







论文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
Abstract
OverFeat可以解决计算机视觉领域的三大任务:分类、定位、检测。这三个任务的区别是:
-
图片分类:给定一张图片,为每张图片打一个标签,说出图片是什么物体,然而因为一张图片中往往有多个物体,因此我们允许取出概率最大的5个,只要前5个最大的概率包含人工标定的标签,就任务分类正确(top-5)。
-
定位任务:除了要预测图片的类别,还有定位这个对象的位置,要求定位物体的矩形框(bounding box)与正确的位置(ground-truth bounding box)差不能超过规定的阈值。
-
检测任务:给定一张图片,把图片中的所有物体全部找出来(包括类别和位置)。
OverFeat的使用的工具是FCN和offset max-pooling。其实在文中OverFeat是特征提取器,使用类似Alexnet前5层卷积层的卷积网络提取图片的特征。这篇博客的OverFeat指解决分类、定位和检测任务的算法。OverFeat的架构是特指提取器+分类器+回归器,这样就能同时实现分类、定位和检测任务。接下来具体地说明作者是如何实现的。
Architecture
OverFeat有两种网络架构,分别对应两中模式——fast模式和accurate模式。
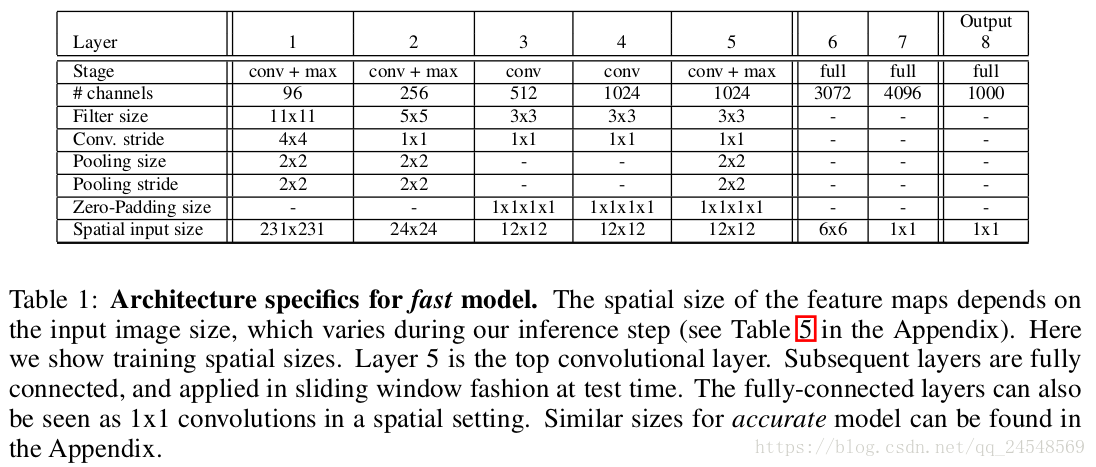
fast模式的架构图:
accurate模式的架构图:
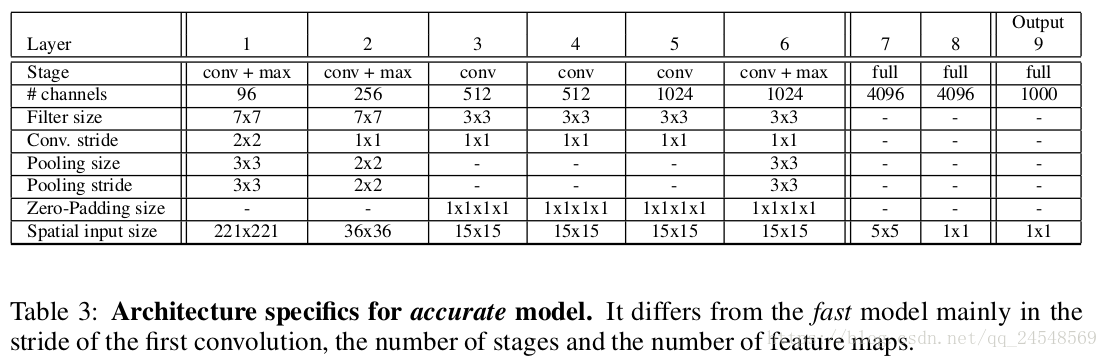
从名字上就能看出两种模式的区别了,fast模式运算速度快,而accurate模式的预测结果更加精确。主要原因是accurate模型的卷积步长变小,全连接层的神经元变多,在提高预测能力的同时增加了更多的参数和连接数,导致运算量变大,速度变慢。
OverFeat的网络架构参考了Alexnet,不同之处在于:OverFeat没有LRN层(许多论文都说LRN层没用);OverFeat池化区域没有重合(步长=过滤器大小);OverFeat第一层和第二层的feature maps更大,因为卷积步长减少了。
三者的参数和连接数比较

Classification
OverFeat的训练过程与Alexnet的一样,测试过程不同。Alexnet从图片中取出10个view(4个角和中间,并水平翻转)出来,由这10个view的分类结果进行投票决定。这样可以会出现这样的情况,取出来的view只包含物体的部分内容。而且重复了view之间重叠部分的计算。Alexnet只计算一种图片比例,有可能不是最优的图片比例,达不到最大的分类置信度。
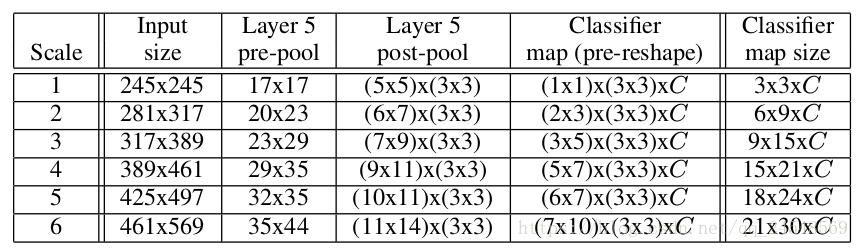
为了能够预测不同的图片比例,OverFeat使用6中不同的图片比例,如下图所示
FCN
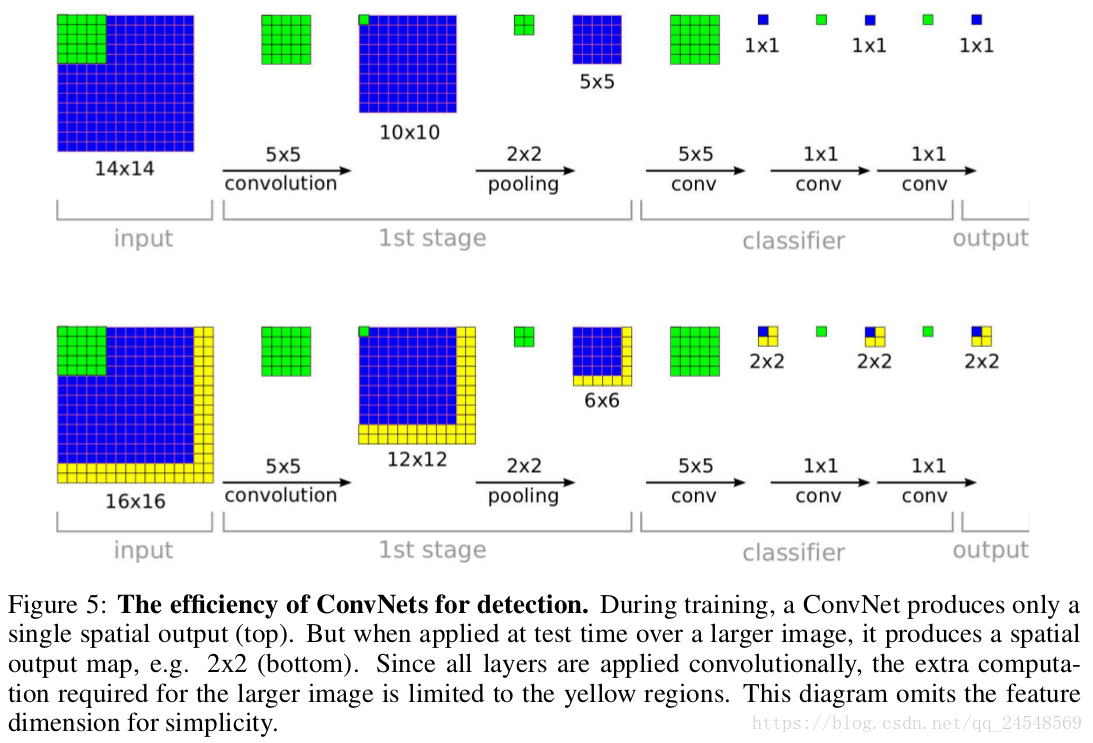
OverFeat把网络的全连接层改成卷积层,使得OverFeat变成一个FCN网络,这样就支持输入整个测试图片,效果是
上半部分表示训练时的卷积过程,最后只有1个输入。下半部分表示测试时输入一个更大的图片,通过FCN后产生4个输出,每个输出表示对应原图位置的预测结果。FCN对全图片进行分类的效果等于使用滑动窗体对图片进行分类,但是FCN的效率更高,FCN可以同时对所有的滑动窗体进行计算,窗体间重叠部分不用重复计算。
offset max-pooling
为了能够产生更多区域的输出结果,OverFeat把第5层卷积层后的池化层改成offset max-pooling。
对于一张图片,在给定的图片比例下,开始对第5层未池化的feature map进行处理。在偏移量为 ( Δ x , Δ y ) (\Delta_x, \Delta_y) (Δx,Δy)的情况下进行池化操作。偏移量取 { 0 , 1 , 2 } \{0, 1, 2\} {0,1,2},一共 3 × 3 3 \times 3 3×3种偏移情况,那么就有 3 × 3 3 \times 3 3×3中池化结果。使用分类器对每种偏移 ( Δ x , Δ y ) (\Delta_x, \Delta_y) (Δx,Δy)的feature map进行分类,每个feature map产生C维的输入maps(大小取决于输入图片的大小,通道数为C,C为类别个数)。最后不同的偏移 ( Δ x , Δ y ) (\Delta_x, \Delta_y) (Δx,Δy)的输出map合起来并reshape成一个3D的输出map。
下图是在y轴上进行offset max-pooling并分类的示意图
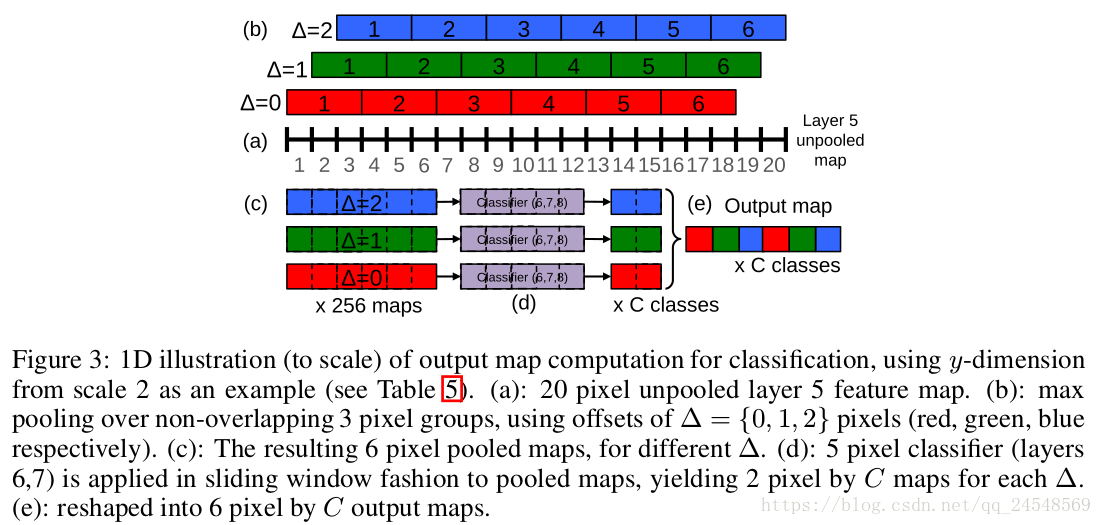
第5层feature map的y轴长度为20(在第二种图片比例中),对于3种偏移量,有3种pooling map。对每种pooling map进行分类,每种pooling map输出两个预测值。把这 3 × 2 3 \times 2 3×2个预测值合在一起。上图没有画出feature map的通道数,但有文字说明。各种图片比例的offset max-pooling的feature map的大小请看前面的图片比例表。表中的 3 × 3 3 \times 3 3×3就表示了9中偏移 ( Δ x , Δ y ) (\Delta_x, \Delta_y) (Δx,Δy),C表示通道数,剩下的表示feature map的大小。
最后是投票分类结果,每种图片比例的输出map中选择最高的作为该图片比例的分类分数,然后平均各种图片比例的分类分数,作为最终的分类分数。
Localization
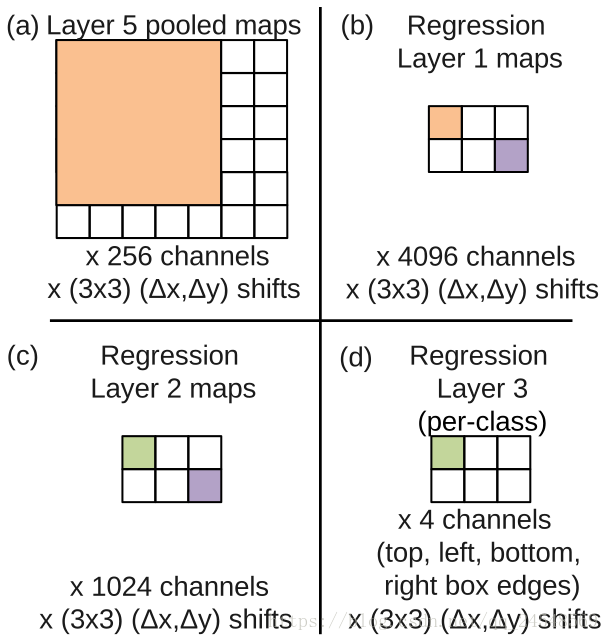
OverFeat使用回归器预测物体的bounding box。回归器的示意图如下:
上图表示第二种图片比例在回归器上的传递过程。OverFeat对不同的类别使用不同回归器比不同类别使用同一个回归器的效果差,作者认为这是数据集中每个类别的数量少的原因。
每个图片有6种图片比例,每种比例又有多个预测结果,OverFeat是通过下面算法合并这些bounding box的。
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
Detection
图片检测和定位差不多,只是检测有多个bounding box的输出。














 6808
6808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









