







1.实现RNN网络的前向传播
1.1RNN cell的前向传播
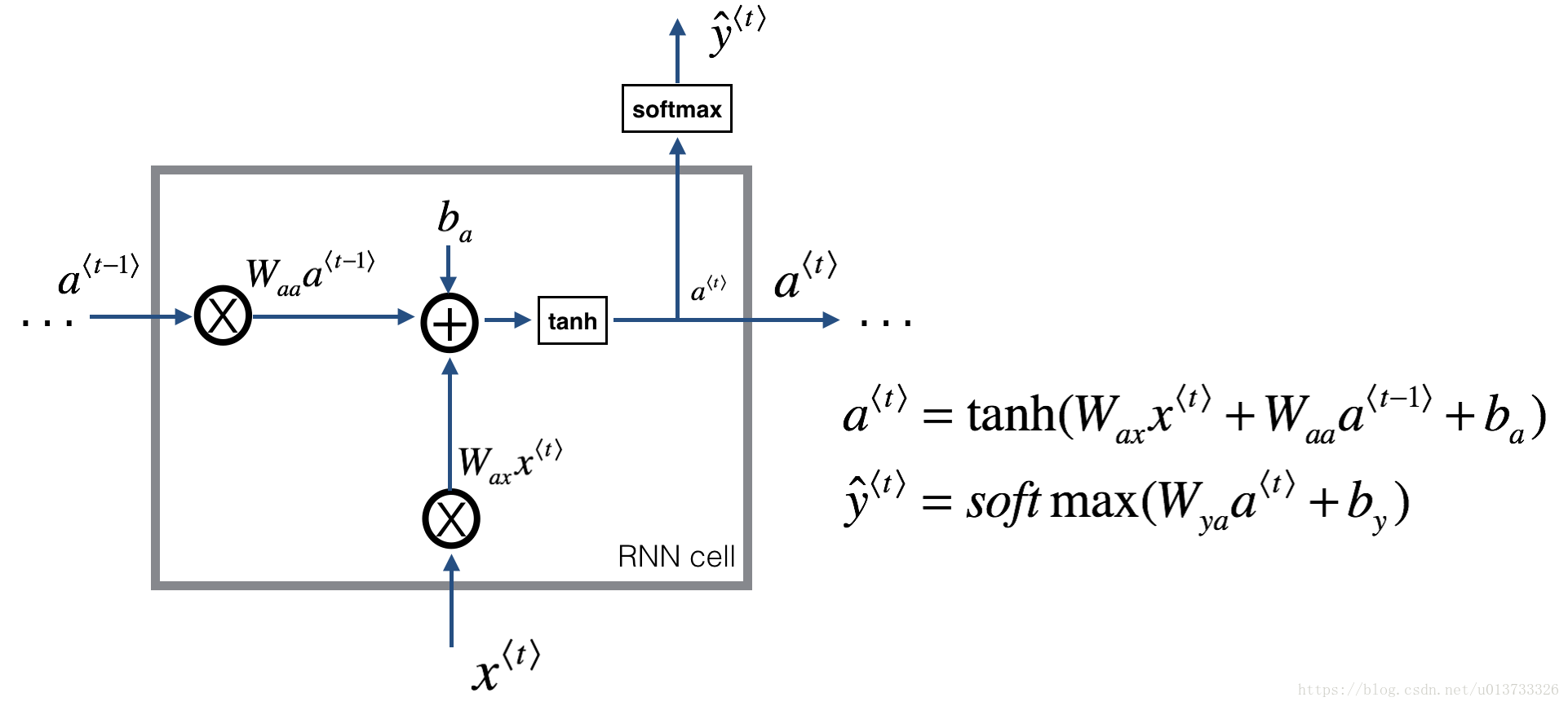
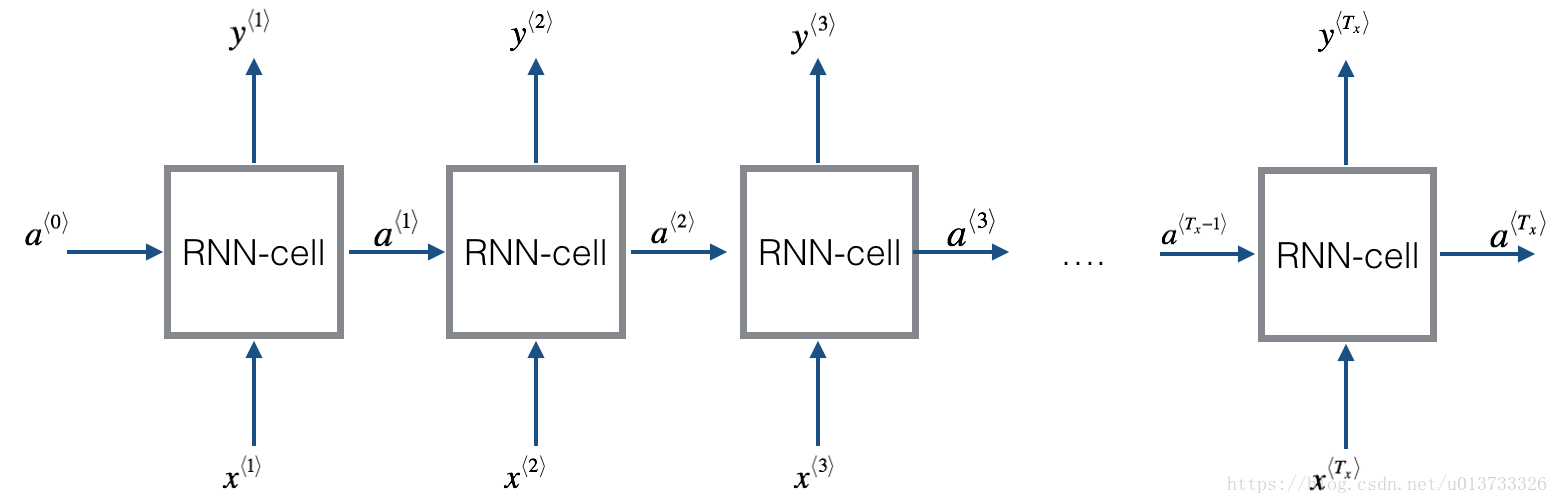
1.2RNN的前向传播
#!/usr/bin/env python
# _*_ coding:utf-8 _*
import numpy as np
import rnn_utils
# 1.计算在rnn cell中基本的计算,根据A(t-1),X(t)计算A(t)/Y(t)
def rnn_cell_forward(xt,a_prev,parameters):
'''
实现rnn单元的单步向前传播
:param xt: 时间步“t”输入的数据,维度为(n_x, m)
:param a_prev:时间步“t - 1”的隐藏隐藏状态,维度为(n_a, m)
:param parameters: -- 字典,包含了以下内容:
Wax -- 矩阵,输入乘以权重,维度为(n_a, n_x)
Waa -- 矩阵,隐藏状态乘以权重,维度为(n_a, n_a)
Wya -- 矩阵,隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
ba -- 偏置,维度为(n_a, 1)
by -- 偏置,隐藏状态与输出相关的偏置,维度为(n_y, 1)
:return: a_next -- 下一个隐藏状态,维度为(n_a, m)
yt_pred -- 在时间步“t”的预测,维度为(n_y, m)
cache -- 反向传播需要的元组,包含了(a_next, a_prev, xt, parameters)
'''
# 从parameters获取参数
Wax=parameters["Wax"]
Waa=parameters["Waa"]
Wya=parameters["Wya"]
ba=parameters["ba"]
by=parameters["by"]
# 使用公式计算下一个激活值
a_next=np.tanh(np.dot(Wax,xt)+np.dot(Waa,a_prev)+ba)
# 计算当前单元的输出
yt_pred=rnn_utils.softmax(np.dot(Wya,a_next)+by)
# 保存反向传播需要的值
cache=(a_next,a_prev,xt,parameters)
return a_next,yt_pred,cache
# 测试
# np.random.seed(1)
# xt=np.random.randn(3,10)
# a_prev=np.random.randn(5,10)
# Waa=np.random.randn(5,5)
# Wax=np.random.randn(5,3)
# Wya=np.random.randn(2,5)
# ba=np.random.randn(5,1)
# by=np.random.randn(2,1)
# parameters={
# "Waa":Waa,
# "Wax":Wax,
# "Wya":Wya,
# "ba":ba,
# "by":by
# }
# a_next, yt_pred, cache = rnn_cell_forward(xt, a_prev, parameters)
# print("a_next[4] = ", a_next[4])
# print("a_next.shape = ", a_next.shape)
# print("yt_pred[1] =", yt_pred[1])
# print("yt_pred.shape = ", yt_pred.shape)
# 2.计算rnn的前向传播,cell的循环
def rnn_forward(x,a0,parameters):
'''
实现循环神经网络的前向传播
:param x:输入的全部数据,维度为(n_x, m, T_x)
:param a0: 初始化隐藏状态,维度为 (n_a, m)
:param parameters:-- 字典,包含了以下内容:
Wax -- 矩阵,输入乘以权重,维度为(n_a, n_x)
Waa -- 矩阵,隐藏状态乘以权重,维度为(n_a, n_a)
Wya -- 矩阵,隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
ba -- 偏置,维度为(n_a, 1)
by -- 偏置,隐藏状态与输出相关的偏置,维度为(n_y, 1)
:return: a -- 所有时间步的隐藏状态,维度为(n_a, m, T_x)
y_pred -- 所有时间步的预测,维度为(n_y, m, T_x)
caches -- 为反向传播的保存的元组,维度为(【列表类型】cache, x)
'''
# 初始化"caches",它将以列表类型包含所有的cache
caches=[]
# 获取x与Wya的维度信息
n_x,m,T_x=x.shape
n_y,n_a=parameters["Wya"].shape
# 用0来初始化 a y
a=np.zeros([n_a,m,T_x])
y_pred=np.zeros([n_y,m,T_x])
# 初始化"next"
a_next=a0
# 遍历所有的时间步:从第0次迭代开始,计算出a[0],y[0],...
for t in range(T_x):
# 使用cell的向前传播来更新“next”,cache
a_next,yt_pred,cache=rnn_cell_forward(x[:,:,t],a_next,parameters)
# 使用a来保存next的第t个位置
a[:,:,t]=a_next
# 使用y来保存预测值
y_pred[:,:,t]=yt_pred
# caches
caches.append(cache)
# 保存反向传播需要的参数
caches=(caches,x)
return a,y_pred,caches
# 测试
# np.random.seed(1)
# x = np.random.randn(3,10,4)
# a0 = np.random.randn(5,10)
# Waa = np.random.randn(5,5)
# Wax = np.random.randn(5,3)
# Wya = np.random.randn(2,5)
# ba = np.random.randn(5,1)
# by = np.random.randn(2,1)
# parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
#
# a, y_pred, caches = rnn_forward(x, a0, parameters)
# print("a[4][1] = ", a[4][1])
# print("a.shape = ", a.shape)
# print("y_pred[1][3] =", y_pred[1][3])
# print("y_pred.shape = ", y_pred.shape)
# print("caches[1][1][3] =", caches[1][1][3])
# print("len(caches) = ", len(caches))
2 - 长短时记忆(Long Short-Term Memory (LSTM))网络
2.1LSTM单元的前向传播
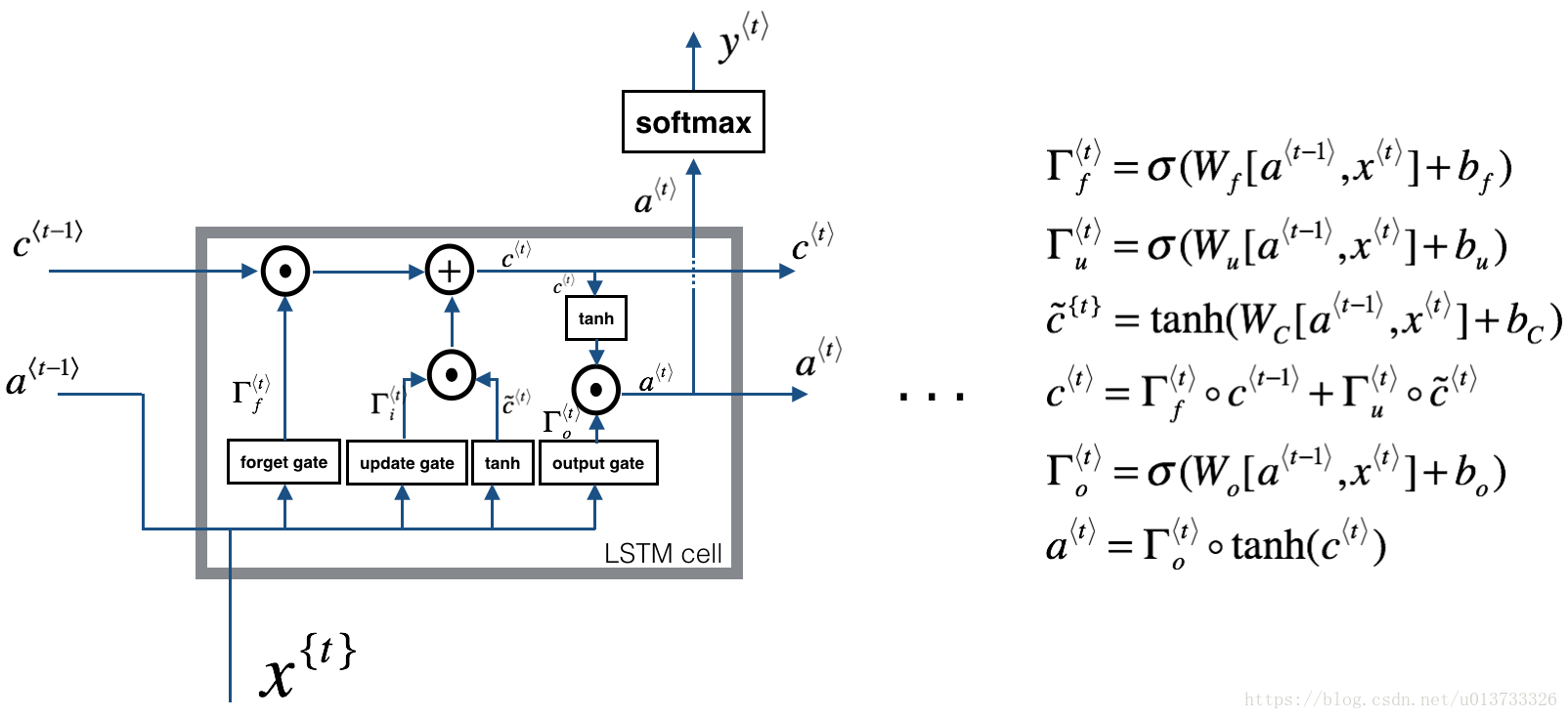
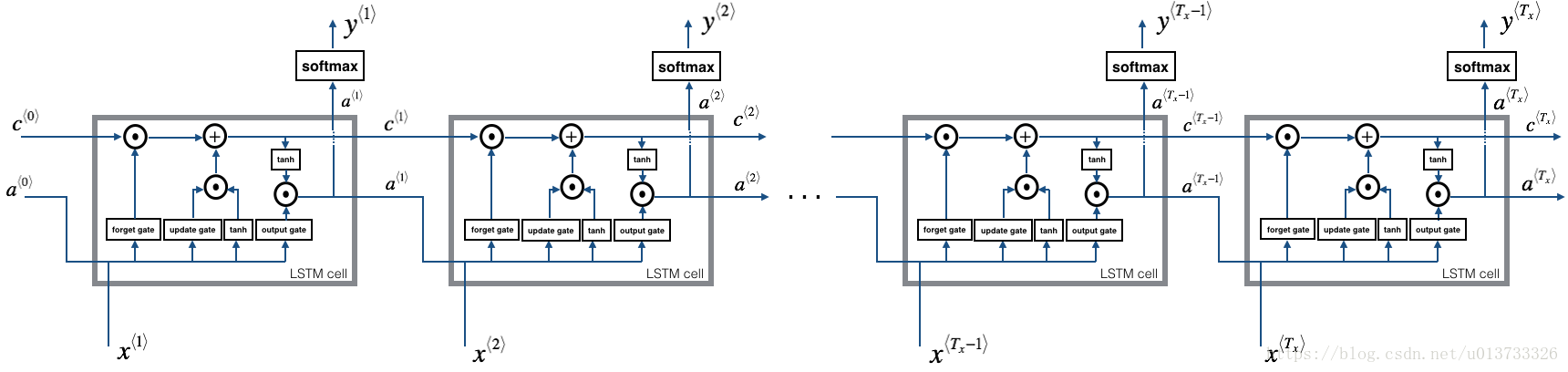
2.2LSTM前向传播
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import numpy as np
import rnn_utils
# 1.实现lstm单元计算
def lstm_cell_forward(xt,a_prev,c_prev,parameters):
'''
实现lstm单元的前向传播
:param xt:在时间步“t”输入的数据,维度为(n_x, m)
:param a_prev:上一个时间步“t-1”的隐藏状态,维度为(n_a, m)
:param c_prev:上一个时间步“t-1”的记忆状态,维度为(n_a, m)
:param parameters:字典类型的变量,包含了:
Wf -- 遗忘门的权值,维度为(n_a, n_a + n_x)
bf -- 遗忘门的偏置,维度为(n_a, 1)
Wi -- 更新门的权值,维度为(n_a, n_a + n_x)
bi -- 更新门的偏置,维度为(n_a, 1)
Wc -- 第一个“tanh”的权值,维度为(n_a, n_a + n_x)
bc -- 第一个“tanh”的偏置,维度为(n_a, n_a + n_x)
Wo -- 输出门的权值,维度为(n_a, n_a + n_x)
bo -- 输出门的偏置,维度为(n_a, 1)
Wy -- 隐藏状态与输出相关的权值,维度为(n_y, n_a)
by -- 隐藏状态与输出相关的偏置,维度为(n_y, 1)
:return: a_next -- 下一个隐藏状态,维度为(n_a, m)
c_next -- 下一个记忆状态,维度为(n_a, m)
yt_pred -- 在时间步“t”的预测,维度为(n_y, m)
cache -- 包含了反向传播所需要的参数,包含了(a_next, c_next, a_prev, c_prev, xt, parameters)
注意:ft/it/ot表示遗忘/更新/输出门,cct表示候选值(c tilda),c表示记忆值。
'''
# 从parameters 中获取相关的值
# 遗忘门
Wf=parameters["Wf"]
bf=parameters["bf"]
# 更新门
Wi=parameters["Wi"]
bi=parameters["bi"]
# 计算cct,候选值的权值
Wc=parameters["Wc"]
bc=parameters["bc"]
# 输出门
Wo=parameters["Wo"]
bo=parameters["bo"]
# 对y的权值
Wy=parameters["Wy"]
by=parameters["by"]
# 获取xt与Wy的维度信息
n_x,m=xt.shape
n_y,n_a=Wy.shape
# 1.连接a_prev与xt
contact=np.zeros([n_a+n_x,m])
contact[:n_a,:]=a_prev
contact[n_a:,:]=xt
# 2.根据公式计算ft,it,cct,c_next,ot,a_next
# 遗忘门
ft=rnn_utils.sigmoid(np.dot(Wf,contact)+bf)
# 更新门
it=rnn_utils.sigmoid(np.dot(Wi,contact)+bi)
# 更新单元
cct=np.tanh(np.dot(Wc,contact)+bc)
# 计算c_next
c_next=ft*c_prev+it*cct
# 输出门
ot=rnn_utils.sigmoid(np.dot(Wo,contact)+bo)
# 计算a_next
a_next=ot*np.tanh(c_next)
# 3.计算LSTM单元的预测值
yt_pred=rnn_utils.softmax(np.dot(Wy,a_next)+by)
# 保存反向传播需要的参数
cache=(a_next,c_next,a_prev,c_prev,ft,it,cct,ot,xt,parameters)
return c_next,a_next,yt_pred,cache
# 测试
# np.random.seed(1)
# xt = np.random.randn(3,10)
# a_prev = np.random.randn(5,10)
# c_prev = np.random.randn(5,10)
# Wf = np.random.randn(5, 5+3)
# bf = np.random.randn(5,1)
# Wi = np.random.randn(5, 5+3)
# bi = np.random.randn(5,1)
# Wo = np.random.randn(5, 5+3)
# bo = np.random.randn(5,1)
# Wc = np.random.randn(5, 5+3)
# bc = np.random.randn(5,1)
# Wy = np.random.randn(2,5)
# by = np.random.randn(2,1)
#
# parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
#
# a_next, c_next, yt, cache = lstm_cell_forward(xt, a_prev, c_prev, parameters)
# print("a_next[4] = ", a_next[4])
# print("a_next.shape = ", c_next.shape)
# print("c_next[2] = ", c_next[2])
# print("c_next.shape = ", c_next.shape)
# print("yt[1] =", yt[1])
# print("yt.shape = ", yt.shape)
# print("cache[1][3] =", cache[1][3])
# print("len(cache) = ", len(cache))
# 2.实现lstm前向传播进行计算,运行tx个时间步
def lstm_forward(x,a0,parameters):
'''
实现lstm单元组成的循环神经网络
:param x:所有时间步的输入数据,维度为(n_x, m, T_x)
:param a0:初始化隐藏状态,维度为(n_a, m)
:param parameters:-- python字典,包含了以下参数:
Wf -- 遗忘门的权值,维度为(n_a, n_a + n_x)
bf -- 遗忘门的偏置,维度为(n_a, 1)
Wi -- 更新门的权值,维度为(n_a, n_a + n_x)
bi -- 更新门的偏置,维度为(n_a, 1)
Wc -- 第一个“tanh”的权值,维度为(n_a, n_a + n_x)
bc -- 第一个“tanh”的偏置,维度为(n_a, n_a + n_x)
Wo -- 输出门的权值,维度为(n_a, n_a + n_x)
bo -- 输出门的偏置,维度为(n_a, 1)
Wy -- 隐藏状态与输出相关的权值,维度为(n_y, n_a)
by -- 隐藏状态与输出相关的偏置,维度为(n_y, 1)
:return:
a -- 所有时间步的隐藏状态,维度为(n_a, m, T_x)
y -- 所有时间步的预测值,维度为(n_y, m, T_x)
caches -- 为反向传播的保存的元组,维度为(【列表类型】cache, x))
'''
# 初始化cache
caches=[]
# 获取xt与wy的维度信息
n_x,m,T_x=x.shape
n_y,n_a=parameters["Wy"].shape
# 使用0来初始化a/c/y
a=np.zeros([n_a,m,T_x])
c=np.zeros([n_a,m,T_x])
y=np.zeros([n_y,m,T_x])
# 初始化a_next,c_next
a_next=a0
c_next=np.zeros([n_a,m])
# 遍历所有的时间步
for t in range(T_x):
# 更新下一个隐藏状态,下一个记忆状态,计算预测值,获取cache
a_next,c_next,yt_pred,cache=lstm_cell_forward(x[:,:,t],a_next,c_next,parameters)
# 更新状态值
a[:,:,t]=a_next
y[:,:,t]=yt_pred
c[:,:,t]=c_next
# 存储cache
caches.append(cache)
# 保存反向传播需要的参数
caches=(caches,x)
return a,y,c,caches
# 测试
# np.random.seed(1)
# x = np.random.randn(3,10,7)
# a0 = np.random.randn(5,10)
# Wf = np.random.randn(5, 5+3)
# bf = np.random.randn(5,1)
# Wi = np.random.randn(5, 5+3)
# bi = np.random.randn(5,1)
# Wo = np.random.randn(5, 5+3)
# bo = np.random.randn(5,1)
# Wc = np.random.randn(5, 5+3)
# bc = np.random.randn(5,1)
# Wy = np.random.randn(2,5)
# by = np.random.randn(2,1)
#
# parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
#
# a, y, c, caches = lstm_forward(x, a0, parameters)
# print("a[4][3][6] = ", a[4][3][6])
# print("a.shape = ", a.shape)
# print("y[1][4][3] =", y[1][4][3])
# print("y.shape = ", y.shape)
# print("caches[1][1[1]] =", caches[1][1][1])
# print("c[1][2][1]", c[1][2][1])
# print("len(caches) = ", len(caches))
3.神经网络的反向传播(选学)
3.1 - 基本的RNN网络的反向传播
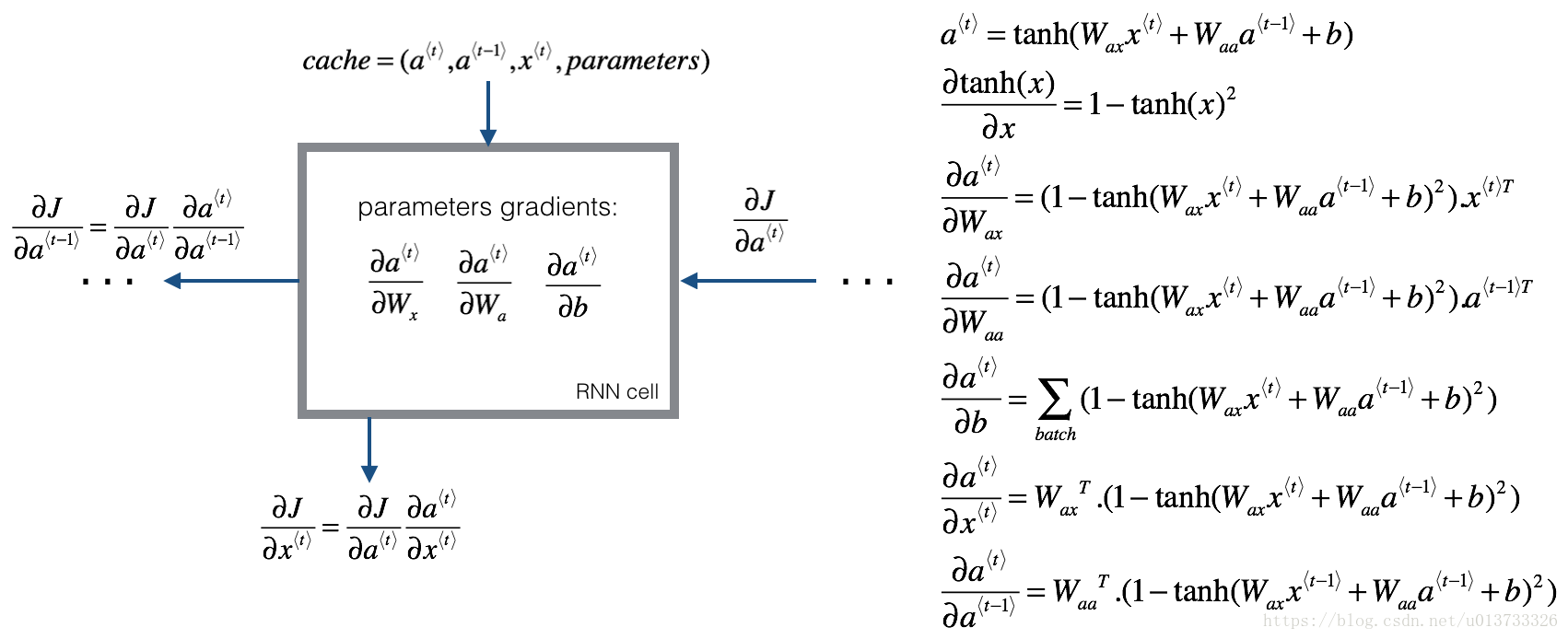
3.2 - LSTM反向传播


4.字符级语言模型 - 恐龙岛
4.1模型构建
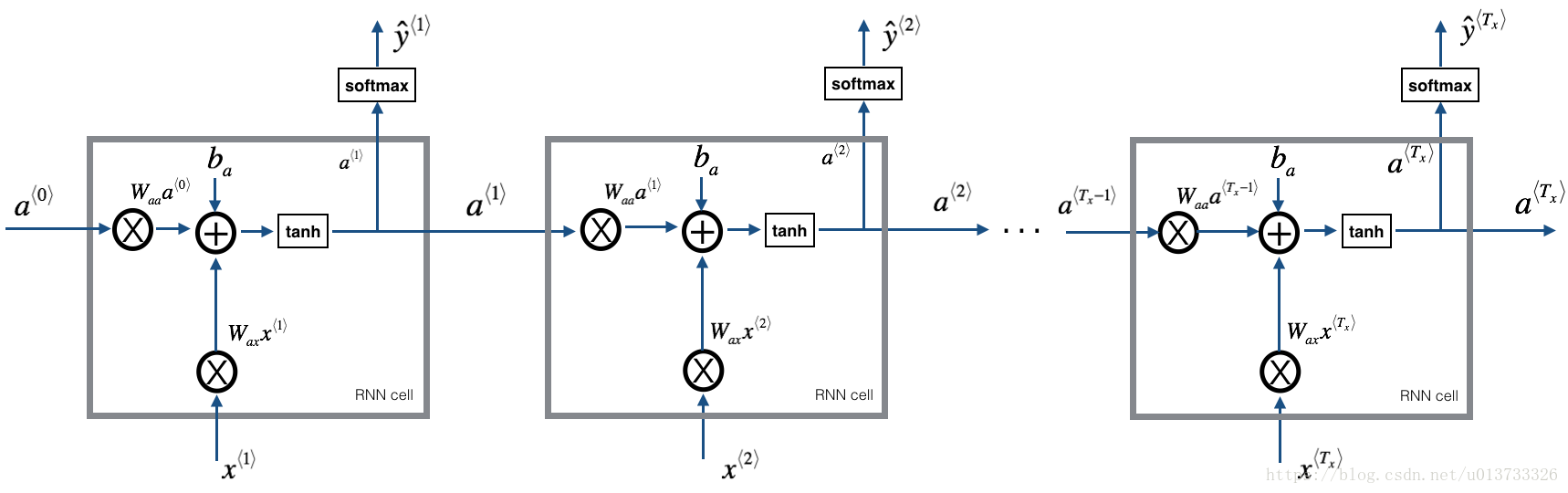
4.2模型梯度修剪
4.3模型采样
采样的作用在于,当在训练模型的过程中,可以根据训练的parameters参数,将一个随机的x【0】输入到模型中,根据当前模型进行计算出这个单词后面应该出现的字母列表。
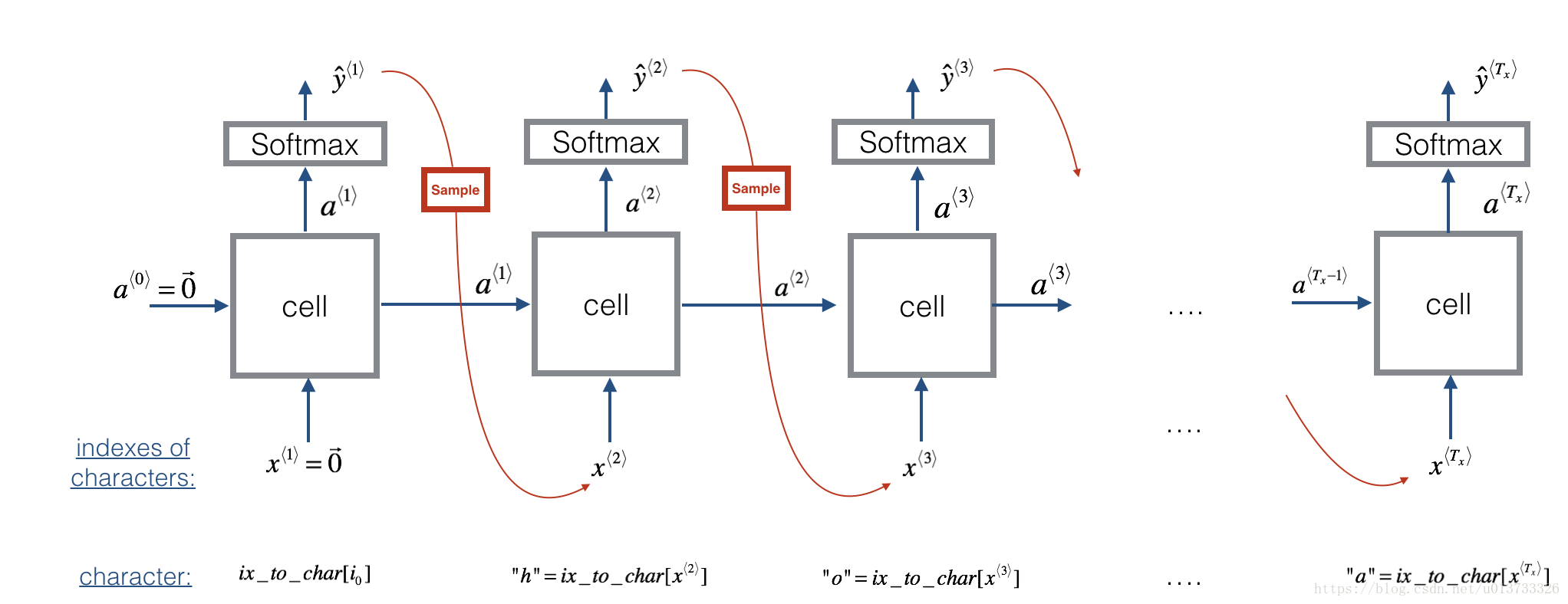
4.4构建模型-模型训练-模型采样
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import numpy as np
import time
import cllm_utils
# 1.数据集与预处理
# 获取名称
data = open("dinos.txt", "r").read()
# 转化为小写字母
data = data.lower()
# 转化为无序且不重复的元素列表
chars = list(set(data))
# 获取大小信息
data_size, vocab_size = len(data), len(chars)
# print(chars)
# print("共计有%d个字符,唯一字符有%d个"%(data_size,vocab_size))
# 创建一个字典,每个字符映射到0-26的索引
# 再创建一个字典,将每个索引映射回相应的字符
# 这两个字典会帮助我们找到softmax层概率分布输出中的字符
char_to_ix = {ch: i for i, ch in enumerate(sorted(chars))}
ix_to_char = {i: ch for i, ch in enumerate(sorted(chars))}
# print(char_to_ix)
# print(ix_to_char)
# 2.构建模型中的模块
# 2.1梯度修剪:在更新参数前,将梯度大于某一阈值的梯度转化为等于梯度的值
def clip(gradients, maxValue):
'''
使用maxValue来修剪梯度
:param gradients:-- 字典类型,包含了以下参数:"dWaa", "dWax", "dWya", "db", "dby"
:param maxValue:-- 阈值,把梯度值限制在[-maxValue, maxValue]内
:return: -- 修剪后的梯度
'''
# 获取参数
dWaa, dWax, dWya, db, dby = gradients["dWaa"], gradients["dWax"], gradients["dWya"], gradients["db"], gradients[
"dby"]
# 梯度修建
for gradient in [dWaa, dWax, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
gradients = {
"dWaa": dWaa,
"dWax": dWax,
"dWya": dWya,
"db": db,
"dby": dby
}
return gradients
# 测试
# np.random.seed(3)
# dWax = np.random.randn(5,3)*10
# dWaa = np.random.randn(5,5)*10
# dWya = np.random.randn(2,5)*10
# db = np.random.randn(5,1)*10
# dby = np.random.randn(2,1)*10
# gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
# gradients = clip(gradients, 10)
# print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
# print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
# print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
# print("gradients[\"db\"][4] =", gradients["db"][4])
# print("gradients[\"dby\"][1] =", gradients["dby"][1])
# 2.2采样
def sample(parameters, char_to_ix, seed):
'''
根据RNN输出的概率分布序列对字符序列进行采样
:param parameters: 包含了Waa, Wax, Wya, by, b的字典
:param char_to_ix:字符映射到索引的字典
:param seed:随机种子
:return:indices -- 包含采样字符索引的长度为n的列表。
'''
# 从parameters中获取参数
Waa, Wax, Wya, by, b = parameters["Waa"], parameters["Wax"], parameters["Wya"], parameters["by"], parameters["b"]
vocab_size = by.shape[0]
n_a = Waa.shape[1]
# 步骤一
# 创建独热向量x
x = np.zeros((vocab_size, 1))
# 使用0初始化a_prev
a_prev = np.zeros((n_a, 1))
# 创建索引的空列表,这是包含要生成的字符的索引的列表
indices = []
# IDX是检索换行标志,初始化为-1
idx = -1
# 循环遍历时间步骤t,在每个时间步中,从概率分布中抽取一个字符
# 并将其索引附加在indices中,如果达到50个字符
# (我们应该不太可能有一个训练好的模型),我们将停止循环,这有助于调试并防止进入无限循环
counter = 0
newline_character = char_to_ix["\n"]
while idx != newline_character and counter < 50:
# 步骤2:前向传播
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
y = cllm_utils.softmax(np.dot(Wya, a) + by)
# 设置随机种子
np.random.seed(counter + seed)
# 步骤3:从概率分布y中抽取词汇表中字符的索引
'''
choice用法:
np.random.seed(0)
p = np.array([0.1, 0.0, 0.7, 0.2])
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
这意味着你将根据分布选择索引:
'''
idx = np.random.choice(list(range(vocab_size)), p=y.ravel())
# 添加到索引中
indices.append(idx)
# 步骤4:更新x:将输入字符重写为与采样索引对应的字符
x = np.zeros((vocab_size, 1))
x[idx] = 1
# 更新a_prev
a_prev = a
# 累加器
seed += 1
counter += 1
if counter == 50:
indices.append(char_to_ix["\n"])
return indices
# 测试
# np.random.seed(2)
# _, n_a = 20, 100
# Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
# b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
# parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
#
#
# indices = sample(parameters, char_to_ix, 0)
# print("Sampling:")
# print("list of sampled indices:", indices)
# print("list of sampled characters:", [ix_to_char[i] for i in indices])
# 3.构建语言模型
# 3.1梯度下降
# 前向传播计算损失
# 反向传播计算关于参数的梯度损失
# 修剪梯度
# 使用梯度下降更新参数
# 构建优化函数
def optimize(X,Y,a_prev,parameters,learning_rate=0.01):
'''
执行训练模型的单步优化
:param X: -- 整数列表,其中每个整数映射到词汇表中的字符。
:param Y:-- 整数列表,与X完全相同,但向左移动了一个索引。
:param a_prev:上一个隐藏状态
:param parameters:-- 字典,包含了以下参数:
Wax -- 权重矩阵乘以输入,维度为(n_a, n_x)
Waa -- 权重矩阵乘以隐藏状态,维度为(n_a, n_a)
Wya -- 隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
b -- 偏置,维度为(n_a, 1)
by -- 隐藏状态与输出相关的权重偏置,维度为(n_y, 1)
:param learning_rate:-- 模型学习的速率
:return:
loss -- 损失函数的值(交叉熵损失)
gradients -- 字典,包含了以下参数:
dWax -- 输入到隐藏的权值的梯度,维度为(n_a, n_x)
dWaa -- 隐藏到隐藏的权值的梯度,维度为(n_a, n_a)
dWya -- 隐藏到输出的权值的梯度,维度为(n_y, n_a)
db -- 偏置的梯度,维度为(n_a, 1)
dby -- 输出偏置向量的梯度,维度为(n_y, 1)
a[len(X)-1] -- 最后的隐藏状态,维度为(n_a, 1)
'''
# 前向传播
loss,cache= cllm_utils.rnn_forward(X, Y, a_prev, parameters)
# 反向传播
gradients,a= cllm_utils.rnn_backward(X, Y, parameters, cache)
# 梯度修建[-5,5]
gradients=clip(gradients,5)
# 更新参数
parameters= cllm_utils.update_parameters(parameters, gradients, learning_rate)
return loss,gradients,a[len(X)-1],parameters
# 测试
# np.random.seed(1)
# vocab_size, n_a = 27, 100
# a_prev = np.random.randn(n_a, 1)
# Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
# b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
# parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
# X = [12,3,5,11,22,3]
# Y = [4,14,11,22,25, 26]
#
# loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
# print("Loss =", loss)
# print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
# print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
# print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
# print("gradients[\"db\"][4] =", gradients["db"][4])
# print("gradients[\"dby\"][1] =", gradients["dby"][1])
# print("a_last[4] =", a_last[4])
# 3.2训练模型
def model(data,ix_to_char,char_to_ix,num_iterations=3500,n_a=50,dino_names=7,vocab_size=27):
'''
训练模型并生成恐龙名字
:param data:语料库
:param ix_to_char:索引映射字符字典
:param char_to_ix:字符映射索引字典
:param num_iterations: 迭代次数
:param n_a: RNN单元数量
:param dino_names:每次迭代中采样的数量
:param vocab_size:在文本中的唯一字符的数量
:return:parameters -- 学习后了的参数
'''
# 从vocab_size中获取n_x,n_y
n_x,n_y=vocab_size,vocab_size
# 初始化参数
parameters= cllm_utils.initialize_parameters(n_a, n_x, n_y)
# 初始化损失
loss= cllm_utils.get_initial_loss(vocab_size, dino_names)
# 构建恐龙名称列表
with open("dinos.txt") as f:
examples=f.readlines()
examples=[x.lower().strip() for x in examples]
# 打乱全部的恐龙名称
np.random.seed(0)
np.random.shuffle(examples)
# 初始化隐藏状态
a_prev=np.zeros((n_a,1))
# 循环
for j in range(num_iterations):
# 定义一个训练样本
# 将X的第一个值None解释为x⟨0⟩=0向量,此外,为了确保Y等于X,会向左移动一步,并添加一个附加的“\n”以表示恐龙名称的结束。
index=j%len(examples)
X=[None]+[char_to_ix[ch] for ch in examples[index]]
Y=X[1:]+[char_to_ix["\n"]]
# 执行单步优化:前向传播-》反向传播-》梯度修建-》更新参数
# 选择学习率为0.01
curr_loss,gradients,a_prev,parameters=optimize(X,Y,a_prev,parameters)
# 使用延迟来保持损失平滑,这是为了加速训练
loss= cllm_utils.smooth(loss, curr_loss)
# 每2000次迭代,通过sample生成“\n",字符,检查模型是否学习正确
if j%2000==0:
print("第"+str(j+1)+"次迭代,损失值为:"+str(loss))
seed=0
for name in range(dino_names):
# 采样
sampled_indices=sample(parameters,char_to_ix,seed)
cllm_utils.print_sample(sampled_indices, ix_to_char)
# 为了得到相同的效果,随机种子+1
seed+=1
return parameters
# 训练
start_time=time.clock()
# 开始训练
parameters=model(data,ix_to_char,char_to_ix,num_iterations=3500)
# 结束时间
end_time=time.clock()
# 计算时差
minmun=end_time-start_time
print("执行了:"+str(int(minmun/60))+"分"+str(int(minmun%60))+"秒")
5.写出莎士比亚风格的文字
5.1数据处理:
加载数据,-》创建训练集X,Y
![]()
-》将X,Y变成one-hot特征的向量
5.2加载训练好的模型
5.3将模型用于预测
根据用户的输入转为one-hot特征,将one-hot特征输入到model.predict中,得到下一个字符,然后根据这个字符进行下一轮的模型的预测
# Load Packages
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
import numpy as np
import random
import sys
import io
def build_data(text, Tx = 40, stride = 3):
"""
Create a training set by scanning a window of size Tx over the text corpus, with stride 3.
Arguments:
text -- string, corpus of Shakespearian poem
Tx -- sequence length, number of time-steps (or characters) in one training example
stride -- how much the window shifts itself while scanning
Returns:
X -- list of training examples
Y -- list of training labels
"""
X = []
Y = []
### START CODE HERE ### (≈ 3 lines)
for i in range(0, len(text) - Tx, stride):
X.append(text[i: i + Tx])
Y.append(text[i + Tx])
### END CODE HERE ###
print('number of training examples:', len(X))
return X, Y
def vectorization(X, Y, n_x, char_indices, Tx = 40):
"""
Convert X and Y (lists) into arrays to be given to a recurrent neural network.
Arguments:
X --
Y --
Tx -- integer, sequence length
Returns:
x -- array of shape (m, Tx, len(chars))
y -- array of shape (m, len(chars))
"""
m = len(X)
# 参数说明:有m个seq,每个seq是一个二维矩阵,行数是seq的每一个字母,列是字母onehot之后的向量,下面的代码就是将seq变成onehot向量之后
x = np.zeros((m, Tx, n_x), dtype=np.bool)
y = np.zeros((m, n_x), dtype=np.bool)
for i, sentence in enumerate(X):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[Y[i]]] = 1
return x, y
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
out = np.random.choice(range(len(chars)), p = probas.ravel())
return out
#return np.argmax(probas)
def on_epoch_end(epoch, logs):
# Function invoked at end of each epoch. Prints generated text.
None
#start_index = random.randint(0, len(text) - Tx - 1)
#generated = ''
#sentence = text[start_index: start_index + Tx]
#sentence = '0'*Tx
#usr_input = input("Write the beginning of your poem, the Shakespearian machine will complete it.")
# zero pad the sentence to Tx characters.
#sentence = ('{0:0>' + str(Tx) + '}').format(usr_input).lower()
#generated += sentence
#
#sys.stdout.write(usr_input)
#for i in range(400):
"""
#x_pred = np.zeros((1, Tx, len(chars)))
for t, char in enumerate(sentence):
if char != '0':
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, temperature = 1.0)
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
if next_char == '\n':
continue
# Stop at the end of a line (4 lines)
print()
"""
print("Loading text data...")
text = io.open('shakespeare.txt', encoding='utf-8').read().lower()
#print('corpus length:', len(text))
Tx = 40
chars = sorted(list(set(text)))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
#print('number of unique characters in the corpus:', len(chars))
print("Creating training set...")
X, Y = build_data(text, Tx, stride = 3)
print("Vectorizing training set...")
x, y = vectorization(X, Y, n_x = len(chars), char_indices = char_indices)
print("Loading model...")
model = load_model('models/model_shakespeare_kiank_350_epoch.h5')
def generate_output():
generated = ''
#sentence = text[start_index: start_index + Tx]
#sentence = '0'*Tx
usr_input = input("Write the beginning of your poem, the Shakespeare machine will complete it. Your input is: ")
# zero pad the sentence to Tx characters.
sentence = ('{0:0>' + str(Tx) + '}').format(usr_input).lower()
generated += usr_input
sys.stdout.write("\n\nHere is your poem: \n\n")
sys.stdout.write(usr_input)
# 循环400次产生长度为400的文章
for i in range(400):
x_pred = np.zeros((1, Tx, len(chars)))
for t, char in enumerate(sentence):
if char != '0':
x_pred[0, t, char_indices[char]] = 1.
# 预测出根据用户输入的数据的下一个单词列表
preds = model.predict(x_pred, verbose=0)[0]
# 对预测出的单词列表进行采样,得到下一个单词索引
next_index = sample(preds, temperature = 1.0)
# 根据索引找到相应的单词
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
if next_char == '\n':
continue运行上述程序
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import time
#开始时间
start_time = time.clock()
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=1, callbacks=[print_callback])
#结束时间
end_time = time.clock()
#计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")
# 运行此代码尝试不同的输入,而不必重新训练模型。
generate_output() #博主在这里输入hello
# 查看模型细节
#------------用于绘制模型细节,可选--------------#
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
plot_model(model, to_file='shakespeare.png')
SVG(model_to_dot(model).create(prog='dot', format='svg'))
#------------------------------------------------#
6.用LSTM网络即兴独奏爵士乐
6.1.数据集
shape of X: (60, 30, 78)
number of training examples: 60
Tx (length of sequence): 30
total # of unique values: 78
Shape of Y: (30, 60, 78)
6.2构建模型:
将x的每个时间步输入到reshapor-》LSTM_cell(64个lstm)》densor中,保存每个时间步的输出,作为outputs,然后根据y(x的左移)编译模型,训练模型
使用的是64维隐藏状态的LSTM模块,所以n_a = 64。下图中有64个lstm
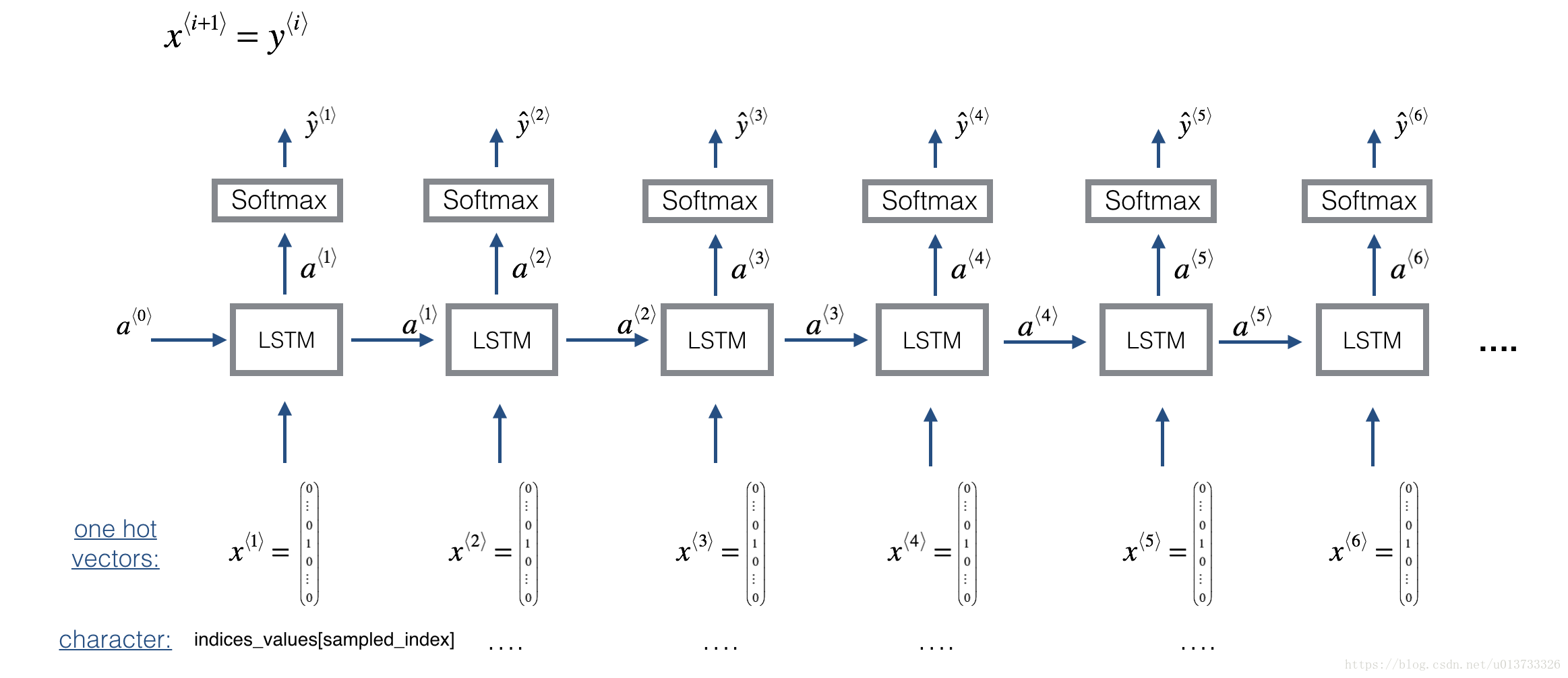
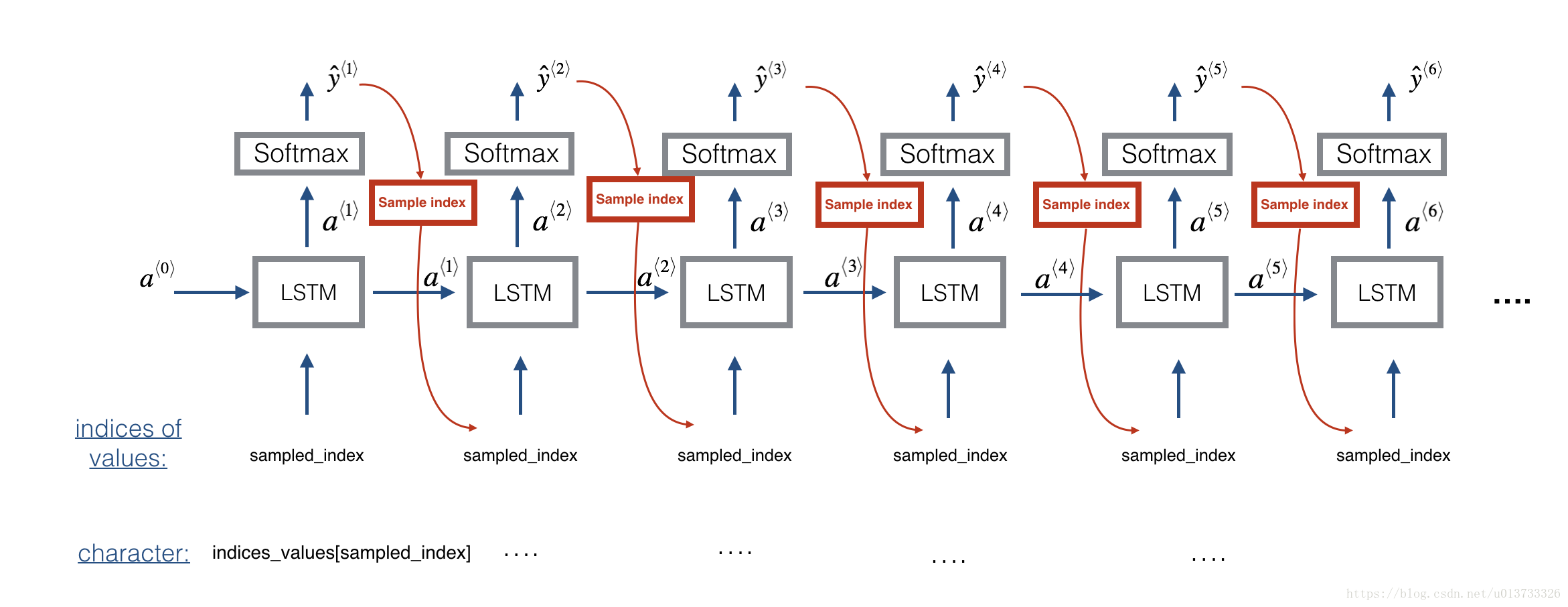
6.3预测和采样
根据6.2预测出来的模型的参数,根据以下方式进行预测和采样,其中模型的参数就是前面训练的模型的参数。
样本随机初始化的样本x输入到模型中,预测出的一个独热向量,你可以把它传递给下一个LSTM时间步,最后生成Y,选取具有最大生成概率的y作为最终的预测
6.4生成音乐
首先调用predict_and_sample()函数来生成音乐,并进行一些数据处理就可以得到最终的成品
out_stream = generate_music(inference_model)
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
from keras.models import load_model, Model
from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
from keras.initializers import glorot_uniform
from keras.utils import to_categorical
from keras.optimizers import Adam
from keras import backend as K
import numpy as np
import IPython
import time
import sys
from music21 import *
from grammar import *
from qa import *
from preprocess import *
from music_utils import *
from data_utils import *
# IPython.display.Audio('./data/30s_seq.mp3')
X, Y, n_values, indices_values = load_music_utils()
# print('shape of X:', X.shape)(60, 30, 78)
# print('number of training examples:', X.shape[0])60
# print('Tx (length of sequence):', X.shape[1])30
# print('total # of unique values:', n_values)78
# print('Shape of Y:', Y.shape)(30, 60, 78)
# 1.定义共享层为全局变量
reshapor = Reshape((1, 78)) # 2.2
# 使用64维隐藏状态的LSTM模块
n_a = 64
LSTM_cell = LSTM(n_a, return_state=True) # 2.3
densor = Dense(n_values, activation='softmax') # 2.4
# 2.创建模型实体
# 将x的每个时间步输入到reshapor-》LSTM_cell-》densor中,保存每个时间步的输出
def djmodel(Tx, n_a, n_values):
'''
实现64个是lstm单元的模型
:param Tx:语料库的长度
:param n_a:激活值的数量
:param n_values:音乐数据中唯一数据的数量
:return:model -- Keras模型实体
'''
# 定义输入数据的维度
X = Input((Tx, n_values))
# 定义a0,初始化隐藏状态
a0 = Input(shape=(n_a,), name="a0")
c0 = Input(shape=(n_a,), name="c0")
a = a0
c = c0
# 第一步:创建空的outputs列表来保存LSTM的所有时间步的输出
outputs = []
# 第二步:循环
for t in range(Tx):
# 2.1 从x中选择第t个时间步向量
x = Lambda(lambda x: X[:, t, :])(X)
# 2.2使用reshapor来对x进行重构为(1,n_values)
x = reshapor(x)
# 2.3单步传播
a, _, c = LSTM_cell(x, initial_state=[a, c])
# 2.4使用densor应用于lstm_cell的隐藏状态输出
out = densor(a)
# 2.5把预测值添加到output列表中
outputs.append(out)
# 第三步:创建模型实体
model = Model(inputs=[X, a0, c0], outputs=outputs)
return model
# 3.执行
# 获取模型
model = djmodel(Tx=30, n_a=64, n_values=78)
# 编译模型,Adam优化器与分类熵损失
opt = Adam(lr=0.01, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
# 初始化a0和c0,是lstm的初始化状态为0
m = 60
a0 = np.zeros((m, n_a))
c0 = np.zeros((m, n_a))
# 4.拟合模型
# 开始时间
start_time = time.clock()
# 开始拟合
# 将每个时间步作为一条训练数据,经过64个lstm,预测出的结果和他真正的下一个时间步进行loss,然后优化,求参数
model.fit([X, a0, c0], list(Y), epochs=100)
# 结束时间
end_time = time.clock()
# 计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium % 60)) + "秒")
# 5.预测和采样
# 根据上一个lstm_cell的参数,生成一个可以进行预测的模型,将数据输入lstm_cell中,参数上面已经训练好,
# 然后每个lstm_cell的输出会作为下一次模型的输入进行不断循环,得到outputs
def music_inference_model(LSTM_cell,densor,n_values=78,n_a=64,Ty=100):
'''
:param LSTM_cell:来自model()的训练过后的LSTM单元,是keras层对象
:param densor:来自model()的训练过后的"densor",是keras层对象
:param n_values: 整数,唯一值的数量
:param n_a:LSTM单元的数量
:param Ty:整数,生成的是时间步的数量
:return: inference_model -- Kears模型实体
'''
# 定义模型的输入维度
x0=Input(shape=(1,n_values))
# 定义c0,初始化隐藏状态
a0=Input(shape=(n_a,),name="a0")
c0=Input(shape=(n_a,),name="c0")
a=a0
c=c0
x=x0
# 步骤一:创建一个空的outputs列表来保存预测值
outputs=[]
# 步骤2:遍历Ty,生成所有时间步的输出
for t in range(Ty):
# 步骤2.1在lstm中单步传播
a,_,c=LSTM_cell(x,initial_state=[a,c])
# 步骤2.2使用densor应用于LSTM_cell的隐藏状态输出
out=densor(a)
# 步骤2.3预测值添加到“outputs"列表中
outputs.append(out)
# 根据out选择下一个值,并将x设置为所选值的一个独热编码
# 该值在下一步作为输入传递给LSTM_cell,
x=Lambda(one_hot)(out)
# 创建模型实体
inference_model=Model(inputs=[x0,a0,c0],outputs=outputs)
return inference_model
# 获取模型实体,模型被硬编码以产生50个值
inference_model = music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 50)
#创建用于初始化x和LSTM状态变量a和c的零向量。
x_initializer = np.zeros((1, 1, 78))
a_initializer = np.zeros((1, n_a))
c_initializer = np.zeros((1, n_a))
def predict_and_sample(inference_model,x_initializer=x_initializer,a_initializer=a_initializer,c_initializer=c_initializer):
'''
使用模型预测当前值的下一个值
:param inference_model: keras的实体模型
:param x_initializer: 初始化的独热编码,维度为(1, 1, 78)
:param a_initializer:LSTM单元的隐藏状态初始化,维度为(1, n_a)
:param c_initializer:LSTM单元的状态初始化,维度为(1, n_a)
:return:results -- 生成值的独热编码向量,维度为(Ty, 78)
indices -- 所生成值的索引矩阵,维度为(Ty, 1)
'''
# 步骤一:模型预测给定初始值的输出序列
pred=inference_model.predict([x_initializer,a_initializer,c_initializer])
# 步骤二:将pred转换为具有最大概率的索引数组np.array()
indices=np.argmax(pred,axis=-1)
# 步骤三:将索引转换为他们的一个独热编码
results=to_categorical(indices,num_classes=78)
return results,indices
results, indices = predict_and_sample(inference_model, x_initializer, a_initializer, c_initializer)
print("np.argmax(results[12]) =", np.argmax(results[12]))
print("np.argmax(results[17]) =", np.argmax(results[17]))
print("list(indices[12:18]) =", list(indices[12:18]))
# 6生成音乐
out_stream=generate_music(inference_model)
7.总结
比较sharpeare和音乐生成模型的异同















 1469
1469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









