







目录
1.Label smoothing的原理
交叉熵损失(softmax cross Entropy)中,常用公式:
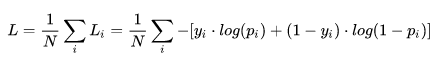
yi: 表示样本i的label,正类为1,负类为0;
pi:表示样本i预测为正类的概率;
Label Smothing:原来标签是1的位置变为1-a,其他原来是0的位置变为a/(K-1),a通常取0.1;
举个例子:
假设一个6分类任务,之前的标签y=【1,0,0,0,0,0】,经过a=0.1的smoothing 操作后,现在输入代码的标签变为了y=【0.9,0.02,0.02,0.02,0.02,0.02】;
2.pytorh中如何使用Label smoothing
在不加入Label smoothing这个技巧的时候,在pytorch中可以直接调用交叉熵loss:
import torch.nn as nn
criterion = nn.CrossEntropyLoss()在加入该技巧后,已经有别人写好的代码(调用fast-reid中的代码):
def cross_entropy_loss(pred_class_outputs, gt_classes, eps, alpha=0.2):
'''
pred_class_outputs:backbone输出结果,如16张数据,95个类别,通过fc后,则该参数维度为【16,95】
gt_classes:真实标签,如16张数据,则该参数维度为【16】
eps:通过判断该参数来决定使用常规的label smoothing,还是使用自适应的label smoothing
alpha:label smoothing的参数;
'''
num_classes = pred_class_outputs.size(1)
if eps >= 0:
smooth_param = eps
else:
# Adaptive label smooth regularization
soft_label = F.softmax(pred_class_outputs, dim=1)
smooth_param = alpha * soft_label[torch.arange(soft_label.size(0)), gt_classes].unsqueeze(1)
log_probs = F.log_softmax(pred_class_outputs, dim=1)
with torch.no_grad():
targets = torch.ones_like(log_probs) #torch.ones_like返回一个填充了标量值1的张量
targets *= smooth_param / (num_classes - 1)
targets.scatter_(1, gt_classes.data.unsqueeze(1), (1 - smooth_param)) #target.scatter(dim, index, src)其将一个源张量(source)中的值按照指定的轴方向(dim)和对应的位置关系(index)逐个填充到目标张量(target)中
loss = (-targets * log_probs).sum(dim=1)
with torch.no_grad():
non_zero_cnt = max(loss.nonzero(as_tuple=False).size(0), 1)
loss = loss.sum() / non_zero_cnt
return loss3.适用场景
label smoothing的作用主要是防止模型过拟合,加速模型收敛;
作者们亲测,label smoothing与mixup以及knowledge distillation一样,都是涨分的,模式识别、目标检测与语义分割,三大权威任务,不骗人。
相关论文:《Why dose smoothing help?》 https://arxiv.org/pdf/1906.02629.pdf
















 1872
1872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











