







对应论文:《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》
DCGAN,全称是 Deep Convolution Generative Adversarial Networks(深度卷积生成对抗网络),是 Alec Radfor 等人于2015年提出的一种模型。该模型在 Original GAN 的理论基础上,开创性地 将 CNN 和 GAN 相结合 以 实现对图像的处理,并 提出了一系列 对网络结构的限制 以 提高网络的稳定性。
DCGAN 的网络结构 在之后的各种改进 GAN 中得到了广泛的沿用,可以说是当今各类改进 GAN 的前身。
【参考代码(TensorFlow)】
https://github.com/carpedm20/DCGAN-tensorflow
【推荐资料】
原理解读:
[1] DCGAN 论文翻译
[2] GANs学习系列(9):DCGAN对抗卷积神经网络总结
代码解读:
[1] DCGAN 代码简单解读
[2] DCGAN论文及代码学习
[3] DCGAN生成二次元美少女头像
一、原理介绍
方法细节
网络概述
作者经过反复实验和尝试之后,提出了一系列的架构,make GAN + CNN more stable and deeper,能够产生更高分辨率的图像。
DCGAN 对现有的 CNN 架构做了如下几个方面的修改:
-
全卷积网络(all convolutional net):用步幅卷积(strided convolutions)替代确定性空间池化函数(deterministic spatial pooling functions)(比如最大池化),让网络自己学习downsampling方式。作者对 generator 和 discriminator 都采用了这种方法。
-
取消全连接层: 比如,使用 全局平均池化(global average pooling)替代 fully connected layer。global average pooling会降低收敛速度,但是可以提高模型的稳定性。GAN的输入采用均匀分布初始化,可能会使用全连接层(矩阵相乘),然后得到的结果可以reshape成一个4 dimension的tensor,然后后面堆叠卷积层即可;对于鉴别器,最后的卷积层可以先flatten,然后送入一个sigmoid分类器。
-
批归一化(Batch Normalization): 即将每一层的输入变换到0均值和单位方差(注:其实还需要shift 和 scale),BN 被证明是深度学习中非常重要的 加速收敛 和 减缓过拟合 的手段。这样有助于解决 poor initialization 问题并帮助梯度流向更深的网络。防止G把所有rand input都折叠到一个点。但是实践表明,将所有层都进行Batch Normalization,会导致样本震荡和模型不稳定,因此 只对生成器(G)的输出层和鉴别器(D)的输入层使用BN。
-
Leaky Relu 激活函数: 生成器(G),输出层使用tanh 激活函数,其余层使用relu 激活函数。鉴别器(D),都采用leaky rectified activation。
概括来说,DCGAN的主要的tricks如下图所示:

具体网络结构
DCGAN生成器G的结构如下图所示:
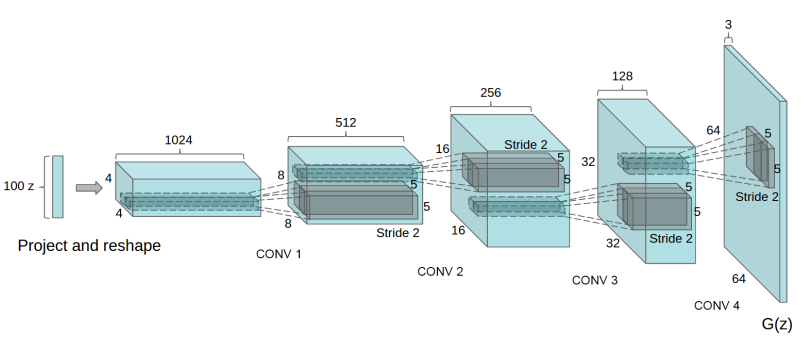
从随机向量z到4×4×1024的数据体的映射变换容易让人困惑,可以结合具体代码来理解具体操作。
def generator(self, z, y=None):
with tf.variable_scope("generator") as scope:
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
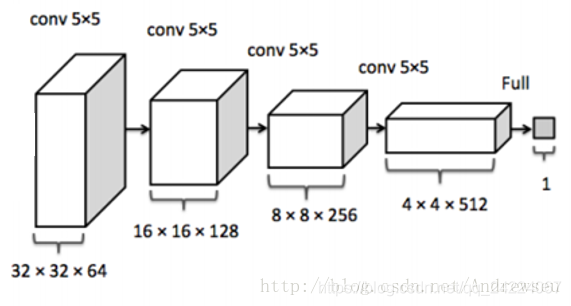
判别器D的结构如下图所示
二、文章详解(翻译)
0. Abstract
CNN在supervised learning 领域取得了非常了不起的成就(比如大规模的图片分类,目标检测等等),但是在unsupervised learning领域却没有特别大的进展。所以作者想弥补CNN在supervised 和 unsupervised之间的隔阂(gap)。作者提出了 将CNN和GAN相结合 的DCGAN,并展示了它在unsupervised learning所取得的不俗的成绩。作者通过在大量不同的image datasets上的训练,充分展示了DCGAN的generator(生成器)和discriminator(鉴别器)不论是在物体的组成部分(parts of object)还是场景方面(scenes)都学习到了丰富的层次表达(hierarchy representations)。作者还将学习到的特征应用于新的任务上(比如image classification),结果表明这些特征是非常好的通用图片表达(具有非常好的泛化能力)。
1. Introduction
这篇文章在以下几个方面做出了贡献:
- 文中提出并评估了一系列的对于卷积GAN的结构的限制(注:DCGAN的网络结构在之后的许多改进GAN中也得到了沿用),这些限制确保了在大多数情况下,卷积GAN可以保持稳定。文中将这种结构命名为DCGAN。
- 文中将 训练好的鉴别器应用于图片分类任务,并和其他的非监督方法进行对比,发现它非常competitive。
- 文中可视化了DCGAN的filters,结果表明特定的filter学习到了特定的object。
- 文中表明生成器具有有趣的向量算数属性(vector arithmetic property),这使得我们可以对生成的样本进行语义上的操作(类似于NLP中的word embedding 的性质,文中作者举了给女性戴墨镜的例子,详见下文)。
2. 实验
文章主要在LSUN数据集,ImageNet 1k以及一个较新的celebA数据集上进行了实验。训练的一些细节如下:
- image preprocessing。我们没有对图片进行pre-processing,除了将generator的输出变换到[-1,1]。
- SGD。训练使用mini-batch SGD,batch size = 128。
- parameters initialize。所有的参数都采用0均值,标准差为0.02的初始化方式。
- leaky relu。leaky relu 的 α的取值为0.2。
- optimizers。我们使用Adam optimizer,并且对参数做了一些fine tuing,我们实验发现默认的学习率为0.001,太高了,我们调整为0.0002。Adam中的momentum term β1=0.9太高了,会使得训练过程震荡,不稳定,我们将其调整为0.5发现可以使训练过程更加稳定。
2.1 LSUN
overfitting。当生成模型产生的图片质量越来越好的时候,我们就需要考虑overfitting的问题了,即generator有可能只是简单记住训练样本,然后产生类似的输出结果。为了展示DCGAN如何扩展到更大的数据集以及产生更高质量的图片,我们在包含300万训练样本的celebA bedroom datasets 上进行了训练。作者展示了每一轮训练之后采样的结果,表明模型产生的高质量输出不是简单通过记住训练样本而得到的。
去重(deduplication)
为了防止模型过拟合,即模型简单记住输入的特征,然后生成类似的图片。作者还对训练样本进行了去重处理,即去除相似度较高的图片。具体的原理可以参考论文。
2.2 FACES
原始的celebA数据集是从互联网网页上抓取的现代人的人脸数据集。大约包含300张约10000个人的人脸数据。文中对这些数据使用opencv的face detector进行人脸检测,保证得到具有一定高精度的人脸bounding box,最后得到大约35w个face bounding box,然后使用这些face bounding box 进行训练。没有使用data augmentation。
2.3 imagenet-1k
对imagenet-1k的图片使用32x32的min-resized-center-crops进行训练。同样没有进行data augmentation。
三、DCGAN实现
待补充
参考资料

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









