







为了能够更加直观的了解Prometheus Server,接下来我们将在本地部署一个Prometheus Server实例,并且配合Node Exporter程序实现对本地主机指标的监控。
#####部署prometheus server
Prometheus基于Golang编写,因此不存在任何的第三方依赖。这里只需要下载,解压并且添加基本的配置即可正常启动Prometheus Server。
到prometheus.io 下载最新的部署包,目前最新的版本为2.3.2。
curl -LO https://github.com/prometheus/prometheus/releases/download/v2.3.2/prometheus-2.3.2.linux-amd64.tar.gz
tar zxvf prometheus-2.3.2.linux-amd64.tar.gz
cp prometheus-2.3.2.linux-amd64/prometheus /usr/local/bin/
cp prometheus-2.3.2.linux-amd64/promtool /usr/local/bin/
sudo mkdir -p /data/prometheus
解压后当前目录会包含默认的Prometheus配置文件promethes.yml,拷贝配置文件到/etc/prometheus/prometheus.yml:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
启动prometheus服务:
# prometheus --config.file=/usr/local/prometheus/prometheus-file-sd.yml --storage.tsdb.path=/data --web.enable-lifecycle
prometheus --config.file=/usr/local/prometheus/prometheus-file-sd.yml --storage.tsdb.path=/data --storage.tsdb.retention=15d --web.listen-address="0.0.0.0:9090" --web.console.templates=/usr/local/prometheus/consoles/ --web.console.libraries=/usr/local/prometheus/console_libraries/ --web.max-connections=2048 --alertmanager.notification-queue-capacity=20000 --query.max-concurrency=256 --log.level=info > prom.log 2>&1 &
#--web.enable-lifecycle 此参数 可以通过HTTP API向server端发送POST请求,例如:curl -X POST http://localhost:9090/-/reload
#--storage.tsdb.path 此参数制定存储数据路径
正常的情况下,你可以看到以下输出内容:
level=info ts=2018-03-11T13:38:06.302110924Z caller=main.go:225 msg="Starting Prometheus" version="(version=2.3.2, branch=HEAD, revision=85f23d82a045d103ea7f3c89a91fba4a93e6367a)"
level=info ts=2018-03-11T13:38:06.302226312Z caller=main.go:226 build_context="(go=go1.9.2, user=root@6e784304d3ff, date=20180119-12:07:34)"
level=info ts=2018-03-11T13:38:06.302258309Z caller=main.go:227 host_details=(darwin)
level=info ts=2018-03-11T13:38:06.302283524Z caller=main.go:228 fd_limits="(soft=10240, hard=9223372036854775807)"
level=info ts=2018-03-11T13:38:06.306850232Z caller=main.go:499 msg="Starting TSDB ..."
level=info ts=2018-03-11T13:38:06.30688713Z caller=web.go:383 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2018-03-11T13:38:06.316037503Z caller=main.go:509 msg="TSDB started"
level=info ts=2018-03-11T13:38:06.316106814Z caller=main.go:585 msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
level=info ts=2018-03-11T13:38:06.317645234Z caller=main.go:486 msg="Server is ready to receive web requests."
level=info ts=2018-03-11T13:38:06.317679086Z caller=manager.go:59 component="scrape manager" msg="Starting scrape manager..."
启动完成后,可以通过http://server_ip:9090访问Prometheus的UI界面。
#####部署node_exporter
在Prometheus的架构设计中,Prometheus Server主要负责数据的收集,存储并且对外提供数据查询支持。而实际的监控样本数据的收集则是由Exporter完成。Exporter可以是一个独立运行的进程,对外暴露一个用于获取监控数据的HTTP服务。 Prometheus Server只需要定时从这些Exporter暴露的HTTP服务获取监控数据即可。
为了能够采集到主机的运行指标。这里需要使用node exporter,node exporter可以获取到所在主机大量的运行数据,典型的包括CPU、内存,磁盘、网络等等监控样本。
node exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
curl -OL https://github.com/prometheus/node_exporter/releases/download/v0.15.2/node_exporter-0.15.2.darwin-amd64.tar.gz
tar -xzf node_exporter-0.15.2.darwin-amd64.tar.gz
运行node exporter:
cd node_exporter-0.15.2.darwin-amd64
cp node_exporter-0.15.2.darwin-amd64/node_exporter /usr/local/bin/
node_exporter --collector.interrupts --collector.mountstats --collector.systemd --collector.tcpstat --web.listen-address=":9100" --web.telemetry-path="/metrics" --log.level="info" --log.format="logger:syslog?appname=node_exporter&local=6" > prom_node.log 2>&1 &
启动成功后,可以看到以下输出:
INFO[0000] Starting node_exporter (version=0.15.2, branch=HEAD, revision=98bc64930d34878b84a0f87dfe6e1a6da61e532d) source="
node_exporter.go:43"
INFO[0000] Build context (go=go1.9.2, user=root@d5c4792c921f, date=20171205-14:51:43) source="node_exporter.go:44"
INFO[0000] No directory specified, see --collector.textfile.directory source="textfile.go:57"
INFO[0000] Enabled collectors: source="node_exporter.go:50"
INFO[0000] - time source="node_exporter.go:52"
INFO[0000] - meminfo source="node_exporter.go:52"
INFO[0000] - textfile source="node_exporter.go:52"
INFO[0000] - filesystem source="node_exporter.go:52"
INFO[0000] - netdev source="node_exporter.go:52"
INFO[0000] - cpu source="node_exporter.go:52"
INFO[0000] - diskstats source="node_exporter.go:52"
INFO[0000] - loadavg source="node_exporter.go:52"
INFO[0000] Listening on :9100 source="node_exporter.go:76"
访问http://localhost:9100/可以看到以下页面:
####Node Exporter监控指标
访问http://localhost:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据,如下所示:
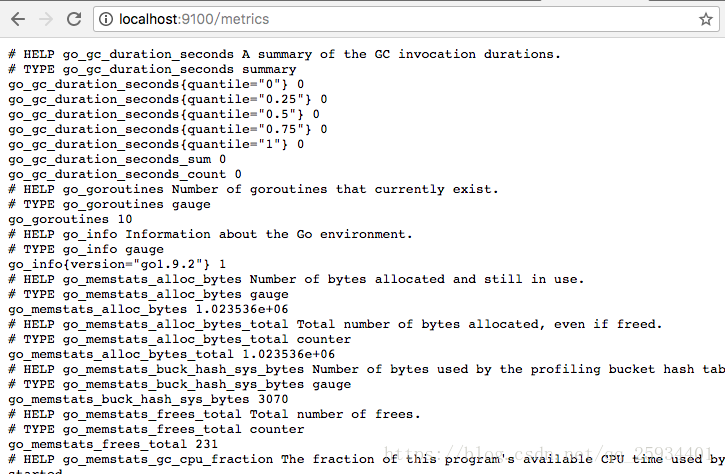
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统CPU使用量
- node_disk_*:磁盘IO
- node_filesystem_*:文件系统用量
- node_filesystem_readonly #系统是否可读
- node_load1:系统负载
- node_memeory_*:内存使用量
- node_network_*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
具体的监控指标报警策略:
groups:
- name: hostStatsAlert
rules:
- alert: Host Cpu Usage Alert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: Host Mem Usage Alert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
- alert: Node Filesystem Usage
expr: (node_filesystem_size{device="rootfs"} - node_filesystem_free{device="rootfs"}) / node_filesystem_size{device="rootfs"} * 100 > 91
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: High Filesystem usage detected"
description: "{{$labels.instance}}: Filesystem usage is above 91% (current value is: {{ $value }}"
- alert: Instance Down
expr: up == 0
for: 1m
labels:
severity: critital
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: System becomes read-only
expr: node_filesystem_readonly{mountpoint="/"} == 1
for: 1m
labels:
severity: critital
annotations:
summary: "The instance {{ $labels.instance }} is system becomes read-only"
description: "{{ $labels.instance }} of job {{ $labels.job }} is system becomes read-only for more than 1 minutes."
- alert: Network transmit or receive Usage Alert
expr: sum(irate(node_network_receive_bytes{ device!="lo"}[2m])) by (instance) / 1024 >5000
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: High Network request"
description: "{{$labels.instance}}: Network request greater than 5000 (current value is: {{ $value }}"
- alert: Maximum number of open file descriptors Alert
expr: process_max_fds < 1024
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: Maximum number of open file is default(1024)"
description: "{{$labels.instance}}: Maximum number of open file is default (current value is: {{ $value }}"
- alert: Maximum number of open file descriptors Alert
expr: process_open_fds > 10000
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: Maximum number of open file greater than 10000"
description: "{{$labels.instance}}: Maximum number of open file greater than 10000 (current value is: {{ $value }}"
#- name: k8sStatsAlert
- alert: K8s Node Down
expr: up{job=~"kubernetes-apiservers|kubernetes-nodes|kubernetes-cadvisor"} == 0
expr: kube_node_status_condition{condition="Ready",status!="true"} == 1
for: 1m
labels:
severity: critital
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: K8s 的集群节点内存或磁盘资源短缺
expr: kube_node_status_condition{condition=~"OutOfDisk|MemoryPressure|DiskPressure",status!="false"}==1
for: 1m
labels:
severity: critital
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: K8s PVC Lost
expr: kube_persistentvolumeclaim_status_phase{phase="Lost"}==1
for: 1m
labels:
severity: critital
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: K8s Pod Status Failed or Unknown
expr: kube_pod_status_phase{phase=~"Failed|Unknown"}==1
for: 1m
labels:
severity: critital
annotations:
summary: "Instance {{ $labels.pod }} down"
description: "{{ $labels.pod }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: The Pod container restarted in the last 30 minutes
expr: changes(kube_pod_container_status_restarts_total[30m])>0
for: 40m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.pod }} down"
description: "{{ $labels.pod }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: The current number of thread connections in Tomcat greater than 800
expr: jvm_threads_current > 800
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} "
description: "{{$labels.instance}}: The current number of thread connections in Tomcat greater than 500 (current value is: {{ $value }}"
- alert: Tomcat_JVM_Heap_Too_High
expr: jvm_memory_bytes_used{area="heap"} / jvm_memory_bytes_max{area="heap"} > 0.85
for: 15m
labels:
severity: critical
annotations:
description: "The heap in {{ $labels.instance }} is over 85% for 15m."
summary: "Instance {{ $labels.instance }} "
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
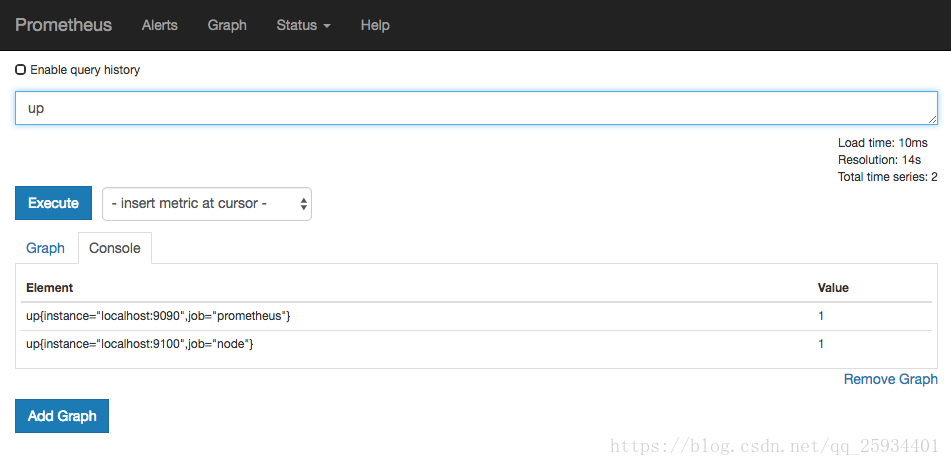
up{instance=“localhost:9090”,job=“prometheus”} 1
up{instance=“localhost:9100”,job=“node”} 1
其中“1”表示正常,反之“0”则为异常。
####数据与可视化
使用Prometheus UI
通过Prometheus UI用户可以利用PromQL实时查询监控数据,并且支持一些基本的数据可视化能力。进入到Prometheus UI,切换到Graph标签
通过PromQL则可以直接以可视化的形式显示查询到的数据。例如,查询主机负载变化情况,可以使用:
node_load1
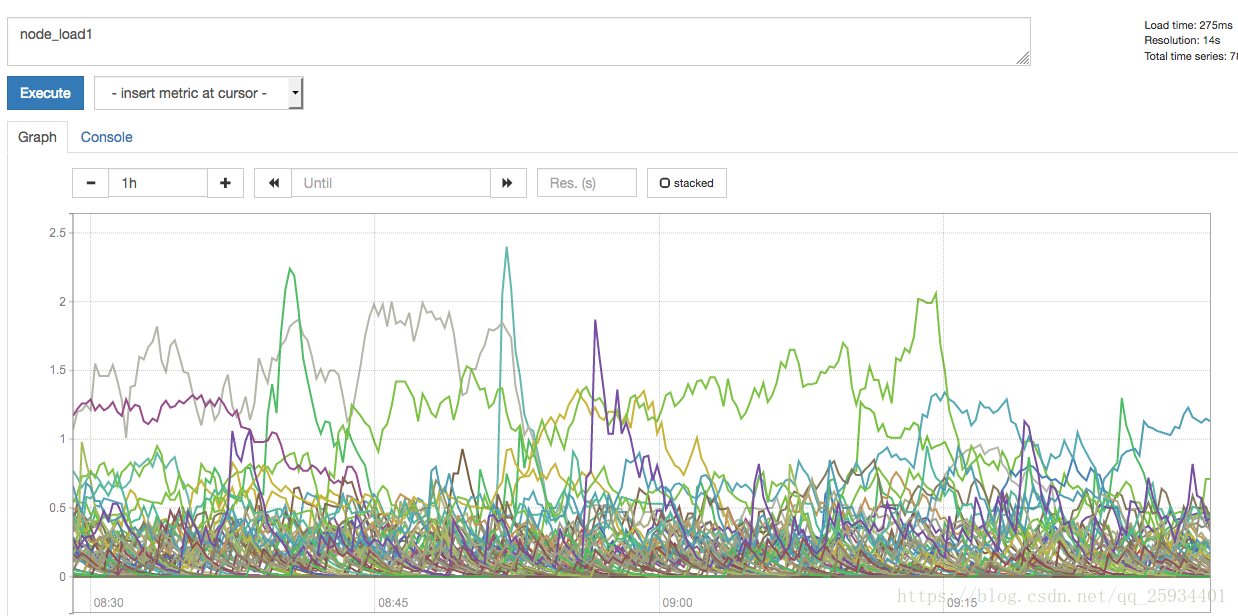
查询主机CPU的使用率,由于node_cpu的数据类型是Counter,计算使用率需要使用rate()函数:
rate(node_cpu[2m])
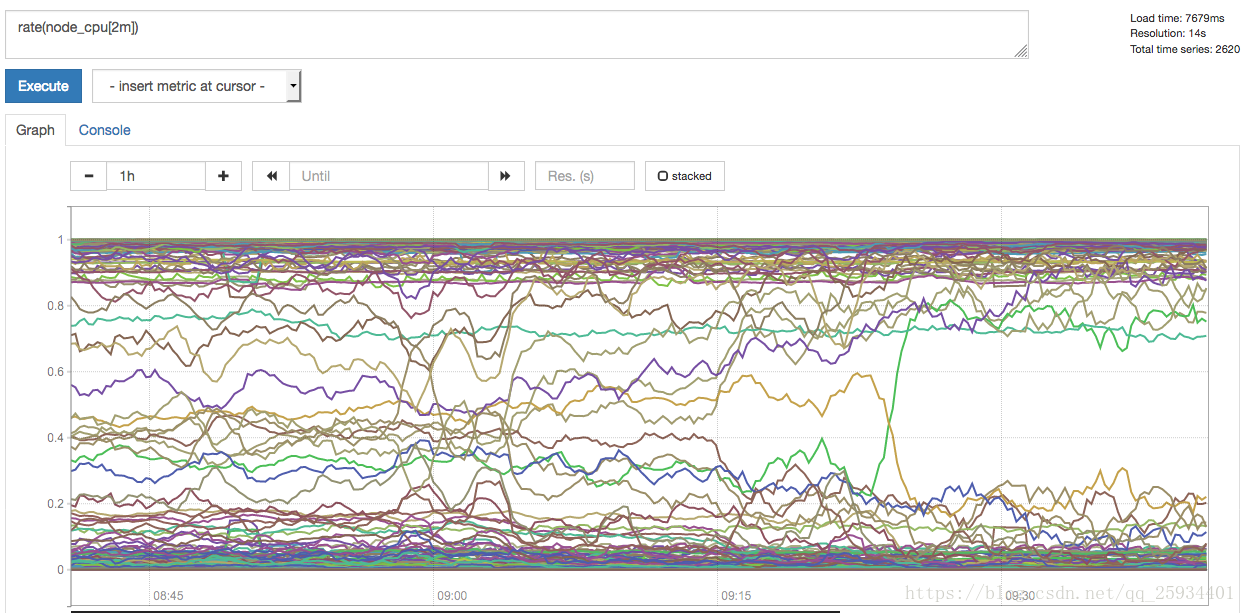
这时如果要忽略是哪一个CPU的,只需要使用without表达式,将标签CPU去除后聚合数据即可:
avg without(cpu) (rate(node_cpu[2m]))
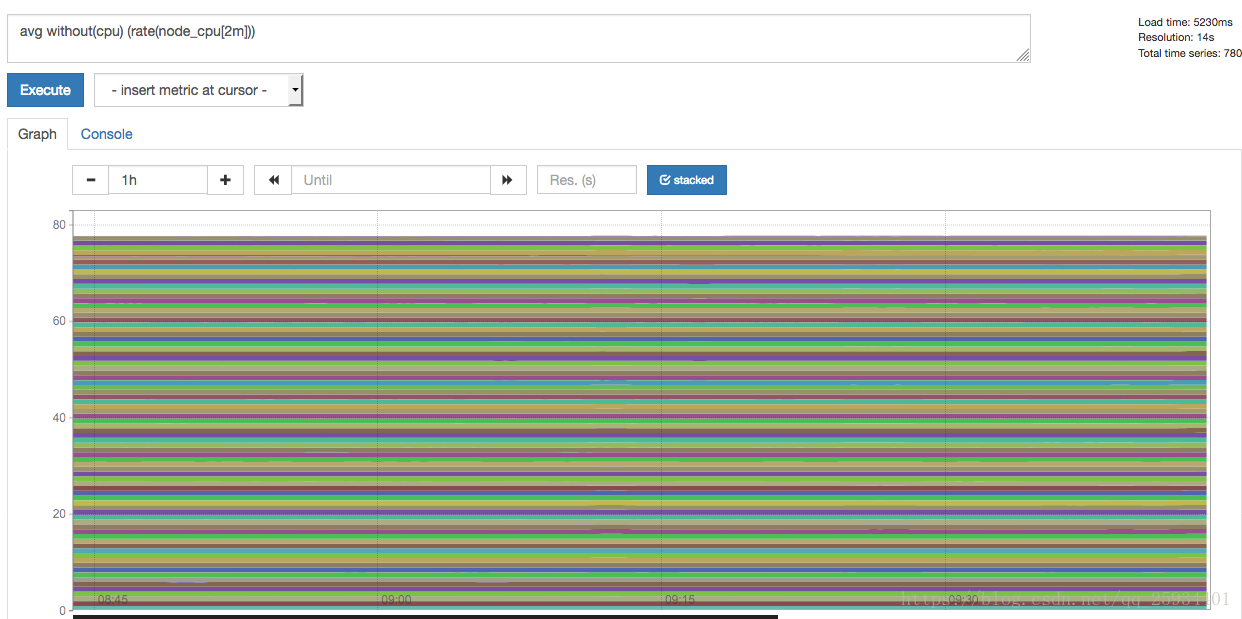
那如果需要计算系统CPU的总体使用率,通过排除系统闲置的CPU使用率即可获得:
1 - avg without(cpu) (rate(node_cpu{mode="idle"}[2m]))
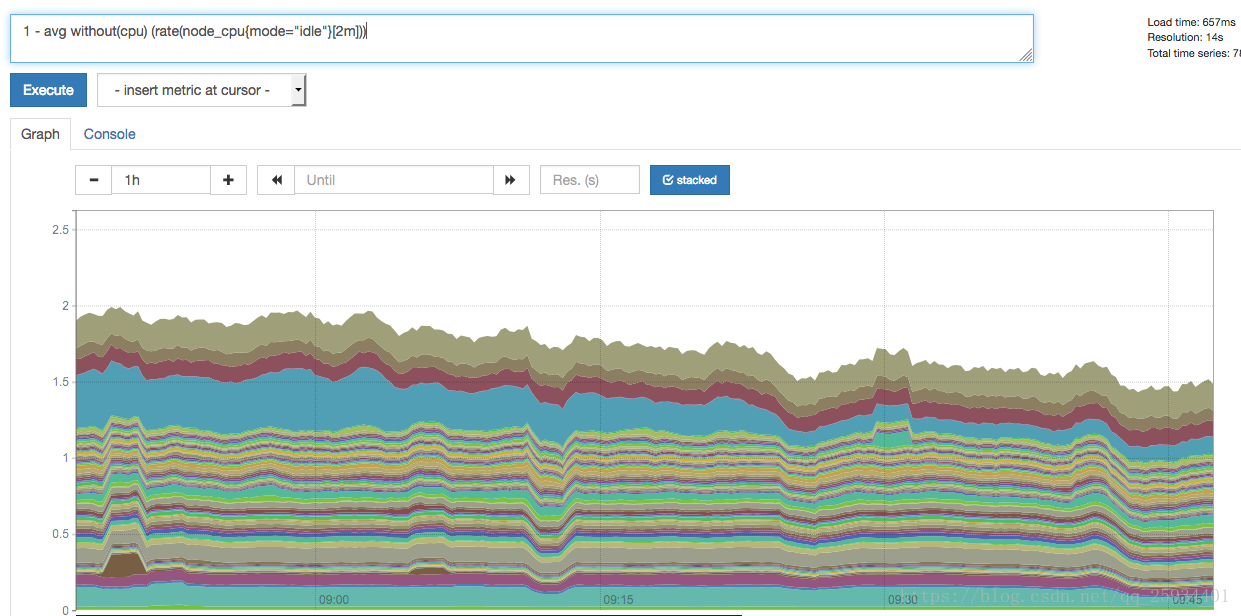
从上面这些例子中可以看出,根据样本中的标签可以很方便地对数据进行查询,过滤以及聚合等操作。同时PromQL中还提供了大量的诸如rate()这样的函数可以实现对数据的更多个性化的处理。
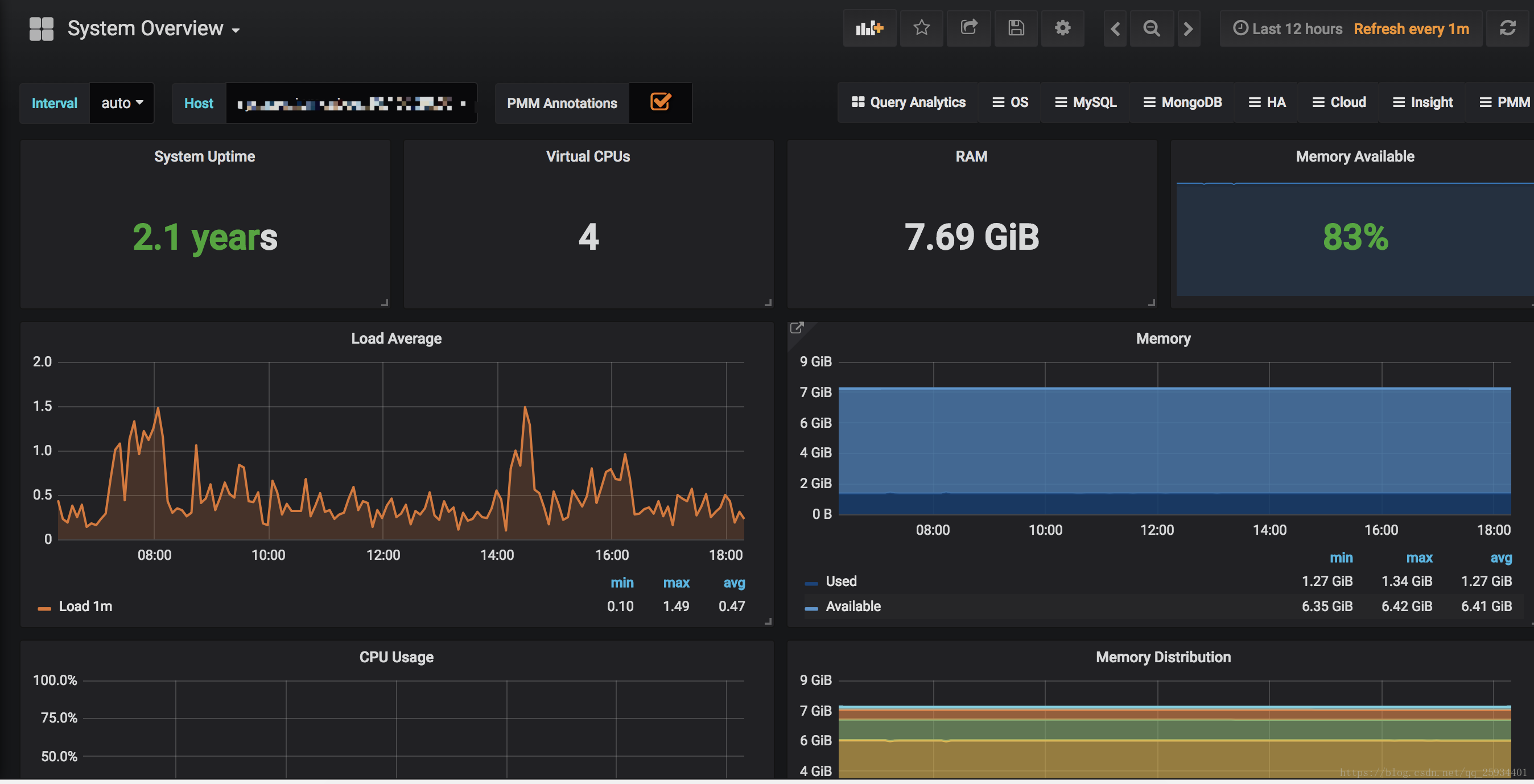
使用Grafana创建可视化Dashboard
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
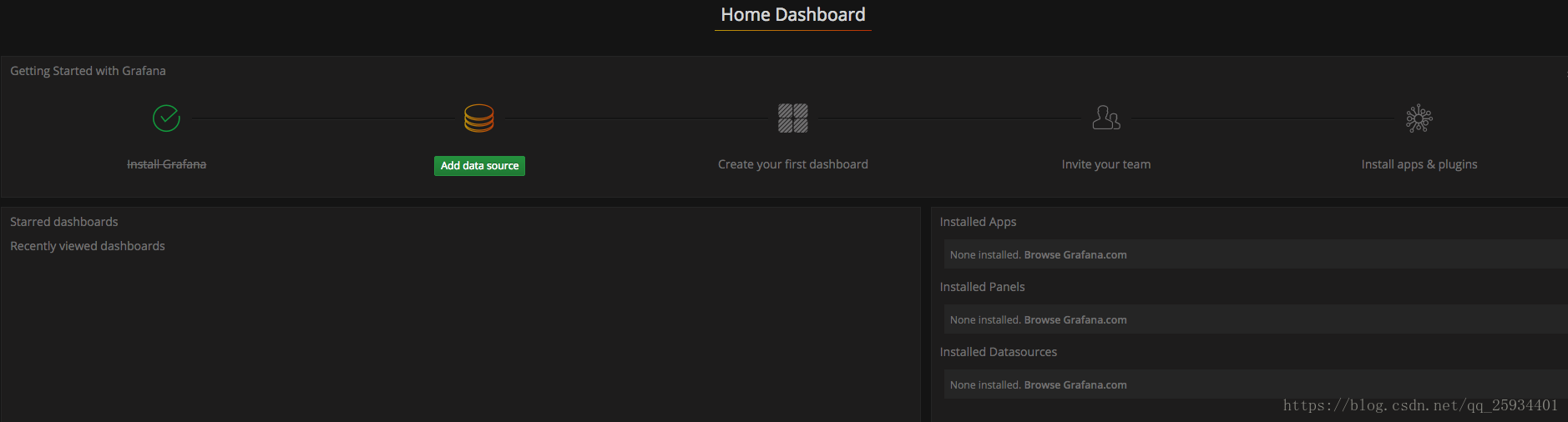
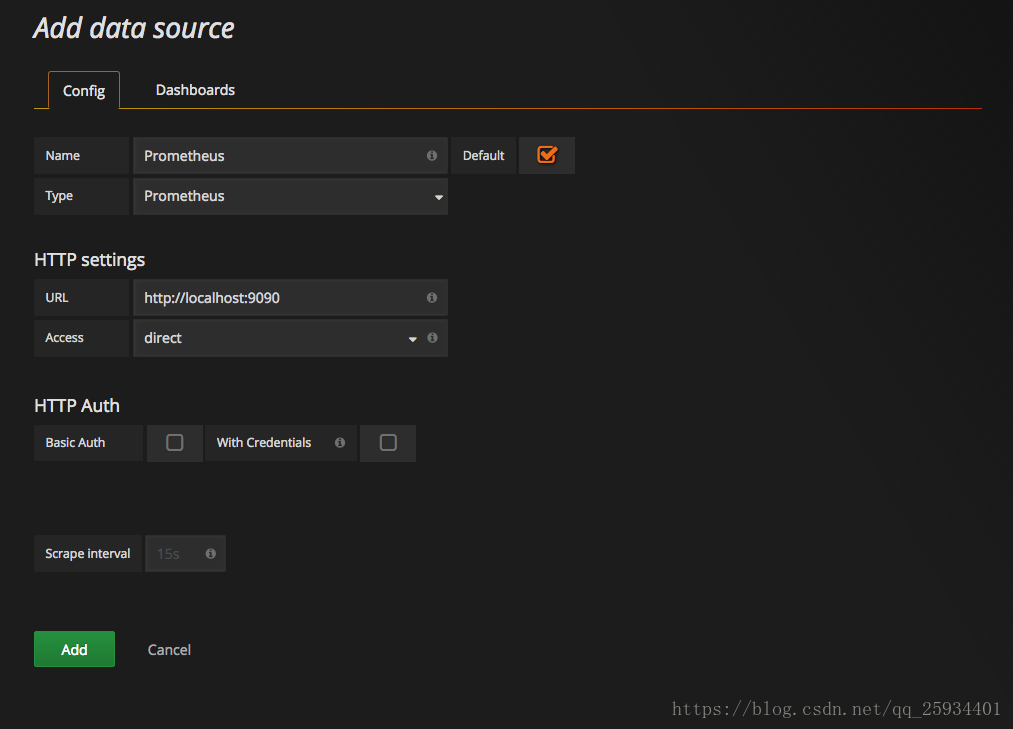
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
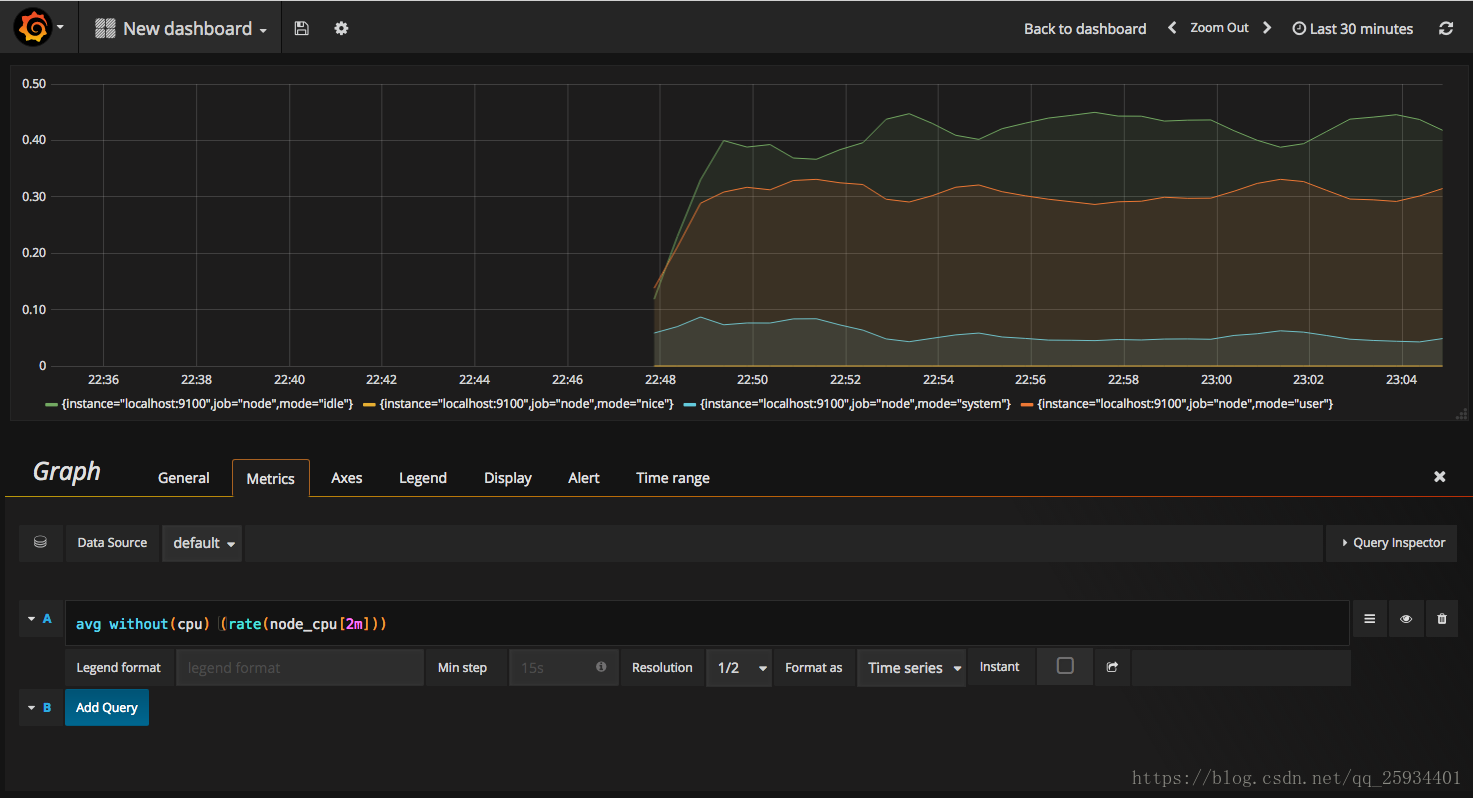
在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个类型为“Graph”的面板。 并在该面板的“Metrics”选项下通过PromQL查询需要可视化的数据:
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:

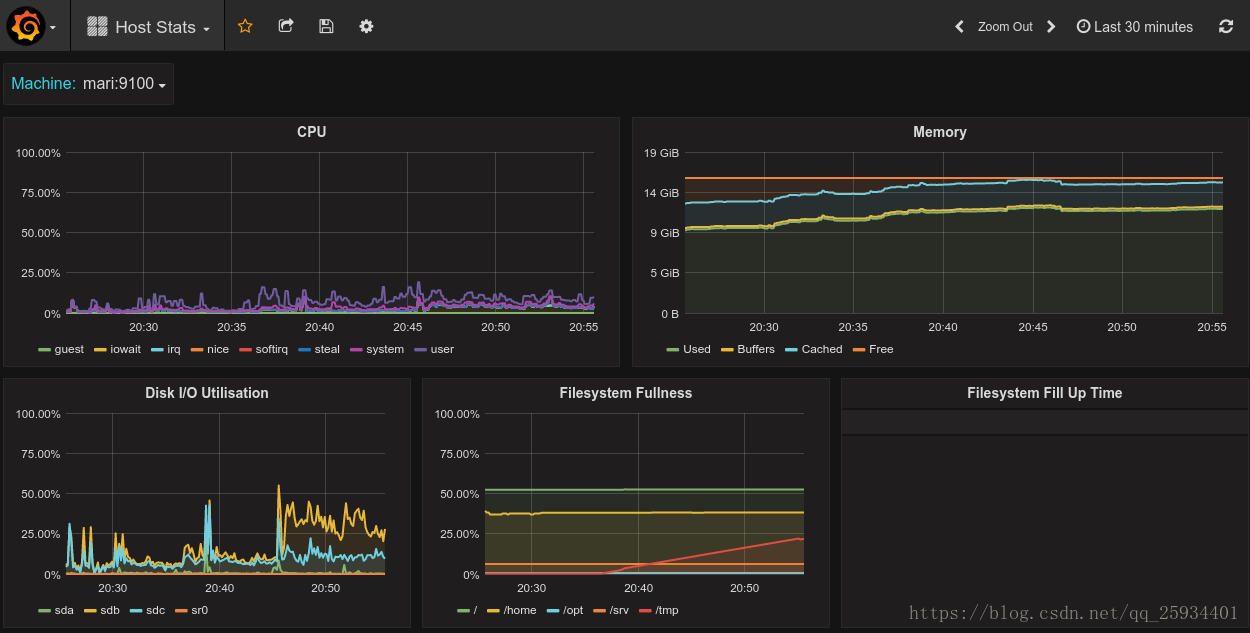
我使用的是System_Overview、Disk_Space、Disk_Performance、CPU_Utilization_Details_Cores
链接:https://pan.baidu.com/s/11K3qKp3nxV2pjyY6J2GBOA 密码:tui9















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









