







说到机器学习,初学者听到最多的就是 损失函数了吧
我对这个词也是一头雾水 好像今天一个定义明天又是一个定义 ,读了大量的文章和博客 终于有点起色 (感谢论坛各位大佬)
这里用自己的简单语言大致说下什么是损失函数 如果一个地方看不懂就换个博客看 总会有适合你的文章 万一这篇就是了呢
首先我们需要了解损失函数的定义是什么:衡量模型模型预测的好坏
可能这么说有点小小的抽象 ,那么在解释下,损失函数就是用来表现预测与实际数据的差距程度
比如你做一个线性回归,实际值和你的 预测值肯定会有误差,那么我们找到一个函数表达这个误差就是损失函数
和实际一样比如你是一个厨师大赛评委 几名厨师最后成绩由你确定 在你认为色香味都应该是100分才算冠军(这个100分就相当于实际值)
每个人都有自己的做菜方案和技巧,并且达到的效果也是不用的(这个就相当于预测值) 最后你是评委用你的一套规则判断他们多少分(你就是损失函数)
假设我们令真实值为Y 预测值为f(x) 损失函数为L(Y,f(x))他们的关系就是下图
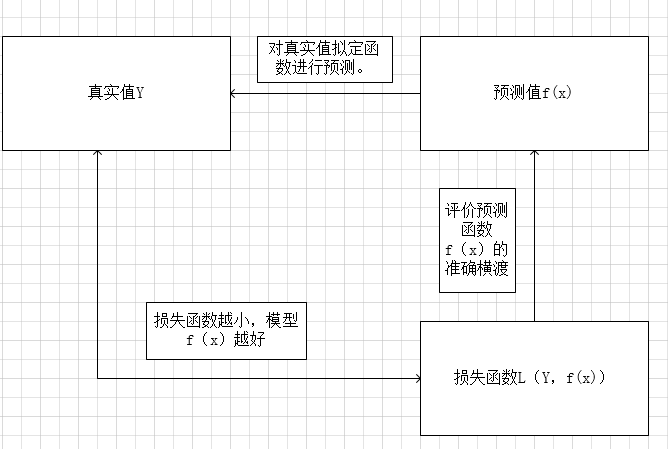
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
如果还是不是很清楚 可以看下论坛谋篇博客的一个小例子(我感觉挺好的)
http://blog.csdn.net/l18930738887/article/details/50615029
首先我们假设要预测一个公司某商品的销售量:
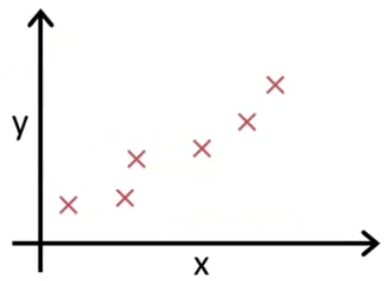
X:门店数 Y:销量
我们会发现销量随着门店数上升而上升。于是我们就想要知道大概门店和销量的关系是怎么样的呢?
我们根据图上的点描述出一条直线:
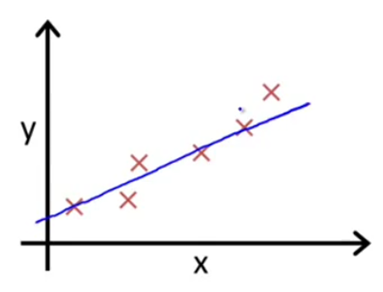
似乎这个直线差不多能说明门店数X和Y得关系了:我们假设直线的方程为Y=a0+a1X(a为常数系数)。假设a0=10 a1=3 那么Y=10+3X(公式1)
| X | 公式Y | 实际Y | 差值 |
| 1 | 13 | 13 | 0 |
| 2 | 16 | 14 | 2 |
| 3 | 19 | 20 | -1 |
| 4 | 22 | 21 | 1 |
| 5 | 25 | 25 | 0 |
| 6 | 28 | 30 | -2 |
我们希望我们预测的公式与实际值差值越小越好,所以就定义了一种衡量模型好坏的方式,即损失函数(用来表现预测与实际数据的差距程度)。于是乎我们就会想到这个方程的损失函数可以用绝对损失函数表示:
公式Y-实际Y的绝对值,数学表达式: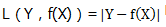
上面的案例它的绝对损失函数求和计算求得为:6
为后续数学计算方便,我们通常使用平方损失函数代替绝对损失函数:
公式Y-实际Y的平方,数学表达式:L(Y,f(X))= 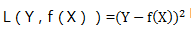
上面的案例它的平方损失函数求和计算求得为:10
以上为公式1模型的损失值。
假设我们再模拟一条新的直线:a0=8,a1=4
| X | 公式Y | 实际Y | 差值 |
| 1 | 12 | 13 | -1 |
| 2 | 16 | 14 | 2 |
| 3 | 20 | 20 | 0 |
| 4 | 24 | 21 | 3 |
| 5 | 28 | 25 | 3 |
| 6 | 32 | 30 | 2 |
公式2 Y=8+4X
绝对损失函数求和:11 平方损失函数求和:27
公式1 Y=10+3X
绝对损失函数求和:6 平方损失函数求和:10
从损失函数求和中,就能评估出公式1能够更好得预测门店销售。
统计学习中常用的损失函数有以下几种:
(1) 0-1损失函数(0-1 lossfunction):
L(Y,f(X))={1,0,Y≠f(X)Y=f(X)
(2) 平方损失函数(quadraticloss function)
L(Y,f(X))=(Y−f(X))2
(3) 绝对损失函数(absoluteloss function)
L(Y,f(X))=|Y−f(X)|
(4) 对数损失函数(logarithmicloss function) 或对数似然损失函数(log-likelihood loss function)
L(Y,P(Y|X))=−logP(Y|X)
损失函数越小,模型就越好。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









