







 超级会员免费看
超级会员免费看
Abstract
我们提出了一种新方法,用于密集3D体素网格的实例标签分割。我们的目标是使用深度传感器或多视图立体方法获取的体积场景表示,并使用语义3D重建或场景完成方法进行处理。主要任务是学习有关单个目标实例的形状信息,以便准确地分离它们,包括连接的和不完全扫描的目标。我们使用多任务学习策略解决了3D实例标记问题。第一个目标是学习一个抽象特征嵌入,它将具有相同实例标签的体素彼此靠近,同时将具有不同实例标签的集群彼此分开。第二个目标是通过密集估计每个体素的实例质心的方向信息来学习实例信息。这对于在聚类后处理步骤中找到实例边界以及对第一个目标的分割质量进行评分特别有用。合成和真实世界的实验都证明了我们方法的可行性和优点。事实上,它在ScanNet3D实例分割基准[5]上实现了最先进的性能。
1.Introduction
计算机视觉研究的中心目标是高级场景理解。2D图像的最新方法学进展使得各种计算机视觉问题的可靠结果成为可能,包括图像分类[24、44、48]、图像分割[1、32、42]、目标检测[30、39、41]和实例二维图像中的分割[9,18,37]。此外,现在可以使用低成本深度传感器[20,35,47,55]或使用基于图像的3D重建算法[12,22,43]恢复高度详细的3D几何形状。结合这两个概念,已经开发了许多算法用于3D场景和目标分类[33、45、51]、3D目标检测[26、52],以及联合3D重建和语义标记[4、6、7、25、49]。
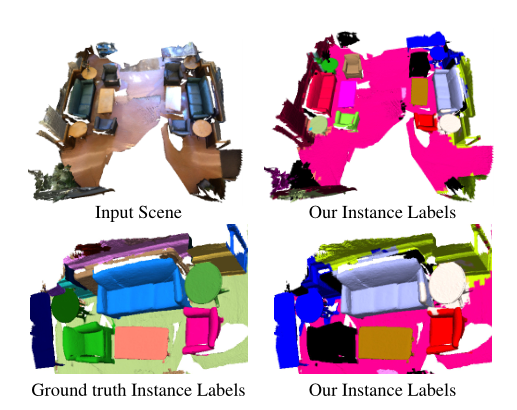
图1.我们方法的示例结果。我们提出的方法将3D点云作为输入,并输出场景中每个目标唯一的实例标签。标签是通过学习一个度量来生成的,该度量将同一目标实例的部

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











