







态射:
一种数学结构映射到另一种数学结构所使用的一种规则。
拓扑空间:
是一个集合X和其上定义的拓扑结构τ组成的二元组(X,τ)。其中拓扑结构包括开集,闭集,邻域,开核,闭包等等子概念。
拓扑空间最为对象,连续映射作为态射构成了拓扑空间范畴:
X是一个集合,O是一些X的子集构成的族,则(X,O)构成一个拓扑空间的充分必要条件:
1.空集和X属于O
2.O中任意多个元素并集仍属于O
3.O中任意多个元素的交仍属于O
欧几里得空间:
设V是实数域R上的线性空间,若V上定义着正定对称双线性型g(g称为内积),则V称为对于g的欧几里德空间。 具体来说,g是V上的二元实值函数,满足如下关系:
(1)g(x,y)=g(y,x);
(2)g(x+y,z)=g(x,z)+g(y,z);
(3)g(kx,y)=kg(x,y);
(4)g(x,x)>=0,而且g(x,x)=0当且仅当x=0时成立。
这里x,y,z是V中任意向量,k是任意实数。
例子:
经典欧几里德空间E^n:在n维实向量空间R^n中定义内积(x,y)=x1y1+...+xnyn,则Rn为欧几里德空间。(事实上,任意一个n维欧几里德空间V等距同构于E^n。)
酉空间:
设V是复数域C上的线性空间,若对于V中任意两个向量x、y都有唯一确定的负数内积(x,y)与它们相对应,且满足:
共轭对称性(x,y)=(y,x) ;
可加性(x+y,z)=(x,z)+(y,z);
齐次性(k x,y)=k(x,y),k为任意复数;
非负性(x,x)≥ 0,当且仅当x=0时有(x,x)= 0.
定义了内积的复线性空间V,叫复内积空间即酉空间(有限维或无限维)。
凸函数:
f(x)在[a,b]上连续,在(a,b)内具有一阶和二阶导数,那么:
若在(a,b)内, >0,则f(x)在[a,b]上的图形是凹的;
>0,则f(x)在[a,b]上的图形是凹的;
若在(a,b)内,<0,则f(x)在[a,b]上的图形是凸的;
也可知: ,>0 则x为极小值点;,<0 则x为极大值点;,=0 则x为驻点。
,>0 则x为极小值点;,<0 则x为极大值点;,=0 则x为驻点。
定义一个集合  ,则对于任意的
,则对于任意的 。任意的
。任意的
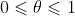 ,
,
有 则称为定义域上的凸函数。
则称为定义域上的凸函数。
常见的凸函数包括:指数函数,幂函数,负对数函数-logx,负熵函数xlogx,范数函数||x||。
标准场:
仅用其大小就可以完整的表征的场,一个标量场U可以用一个标量函数u(x,y,z)来表示,令u=(x,y,z)=C,其中C是常数,则该表达式在几何上表示一个曲面,曲面上个点坐标不同但是函数值相等构成等值面,随着C的不同构成一系列不同的等值面,对于二维同理构成了很多的u(x,y)的等值线。
标准场的方向导数:
设 为标量场u=u(p)中的一点,从出发引出一条射线l,在l上点附近去一点P,记
为标量场u=u(p)中的一点,从出发引出一条射线l,在l上点附近去一点P,记 =
= ,如果
,如果![\xrightarrow[p\rightarrow p_{0}]{lim}](https://i-blog.csdnimg.cn/blog_migrate/da74878a899254b68fdaeaaf58dfa6f9.gif)
 =
= 方向导数是函数u(p)
方向导数是函数u(p)
梯度算法:
因为梯度的方向是f(x,y)变化最快的方向,所以沿着f(x,y)增长的梯度方向更能找到函数的最大值,沿着函数f(x,y)减小的方向更能找到函数的最小值。当求局部(全局)损失函数最大值时采用梯度上升的方法,当求解局部(全局)损失函数最小值时采用梯度上升的方法,当函数是凹凸函数的时候随机梯度法一定能够找到全局最优解,当函数不是凹凸函数时候很可能得到局部最优解。
梯度下降算法参数更新公式:

其中 为每次迭代向梯度下降方向前进的步长,也成为学习系数。J(
为每次迭代向梯度下降方向前进的步长,也成为学习系数。J( )成为目标函数,根据目标函数的不同可以对梯度下降算法进行分类。批量梯度下降法(BGD)整个训练集参与计算,数据量较大,收敛速度较慢。随机梯度下降法(SGD)针对训练集中的一个训练样本进行计算,又称为在线学习,收敛速度块但是会出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。小批量样本计算(MGD)选取训练集中一个小样本计算J(),保证训练过程稳定,这是目前最常用的梯度下降算法。
)成为目标函数,根据目标函数的不同可以对梯度下降算法进行分类。批量梯度下降法(BGD)整个训练集参与计算,数据量较大,收敛速度较慢。随机梯度下降法(SGD)针对训练集中的一个训练样本进行计算,又称为在线学习,收敛速度块但是会出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。小批量样本计算(MGD)选取训练集中一个小样本计算J(),保证训练过程稳定,这是目前最常用的梯度下降算法。
图解机器学习matlab源码解释:
rand('state',0);randn('state',0); %指定状态s部分为0可以得到相同的操作结果
n=50;N=1000;
x=linspace(-3,3,n)';X=linspace(-3,3,N)';%x为训练样本,X为拟合x的测试样本集合
pix=pi*x;y=sin(pix)./(pix)+0.1*x+0.05*randn(n,1);
hh=2*0.3^2;
t0=randn(n,1); e=0.1;
for o=1:n*1000
i=ceil(rand*n);%i取值为不大于括号内最大的整数
ki=exp(-(x-x(i)).^2/hh);%精髓随机取样本(xi,yi)对样本xi进行全体样本升维,把ki变成一个(n*1)的向量
t=t0-e*ki*(ki'*t0-y(i));%根据随机梯度下降的更新公式可以得到: ,
,;
if norm(t-t0)<0.000001 break,end %norm函数在这里的意思表示求2范数
t0=t;
end
K=exp(-(repmat(X.^2,1,n)+repmat(x.^2',N,1)-2*X*x')/hh); %X是准备拟合训练集样本点的测试集的横坐标,因为两个矩阵的规模不一样所以需要用repmat矩阵把两个矩阵化成可以进行k内积的形式,最后的形式为
F=K*t;%F=![\left [ k(X,x1)...k(X,x50) \right ]\left [ \theta 1...\theta 50 \right ]^{T}](https://i-blog.csdnimg.cn/blog_migrate/65ef89e04a45076f40f69851e0c804ae.gif) 其中X=
其中X=![\left [ X1...X1000 \right ]^{T}](https://i-blog.csdnimg.cn/blog_migrate/686f95fbc9486e43cee7200aabf17b8c.gif)
figure(1);clf;hold on;axis([-2.8 2.8 -0.5 1.2]);
plot(X,F,'-g');plot(x,y,'bo');
















 3102
3102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









