







对应论文:《Conditional Generative Adversarial Nets》
Conditional GAN (CGAN,条件GAN),是 Mehdi Mirza 于2014年11月份发表的一篇文章,也是 GAN 系列的早期经典模型之一,是目前许多GAN应用的前身。
文章的想法是 希望 可以控制 GAN 生成的图片,而不是单纯的随机生成图片。具体地,Conditional GAN 在生成器和判别器的输入中增加了额外的 条件信息,生成器生成的图片只有足够真实且与条件相符,才能够通过判别器。
【参考解读】
[1] 对抗生成网络学习(十三)——conditionalGAN生成自己想要的手写数字(tensorflow实现)
[2] 李弘毅老师GAN笔记(二),Conditional GAN
[3] 李宏毅 2018最新GAN课程 class 2 Conditional Generation by GAN
一、论文解读
原始的 GAN 模型没有任何条件限制,生成图像是随机的。因此作者考虑 加入一些条件信息,比如 类别标签 或者是 其他类型的数据,使得 图像生成能够朝规定的方向进行。
举个例子,比如输入一只狗在奔跑,输出即为一只狗在奔跑的图。

方法思路
Conditional GAN 的原论文比较短,主要是想法的阐述,对于具体的实现方式并没有做太多限定。
网络模型
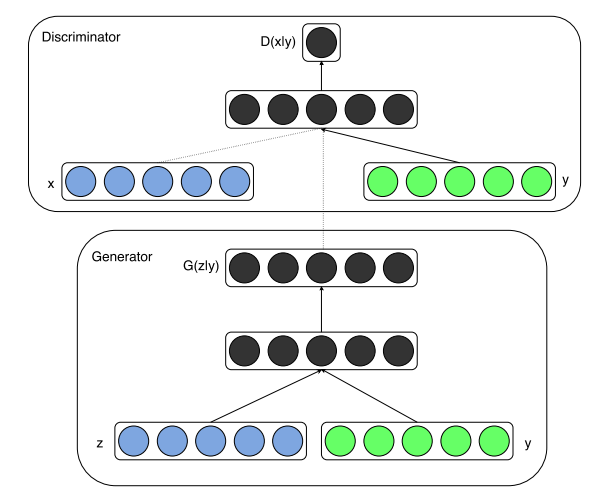
为了实现条件GAN的目的,生成网络和判别网络的原理和训练方式均要有所改变。
模型部分,在判别器和生成器中都添加了额外信息 y,y 可以是类别标签或者是其他类型的数据,可以将 y 作为一个额外的输入层丢入判别器和生成器。
在生成器中,作者将输入噪声 z 和 y 连在一起隐含表示,而对抗性训练框架在如何构成这种隐藏表示上具有相当大的灵活性。(需要注意的是,Conditional GAN中并没有用到卷积操作,所以这么操作是没有任何问题的。)
损失函数
二人极大极小博弈的目标函数为:
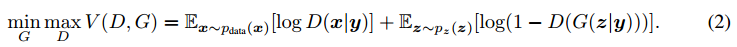
MNIST实验
在该实验中,作者使用MNIST的类别标签的one-hot编码作为条件信息y。具体的网络模型可以参考原文。
作者在MNIST数据集上的实验效果:

二、Conditional GAN的延伸
Conditional GAN的想法在各方面的细节上,比如条件y的具体内容(类别标签、实际的图片…),生成器、判别器中条件y的表示方式,判别器的打分方式(真实度和条件符合度放在一起打还是分开来打)等,有各种实现形式,因而延伸出了丰富的应用。
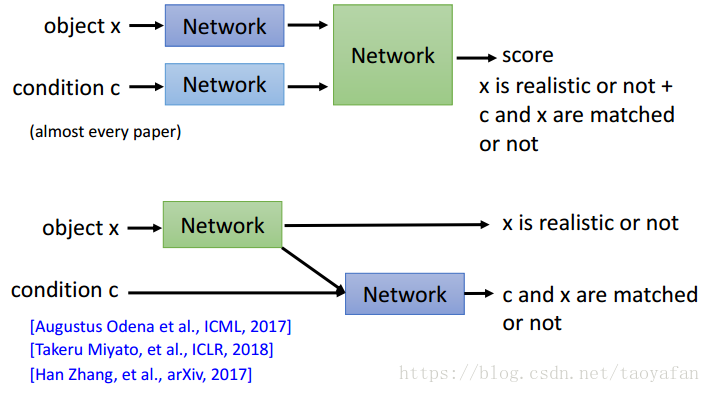
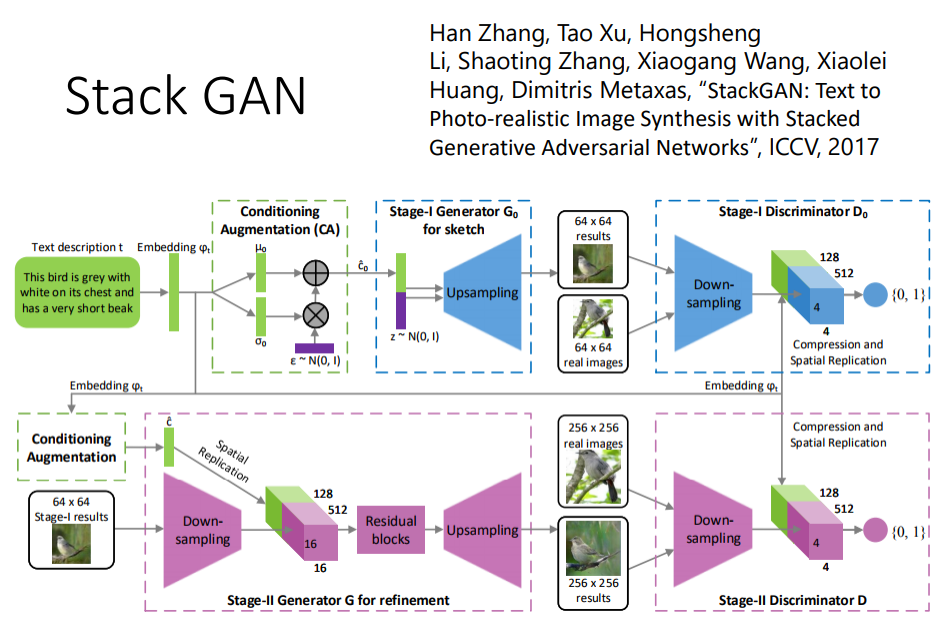
(1)text-to-image(文本生成图像)
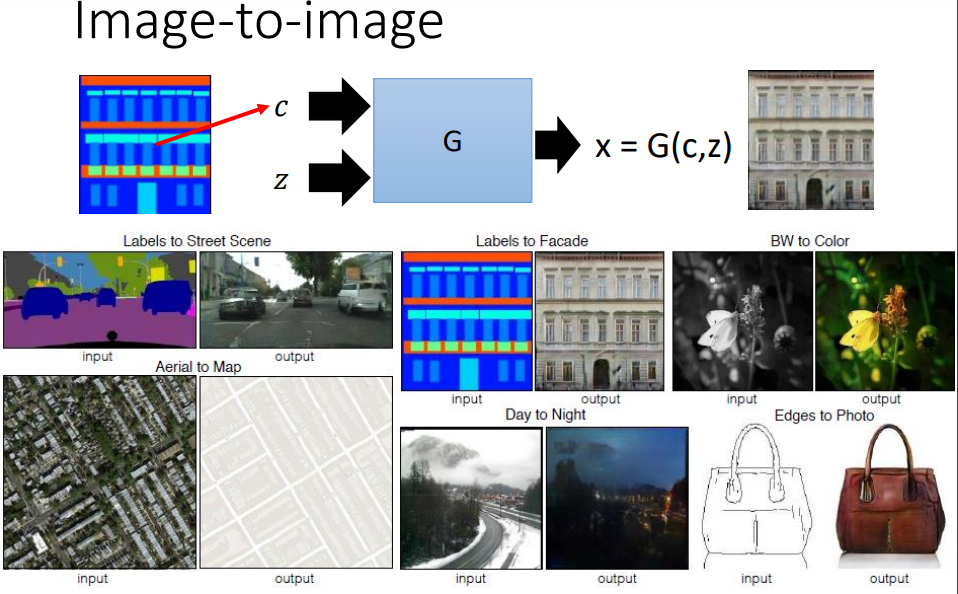
(2)image-to-image(图像转换)
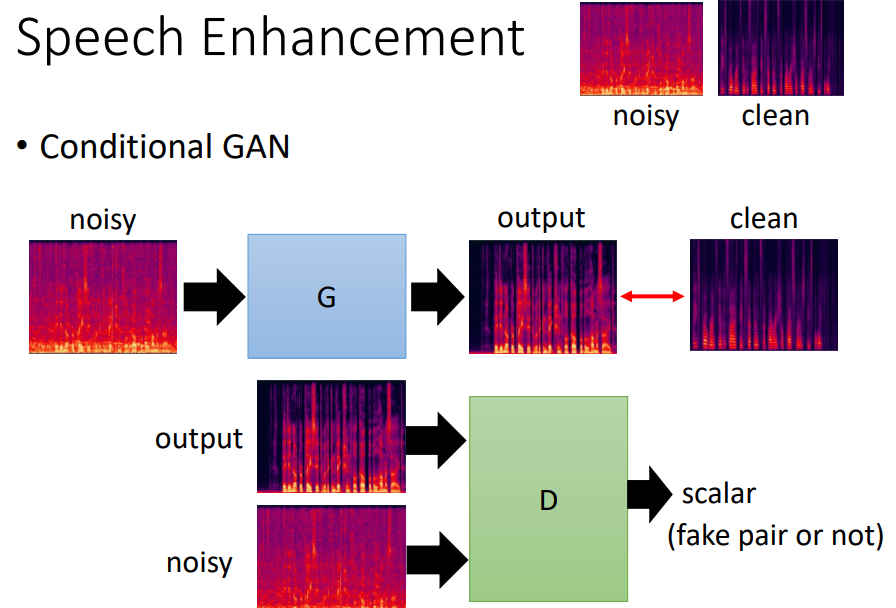
(3)Speech Enhancement(语音增强 )
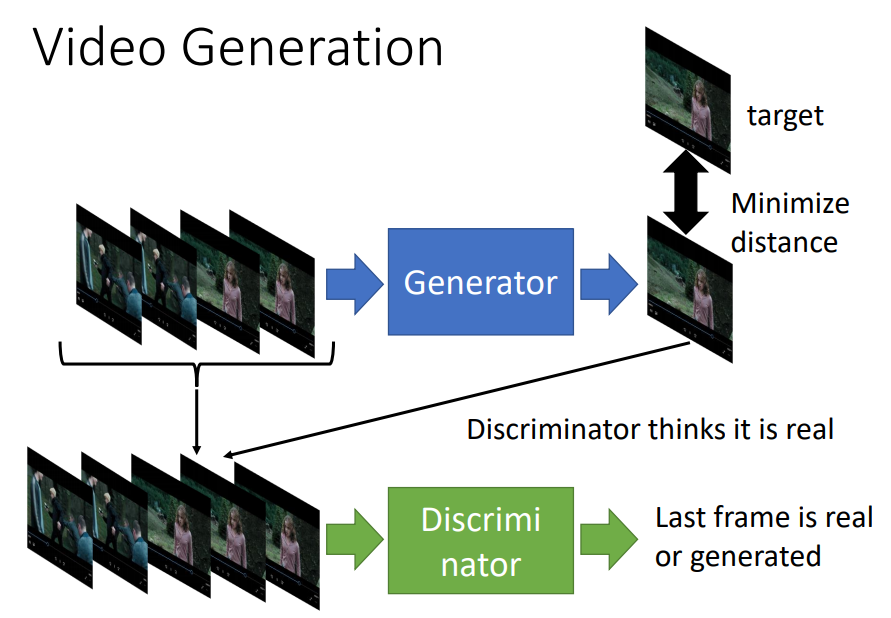
(4)Video Generation(视频生成)

















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









