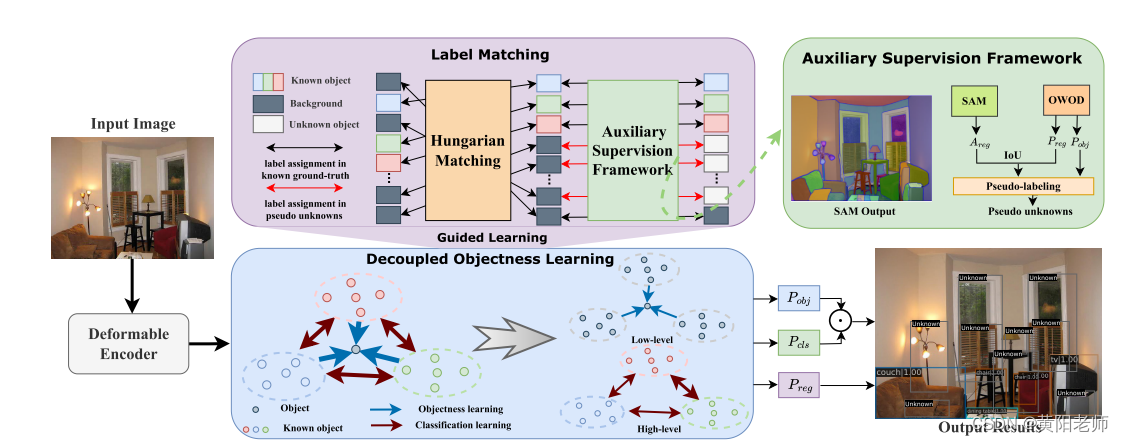
图1. 我们提出的方法基于DDETR [43],它有一个可变形的编码器和一个可变形的解码器。为了将DDETR适应到开放世界设置,我们提出了一个分离的物体性学习和一个辅助监督框架。分离的物体性学习策略将物体性和分类的学习分离到不同的解码器层。具体来说,第一解码器层模型的物体性得分,而剩余的解码器层预测分类和回归结果。辅助监督框架将伪标签方案与LVMs结合,这缓解了OWOD中的注释困境。
3.1 Preliminary
问题定义:在标准的物体检测中,给定一组已知的类别 K = { 1 , 2 , 3 , . . . , C } ∈ N + K = \{1, 2, 3, ..., C\} \in N^+ K={ 1,2,3,...,C}∈N+,以及相应的训练集 D t = { X t , Y t } Dt = \{Xt, Yt\} Dt={ Xt,Yt},包括图像X和相应的标签Y。每个图像 X i Xi Xi 包含多个特定类别的实例,其中一个实例被标记为类别 l i ∈ K li \in K li∈K 和边界框 b t i = { x t , y t , w t , h t } bt_i = \{xt, yt, wt, ht\} bti={ xt,yt,wt,ht},其中 { x t , y t } \{xt, yt\} { xt,yt} 表示中心坐标, w t wt wt 和 h t ht ht 分别表示宽度和高度。除了已知的类别,图像X也可能包含未知物体,其类别为 U = { C + 1 , C + 2 , . . . } U = \{C + 1, C + 2, ...\} U={ C+1,C+2,...}。
OWOD方法旨在检测潜在的未知物体,并将它们提供给一个预测器来注释新的类别,以便持续学习。在[15]的开创性工作的基础上,OWOD方法通常涉及一组顺序任务 T = { T 1 , T 2 , T 3 , T 4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2635
2635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











