









环境
python 3.6 + TensorFlow 1.13.1 + Jupyter Notebook
反向传播
即复合函数求导,链式法则为实现基础。


神经网络存在的问题及优化方法
存在问题
1、每次都在整个数据集上计算Loss和梯度,导致:
(1)计算量大;
(2)内存可能承载不了;
2、梯度方向确定的时候,仍然是每次走一个单位步长,导致:速度太慢。
优化方法
随机梯度下降
每次只使用一个样本。
缺点:不能反应整个数据集的梯度方向,导致每次训练的收敛速度较慢。
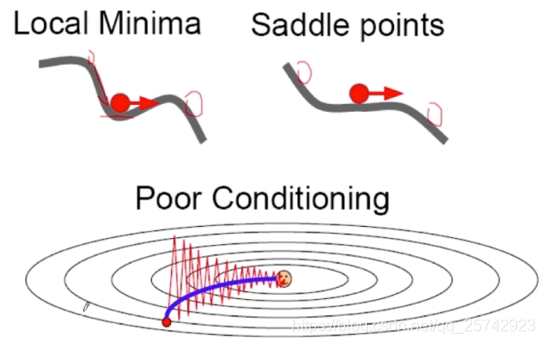
Mini-Batch梯度下降
每次使用小部分随机选择的数据进行训练。
缺点:梯度下降存在震荡问题(Mini-Batch越大,这个问题越不明显);存在局部极值和saddle point问题。


动量梯度下降
解决了收敛速度慢、震荡、局部极值、saddle point的问题。
(1)开始训练时,积累动量,加速训练;
(2)局部极值附近震荡时,梯度为0,由于动量,跳出陷阱;
(3)梯度改变方向的时候,动量缓解动荡。

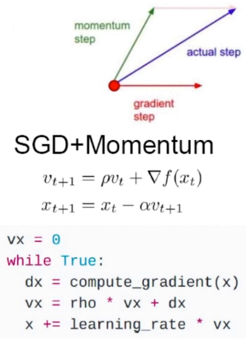
解决方法
主要问题
神经网络遇到的最主要问题:参数过多,导致:
(1)计算量大;
(2)容易过拟合,需要更多的训练数据;
(3)收敛到较差的局部极值。
主要解决方法
卷积:
(1)局部连接(全连接变为局部连接,减少数据量):图像的区域性;
(2)参数共享:图像特征与位置无关。


相关计算
卷积计算:每个位置进行内积运算。
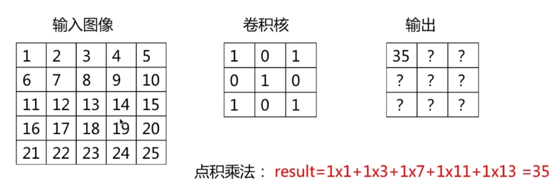
输出size = 输入size – 卷积核size + 1
步长:卷积核每步滑动的长度(卷积的默认步长为1)。
Padding:使输出size不变。
(下图的“输出size = 输入size – 卷积核size + 1”,输入size是指已经加上Padding的size)

输出size = 输入size + Padding * 2 – 卷积核size + 1
卷积及卷积核
卷积核的物理含义
可认为卷积核是用于提取某个特征的,输入图像若具有卷积核所标识的特征,则输出值较大,否则较小。
卷积处理多通道生成单通道图像

卷积处理多通道生成多通道图像
即增加多个参数不共享的卷积核。

激活函数
激活函数的特征(常用ReLU,快速):
(1)具有单调性;
(2)非线性函数(原因:神经网络层级之间全连接相当于矩阵运算,矩阵的操作具有合并性,若为线性运算,多层神经网络相当于单层神经网络)。

卷积核的参数

n为输入图像大小。
池化
基本计算
池化默认步长与核相等,卷积默认步长为1。
(1)最大值池化;(2)平均值池化。


池化的特点
精度与计算量的trade off。
(1)常使用不重叠、不补零;
(2)没有用于求导的参数;
(3)池化层参数为步长和池化核大小;
(4)用于减少图像尺寸,从而减少计算量;
(5)一定程度解决平移鲁棒;
(6)损失了空间位置精度。
全连接
全卷积之后不能再加卷积和池化层。
全连接层的参数数目占据整个神经网络参数的大部分(约60%~80%)。
(1)将上一层输出展开并连接到每一个神经元上;
(2)即普通神经网络的层;
(3)相比于卷积层,参数数目较大。
参数数目 = Ci * Co
(Ci/Co为输入输出通道数目)
卷积神经网络结构
卷积神经网络
卷积神经网络 = 卷积层 + 池化层 + 全连接层

图像 --> 图像的操作:去除全连接层;
小图 --> 大图:反卷积。
全卷积神经网络
全卷积神经网络 = 卷积层 + 池化层

代码
TensorFlow实现:卷积层与池化层
conv1 = tf.layers.conv2d(x_image,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv1')
# 16 * 16
pooling1 = tf.layers.max_pooling2d(conv1,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool1')
conv2 = tf.layers.conv2d(pooling1,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv2')
# 8 * 8
pooling2 = tf.layers.max_pooling2d(conv2,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool2')
conv3 = tf.layers.conv2d(pooling2,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv3')
# 4 * 4 * 32
pooling3 = tf.layers.max_pooling2d(conv3,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool3')TensorFlow实现:全连接层
# [None, 4 * 4 * 32]
flatten = tf.layers.flatten(pooling3)TensorFlow实现:卷积神经网络
x = tf.placeholder(tf.float32, [None, 3072])
y = tf.placeholder(tf.int64, [None])
# [None], eg: [0,5,6,3]
x_image = tf.reshape(x, [-1, 3, 32, 32])
# 32*32
x_image = tf.transpose(x_image, perm=[0, 2, 3, 1])
conv1 = tf.layers.conv2d(x_image,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv1')
# 16 * 16
pooling1 = tf.layers.max_pooling2d(conv1,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool1')
conv2 = tf.layers.conv2d(pooling1,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv2')
# 8 * 8
pooling2 = tf.layers.max_pooling2d(conv2,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool2')
conv3 = tf.layers.conv2d(pooling2,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv3')
# 4 * 4 * 32
pooling3 = tf.layers.max_pooling2d(conv3,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool3')
# [None, 4 * 4 * 32]
flatten = tf.layers.flatten(pooling3)
y_ = tf.layers.dense(flatten, 10)
loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)
# y_ -> sofmax
# y -> one_hot
# loss = ylogy_
# indices
predict = tf.argmax(y_, 1)
# [1,0,1,1,1,0,0,0]
correct_prediction = tf.equal(predict, y)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64))
with tf.name_scope('train_op'):
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)参考资料
图片、内容引自:https://coding.imooc.com/class/259.html















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









