








 超级会员免费看
超级会员免费看

0. 认识博弈论
博弈论在很多社会问题中都有涉及到,它是一种用数学方法研究相互影响的主体间的关系,求得最优的发展策略的理论。它的研究对象包含博弈主体、博弈策略、信息集合和博弈结果等。它总结出了社会群体向着有利于自身的最优策略演化的规律,用数学模型展示出了社会群体之间的竞合博弈问题。
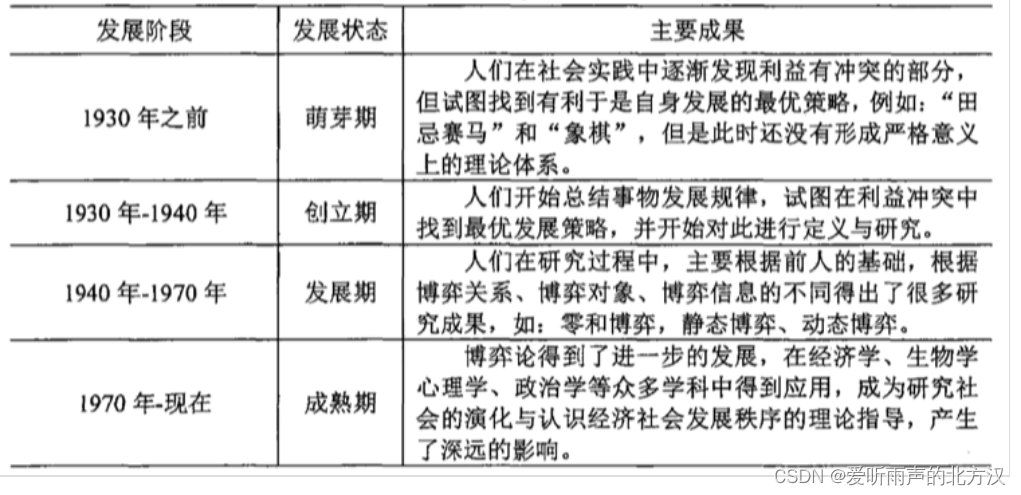
一般, 我们研究的博弈论是静态的,且假设往往参与博弈的主体都是完全理性的,但是实际上上述两个假设在实际上往往不是很准确和贴合现实的,那么从演化的视角,就出现了“演化博弈论”。
1. 认识演化博弈论
首先,演化博弈论与传统的博弈理论相比,有一个更加贴近现实的应用背景:认为现实生活中人不可能达到完全理性,也不要求完全信息的条件。
一般的演化博弈理论具有如下特征:
它的研究对象是随着时间变化的某一群体,理论探索的目的是为了理解群体演化的动态过程,并解释说明为何群体将达到目前的这一状态以及如何达到。影响群体变化的因素既具有一定的随机性和扰动现象(突变),又有通过演化过程中的选择机制而呈现出来的规律性。大部分演化博弈理论的预测或解释能力在于群体的选择过程,通常群体的选择过程

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5683
5683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











