







MobileNetV1是一种既降低了模型大小,又加快了推理速度的模型。但是不太好训练,实测需要先用较大学习率(0.1~0.01左右)训(SGD).
先讲为什么MobileNet可以加快推理速度:
上图:
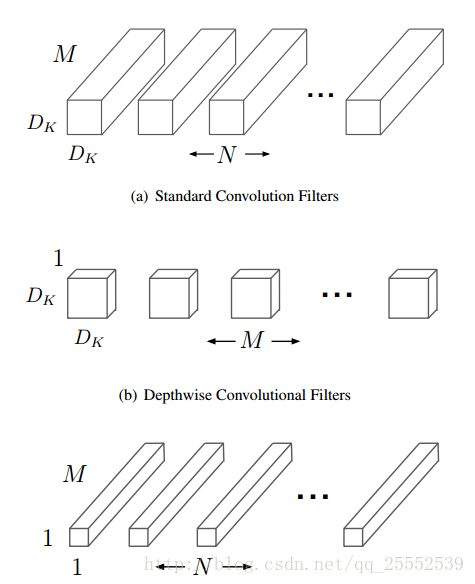
首先,假设上图是原本的VGG结构,输入feature map 有M个channel , Df * Df 是输出 feature map的大小channel数为N ,Dk * Dk 是的卷积核大小有N个。
传统的VGG卷积部分的计算量 : Dk * Dk * M * N * Df * Df
为什么是这样呢:
首先 , 卷积核会对输入的每个 featrue map的做卷积,每feature map的卷积计算量 主要看生成的feature map大小。
由于输出feature map的每个像素点,都是一次卷积运算得到的。故输出为Df * Df 时,则每个feature map做了
Df * Df次卷积运算。
而每次卷积运算占的运算量是多少呢?和卷积核大小有关 : Dk * Dk (比较容易理解 卷积就是矩阵乘矩阵,
3*3矩阵相乘要算9次乘法)
所以 , 1个卷积核的计算量 : Dk * Dk * Df * Df *M 。N 个卷积核 ,故总计算量为 :Dk * Dk * Df * Df * M * N 。
MobileNet卷积计算:
当输入为 M 个通道的 feature map 时, 则用 M 个 (与输入通道相同,且不进行通道间的叠加 ,一一对应进行卷积)
Dk * Dk 卷积做运算, 输出feature map大小为 Df * Df, 运算量为: Df * Df * Dk * Dk * M 。
这 M 个 feature map 在传统卷积时是要相互叠加的,(传统的卷积是用N个卷积核依次卷积输入的所有(也就是M个)
feature map,然后累加这M个结果,最终得到N个累加后的结果)
注意 : 这里卷积用 M 个,即与输入feature map通道数相同 ,而不是输出通道数 N 。















 2665
2665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









