







机器学习技法 Lecture13: Deep Learning
Deep Neural Network
再来看一下神经网络的结构。每一层网络都相当于是从数据中提取某种模式特征。至于需要多少层网络多少个神经元,可以从两方面看。主观上看只要按照自己设计就可以,找客观标准的话使用交叉验证也可以。

对于神经网络结构的设计是一个核心问题。对比一下深层与浅层的神经网络:

它们有各自不同的优缺点。对于深层的神经网络来说,每一层在提取特征的时候可能只需要做更简单的事情,这样一层层递进下来就能够得到足够好足够复杂的特征。特别是在机器视觉的领域比较适合这个结构。
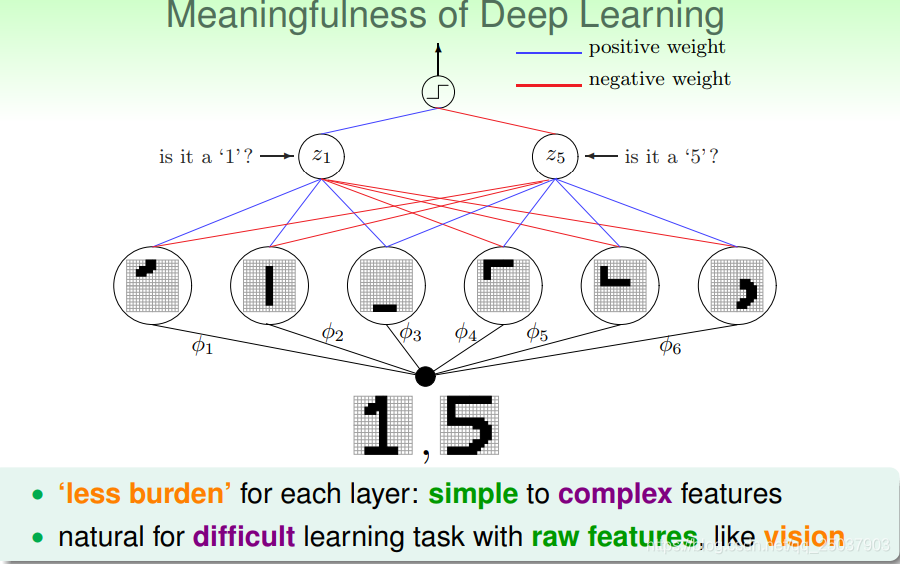
对于深度神经网络来说,有几个比较重点的挑战与对应解决的技巧:

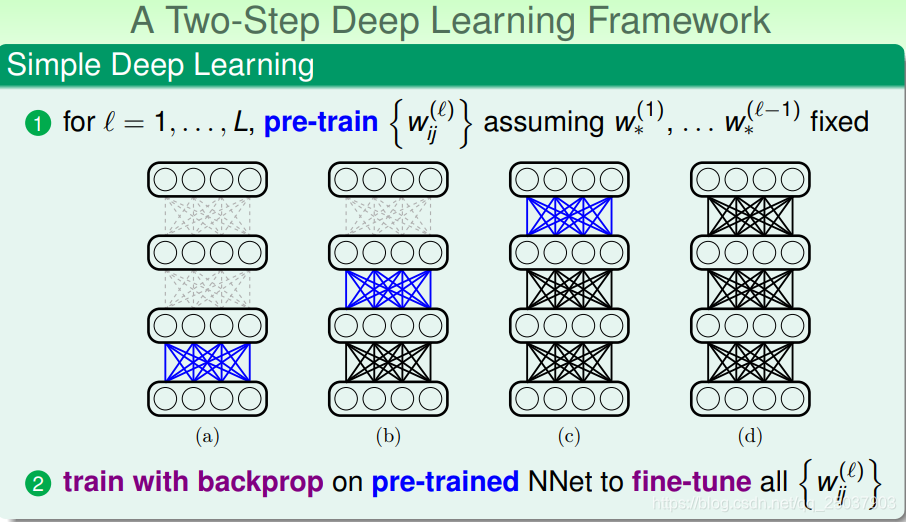
训练一个深度神经网络大致有两个步骤。第一个先是对每一层的权重做一下预训练,之后再使用backprop对预训练之后的网络进行fine-tune。
Autoencoder
如果把神经网络看作是一个编码器,那么神经网络里的权重就相当于是用来做特征转换。那么比较好的权重就是能够做保存信息的编码的权重,这样下一层神经网络与前一层会有同样的信息,只不过是不同的表现形式。能够保存信息的证明就是从编码后的信息中能够解码出原来的内容。
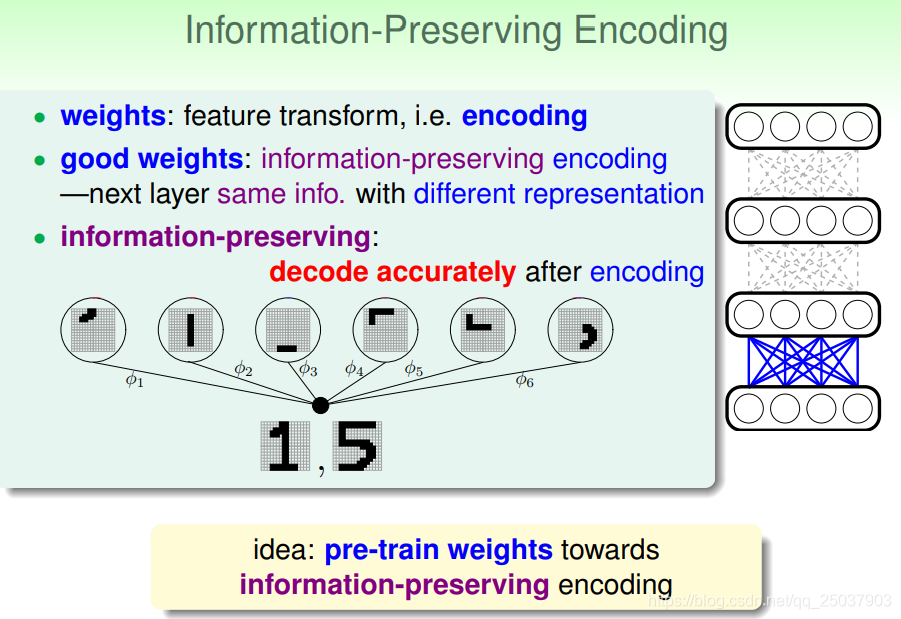
可以用预训练让神经网络做到这一点。
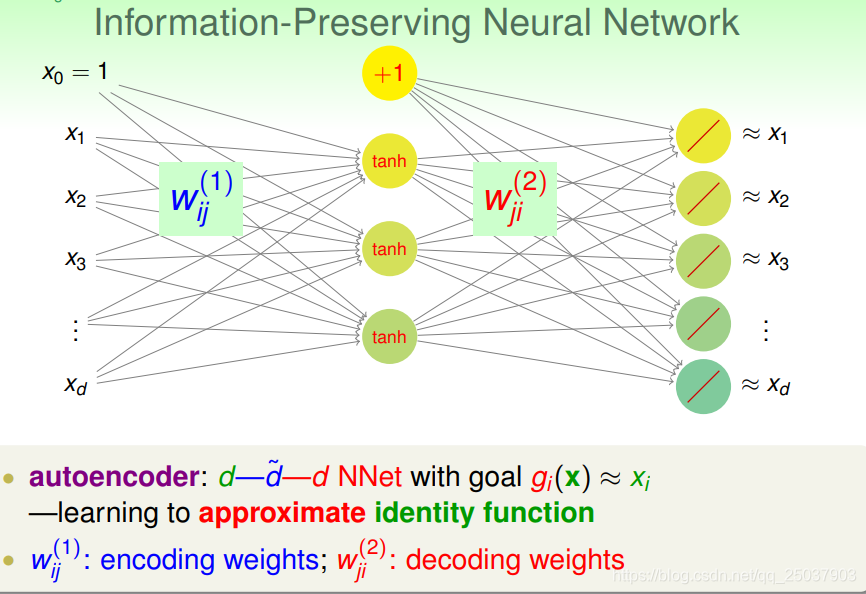
在这里有输入层,隐藏层与输出层。要想完成目标,就要让输出层的输出与输入层的输入尽可能相等。也就是相当于是用神经网络模拟一个单位矩阵。第一层的权重是编码,第二层是解码。
至于为什么要去近似一个单位矩阵,这是因为如果能够拟合出这样的函数,那么就说明其中有一些隐藏结构能够保存输入x的信息。这在机器学习里很有用。

这样能够通过近似单位函数来进行表示学习的结构叫autoencoder。

简单的autoencoder就是三层神经网络分别是输入,隐藏层与输出层。最后用平方误差作为error。它有几个特点:

autoencoder可以用在神经网络的预训练中。
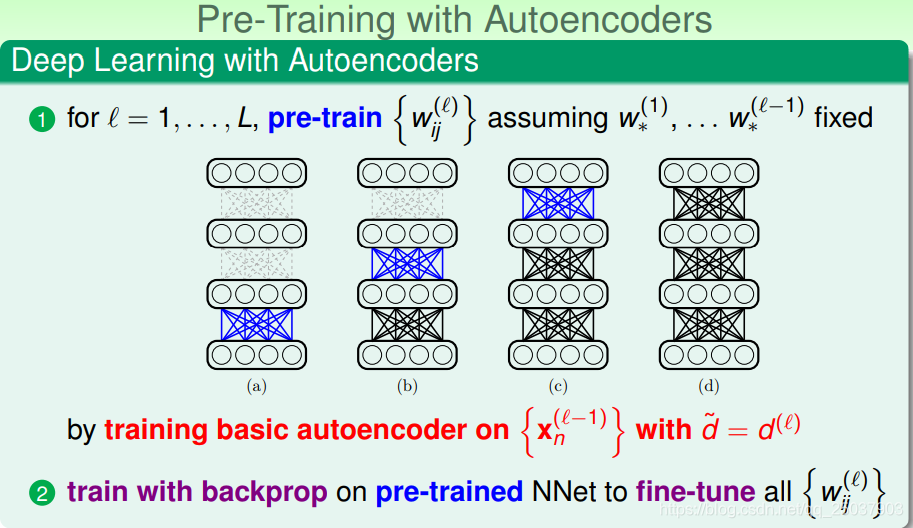
而且很多比较成功的预训练使用了更fancy的autoencoder,加了不同的正则项与结构进去。
Denosing Autoencoder
在深度学习中有几个常用的正则方法:

第一个是指在权重上做限制。比如限制前后两层系数相同等等。回到以前的一个图来分析过拟合的原因:
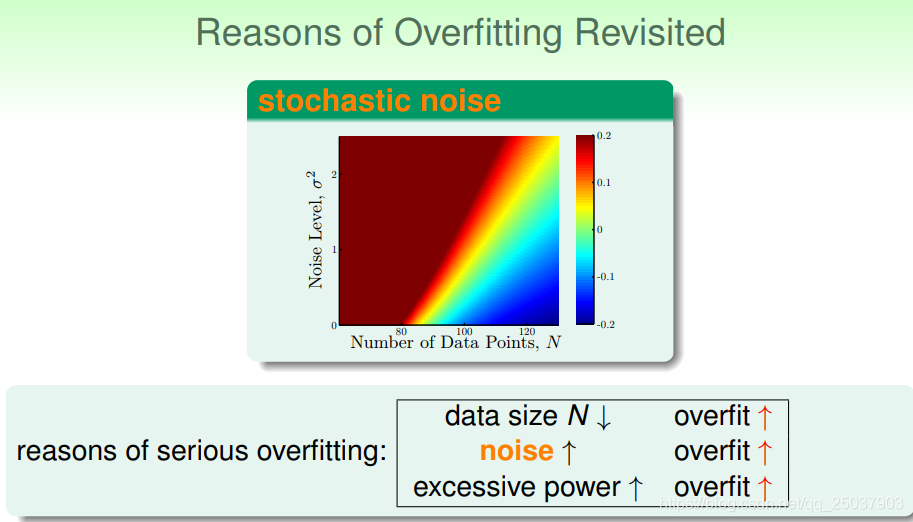
如何才能解决噪声带来的影响呢?一个直接简单的方法就是使用数据清洗或调整。还有个想法可能是在数据中加噪声。

在数据中加噪声如何能够解决噪声的问题?是因为一个比较健壮的autoencoder应该能够解决带噪声的输入x的自动编解码的问题。这样在预训练之后就相当于去掉了噪声对于神经网络的影响:

所以使用额外的噪声可以用来做正则项,这样能够增强神经网络抵抗噪声的能力,也就更不容易过拟合。
Principal Component Analysis
神经网络是一个非线性的结构,对应的autoencoder也是非线性的。但实际上也可以使用线性的autoencoder,这样可能更简单。
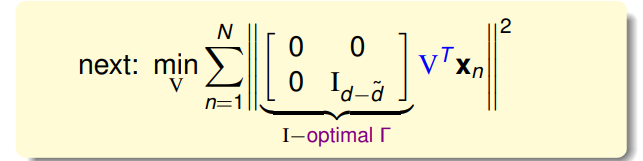
对于这样的线性autoencoder做以下的设定:

也就是最终得到这样的假设:

于是我们得到这样一个error function:

想要最小化这样一个式子来得到W的结果看起来非常困难,但也不是不能做。根据线性代数的结论可以把
W
W
T
WW^{T}
WWT进行特征值分解:

其中V是一个正交矩阵,而
τ
\tau
τ是一个对角矩阵。下面就求这两个矩阵即可:

根据矩阵分解的结果,可以先将前一个V去掉,而不影响目标函数的最小化。然后因为
I
−
τ
I-\tau
I−τ的对角矩阵以及矩阵的秩的特点,可以求得
τ
\tau
τ的结果。剩下的就是求V。
最小化这样的式子相当于最大化:
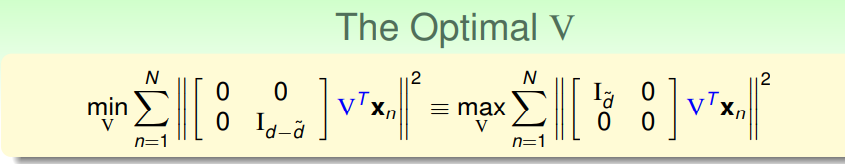
假设
d
^
\widehat{d}
d
是1,那么就是求:

使用拉格朗日乘子法就能得到v的结果就是矩阵
X
T
X
X^{T}X
XTX最大特征值对应的特征向量。而其余维度的v也都是这样:

因此这样一个线性的autoencoder就相当于是投影映射到最能够匹配{
x
n
}
x_{n}\}
xn}的一个正交模式w:

其实这样的一个线性autoencoder与PCA是非常一致的,不过在刚开始的时候需要对x进行一个处理:

这样的方法常用在需要降维的数据预处理之中。















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









