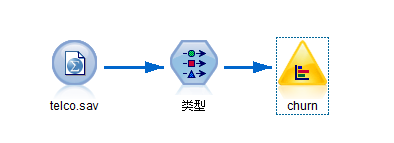
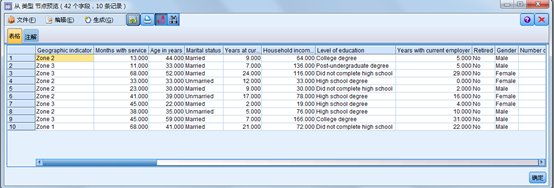
在SPSS Modeler中,“图形”选项板提供了日常分析所需要的大量图形,从基本的散点图、直方图到热图、气泡图甚至地图可视化。前面我们学习了散点图和线图的绘制过程,今天,小编带大家一起进入条形图的世界。 条形图:一般用于分类变量的分布情况分析。 在SPSS Modeler中,主要通过“分布”节点完成条形图的绘制。 案例:Demo文件下的“telco.sav”的数据文件。 数据流 数据展示: 1. 简单条形图 1.1 选项卡 目的








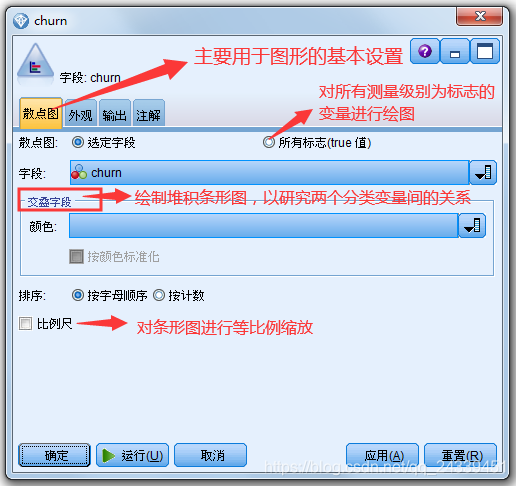
 本文介绍了如何在SPSS Modeler中创建和设置简单条形图及堆积条形图,用于分析分类变量的分布。通过分布节点操作,展示了客户流失的分布情况,并探讨不同性别间客户流失的差异。案例基于'Demo文件下的telco.sav'数据文件,通过设置选项卡和查看结果,揭示了条形图在数据分析中的应用。
本文介绍了如何在SPSS Modeler中创建和设置简单条形图及堆积条形图,用于分析分类变量的分布。通过分布节点操作,展示了客户流失的分布情况,并探讨不同性别间客户流失的差异。案例基于'Demo文件下的telco.sav'数据文件,通过设置选项卡和查看结果,揭示了条形图在数据分析中的应用。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






