









本文是Hinton大神在网络压缩与迁移学习方向挖的一个坑
原文链接Distilling the Knowledge in a Neural Network
这种方法感觉受到了ensemble的启发,利用大型(teacher net)网络提取先验知识,将这种先验知识作为soft target让微型网络(student network)学习,有点像Boost中第一个分类器学到后调整weight让第二个分类器学习。当然相似中也有不同之处
Introduction
主旨就是从复杂网络(teacher net)中抽取训练数据的分布‘教给’简易网络(student net)
- 复杂网络可以从
- ensmeble models 中学习
- 从单独的大型网络(使用正则项或dropout)中学习
复杂网络通常通过最大化log probability去学习多分类,这有个副作用是模型通常会赋予非正确答案一定的概率,即使这些概率都很小但是有一些是明显大于其他的(类似于softmax)。
- 通过复杂网络产生的分类概率分布作为soft target来训练小模型
在transfer的过程中(即cumbersome network转向small network的时候)可以使用同样的训练集也可以使用单独的训练集(猜想:可能使用不同的训练集的时候效果会更好;但是文中说使用原始数据集效果更好)
值得注意的是 对于Mnist数据集中总是产生具有信心的正确结果,很多非正确数字的概率都是非常小的,举个栗子,对于正确的2来说,被分类为3的概率为 10−6 被分类为7的概率为 10−9 。在这种情况下soft target的帮助就很小,所以Caruana在其文章中使用log函数解决这一问题。本文利用蒸馏解决这个问题(蒸馏会使得target变得更加soft)
Distillation(蒸馏)
加入蒸馏后的softmax函数:
这里T是超参数,文中说是‘温度’,经过该参数之后的softmax会更加平滑,分布更加均匀而大小关系不变。T参数在设置为1的时候就是平常的softmax函数。
在知识转换阶段,设置复杂网络与简易网络相同的T参数。在此之后再从新将T设置为1
根据这篇博客再加入T之后的softmax的概率分布更加平滑,作为soft target时简易(student)网络能学到更多东西
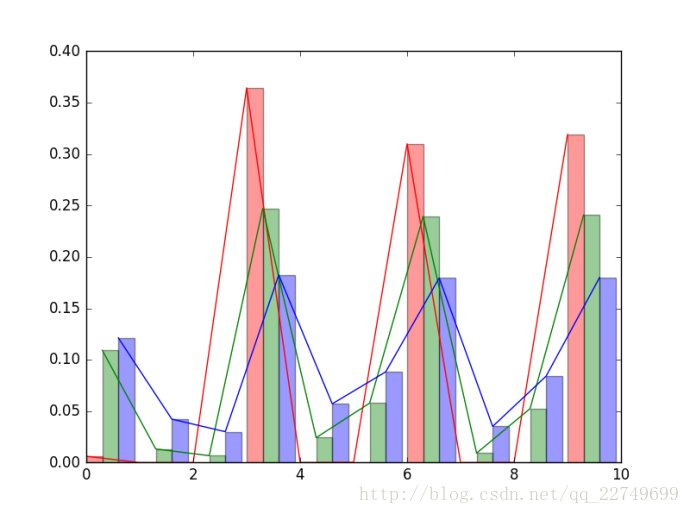
另外使用matlab做蒸馏
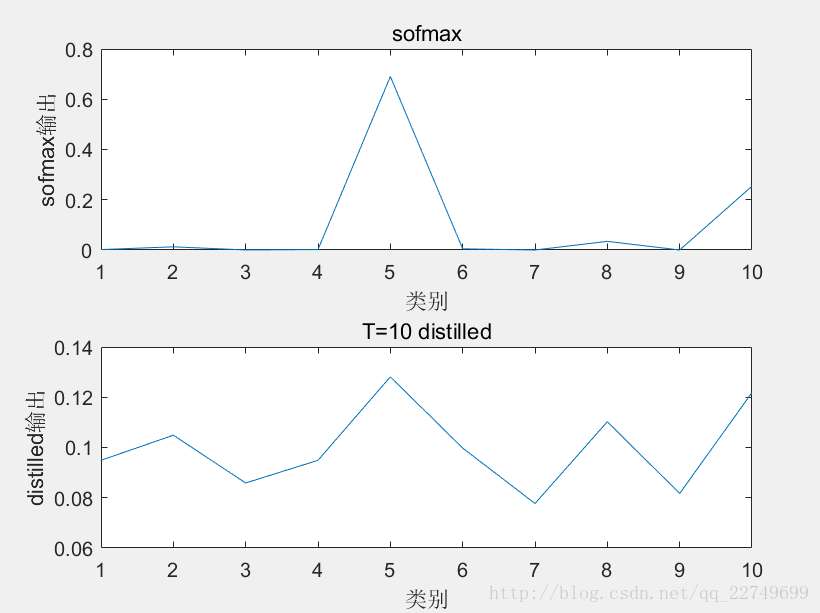
在hinton的slides中也可以看到更加平滑的概率slides

具体蒸馏结构如下图所示:
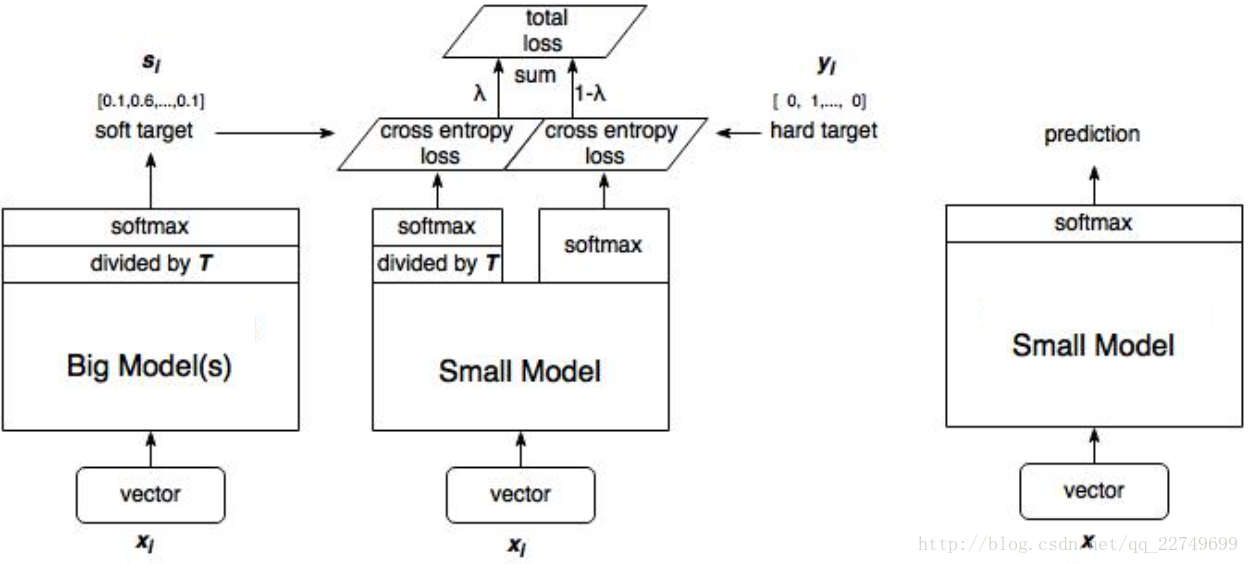
这里 λ 是hard target与soft target的权重
1、训练大模型:先用hard target,也就是正常的label训练大模型。
2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式(右图)使用。
这里参考
将hard target的参数设置的比较小可以得到较好的结果,在做梯度下降时需要将soft target的梯度乘以1/ T2 ,这是因为将梯度的规模保持与hard target一样
ditiliation在特殊情况下相当于logits
首先给出交叉上的求导公式
∂C∂zi=1T(qi−pi)=1T(eziT∑jezjT)−1T(eviT∑jevjT)(2)
其中 vi 是cumbersome model产生的logits vi 相当于真实分布, zi 是distilled model
公式推导:
qi=1T(eziT∑jezjT)(2.1)
pi=1T(eviT∑jevjT)(2.2)
cross entropy=−∑j pj×log qj(2.3)
对交叉熵求导即可得到公式(2)
并且作者给出当T非常大的时候distillation优化的目标等价于Caruana提取的对logits的平方误差求最优化
∂C∂zi≃1T(1+ziTN+∑jzjT)(1+viTN+∑jvjT)(3)
当我们假设logits是zero-means的则 ∑jzj=∑jvj=0
∂C∂zi≃1NT2(zi−vi)(4)
实验部分
初步试验 Mnist数据集
训练一个有两层具有1200个单元的隐藏层的大型网络(使用dropout和weight-constraints作为正则)值得注意的一点是dropout可以看做是share weights 的ensemble models
另外一个小一点的网络具有两层800个单元隐藏层没有正则
结果是第一个网络test error 67个,第二个是146个;再加入soft target并且T设置为20之后小型网络test error达到74个
另外需要注意一点的是:
When the distilled net had 300 or more units in each of its two hidden layers, all temperatures above 8 gave fairly similar results. But when this was radically reduced to 30 units per layer, temperatures in the range 2.5 to 4 worked significantly better than higher or lower temperatures.
该现象可能说明将概率设置的过于soften可能会导致一些问题尤其是在拟合能力较差的网络中
另外的重要发现
- 遗漏数据集所有的数字3做训练后,distilled model只有206个test error只有206 其中133是对3的辨识错误(测试集中3有1010个),很多错误是bias过低导致(?)到bias增加到3.5时distilled model 给了109个error,其中14个是3
- 训练集只有7和8时,distilled model有47.3%的测试错误,到bias降低7.6时优化了,降低了13.2%测试错误。
- 一个问题:这样手动修正bias增加正确率是否有普适的意义
剩下的就是在语音数据及的实验以及大型数据及JFT的实验。具体可以参考原文。

















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









