







改进的SSD的地方:
default box的长宽比进行修改(长条形),使其更适合文字检测(单词)
作为classifier的卷积滤波器大小从3*3变成1*5,更适合文字检测
SSD原来为多类检测问题,现在转为单类检测问题
从输入图像为单尺度变为多尺度
利用识别来调整检测的结果(text spotting)
网络结构
整个检测流程就是SSD+NMS,识别流程使用的CRNN。
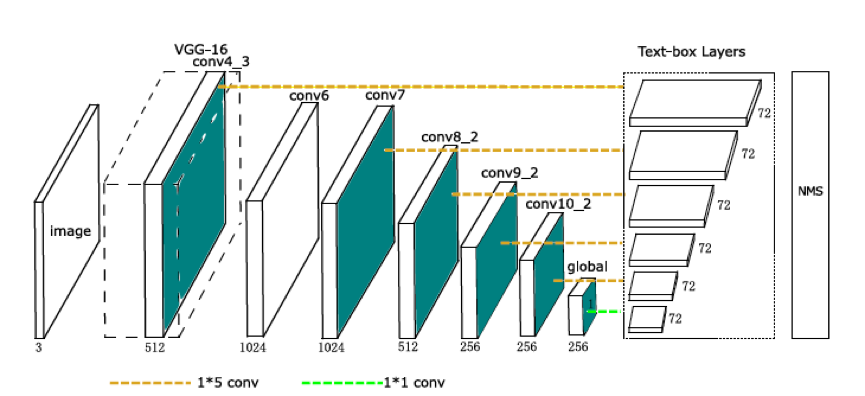
TextBoxes是一个28层的全连接卷积网络。其中13层是继承的VGG-16的网络结构,保留了vgg16的conv1_1到conv4_3的层,vgg16最后的全连接层转换成了参数下采样的卷积层,后面在了一些卷积核池化层,称为conv6到pool11层,额外的9个卷积层添加在VGG-16层之后,Text-box层连接着6个卷积层。在每一个特征位置,一个text-box预测72维向量,这是文本出现的得分(text presencescores)(2维)和12个默认盒子的偏移(offsets)(4层)。一个非最大抑制(NMS)用来聚合所有文本盒子(text-boxlayers)层的输出。
Text-box layers
Text-box层是TextBoxes的关键组件,一个text-box层同时预测文本存在和边界盒子(bounding boxes)。
在训练阶段,ground-truth单词盒子与default box根据boxoverlap对应。根据匹配规则,每一个图位置和多个不同大小的默认盒子对应。这样就高效的把单词分为不同的纵横比和比例,并且TextBoxes还可以学习特定的回归和分类权重来处理相似大小的单词。因此,default box的设计是与特定任务息息相关的。
和一般的物体不一样,单词往往有较大的纵横比。因此,我们设计了纵横比较大的default box。特别地,我们设计了6种不同纵横比率的默认盒子,分别是1,2,3,5,7和10.可是,这使得在水平方向上的default box密集而在垂直方向上的默认盒子变得稀疏,这会导致很差的matchingboxes。

上图为4*4网格的默认盒子的解释,为了更好的可视化,仅仅只有一列默认盒子的纵横比为1和5被描绘出来。剩下的纵横比是2,3,7,10,放的方法都是相似的。黑色(纵横比是5)和蓝色的(纵横比是1)默认盒子位于单元的中心位置。绿色的(纵横比是5)和红色的(纵横比是1)的盒子有相同的纵横比(same aspect ratios)和相对于网格中心的垂直偏移(verticaloffset)(偏移是该单元高的一半)。
另外,在text-box层,我们采取了非常规的1*5的滤波器,而没有采取3*3的滤波器。这种inception风格的滤波器产生矩形接受域(receptive fields),使得能适应大纵横比的单词,也避免了正方形接受域带来的噪声信号(noisysignals)。















 5354
5354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









