







目录
1.简介
主观赋权法(AHP)在根据决策者意图确定权重方面比客观赋权法(熵权法)具有更大的优势,但客观性相对较差,主观性相对较强;
而采用客观赋权法有着客观优势,但不能反映出参与决策者对不同指标重视程度,并且会有一定的权重和与实际指标相反的程度。
针对主客观赋权方法的优缺点,我们还力求将主观随机性控制在一定范围内,实现主客观赋权中的中正。客观方面。指标赋权公正,实现了主客观内在统一,评价结果真实、科学、可信。
因此,在对指标进行权重分配时,应考虑指标数据之间的内在统计规律和权威值。给出了合理的决策指标赋权方法,即采用主观赋权法(AHP)和客观赋权法(熵权法)相结合的组合赋权方法,以弥补单一赋权带来的不足。将两种赋权方法相结合的加权方法称为组合赋权法。
注意:本文所介绍的组合权重法请大家结合实际情况慎重使用,因为这个方法不太好
2.算法原理
2.1 指标正向化
这个步骤视情况自己决定把。。。。
不同的指标代表含义不一样,有的指标越大越好,称为越大越优型指标。有的指标越小越好,称为越小越优型指标,而有些指标在某个点是最好的,称为某点最优型指标。为方便评价,应把所有指标转化成越大越优型指标。
设有m个待评对象,n个评价指标,可以构成数据矩阵
![]()
设数据矩阵内元素,经过指标正向化处理过后的元素为 (Xij)'
-
越小越优型指标:C,D属于此类指标
![]()
其他处理方法也可,只要指标性质不变即可
-
某点最优型指标:E属于此类指标
设最优点为a, 当a=90时E最优。

其他处理方法也可,只要指标性质不变即可
-
越大越优型指标:其余所有指标属于此类指标
![]()
此类指标可以不用处理,想要处理也可,只要指标性质不变
2.2 数据标准化
因为每个指标的数量级不一样,需要把它们化到同一个范围内再比较。标准化的方法比较多,这里仅用最大最小值标准化方法。
设标准化后的数据矩阵元素为rij,由上可得指标正向化后数据矩阵元素为 (Xij)'

2.3 计算主观权重
- 得到最大特征值对应特征向量
![]()
- 得到权重向量
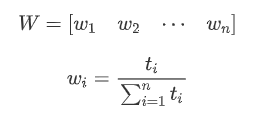
2.4 计算客观权重
- 计算信息熵

- 得到权重

2.5 计算组合权重
主客观组合权重是:指标的综合权数 Wj :
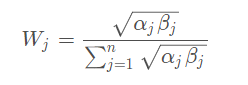
αj——层次分析法计算所得的权重
βj ——熵值法计算所得权重
2.6 计算的得分
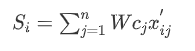
3.实例分析
3.1 读取数据
data = pd.read_excel('D:\桌面\zuhefuquan.xlsx')
# print(data)
label_need=data.keys()[1:]#提取变量名
# print(label_need)
data1=data[label_need].values #只提取数据
print(data1)返回:

3.2 指标正向化
本实例中P1、P3属于此类指标
因此负向指标正向化:
#越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
data2 = data1
index=[1,3]
for i in range(0,len(index)):
data2[:,index[i]]=max(data1[:,index[i]])-data1[:,index[i]]
print(data2)返回:

在对剩余正向指标数据可以不做处理
3.3 数据范围标准化
为什么不做0,1的标准化呢,因为一标准化有不少数据变成了0,对结果起到副作用
#0.002~1区间归一化
[m,n]=data2.shape #查看行数和列数
data3=data2
ymin=0.002
ymax=1
for j in range(0,n):
d_max=max(data2[:,j])
d_min=min(data2[:,j])
data3[:,j]=(ymax-ymin)*(data2[:,j]-d_min)/(d_max-d_min)+ymin
print(data3)返回:

3.4 计算主观权重
#求特征值和特征向量
V,D = np.linalg.eig(data3)
# print('特征值:')
# print(V)
# print('特征向量:')
# print(D)
#最大特征值
tzz = np.max(V)
# print(tzz)
#最大特征向量
k=[i for i in range(len(V)) if V[i] == np.max(V)]
tzx = -D[:,k]
# print(tzx)
# #赋权重
quan=np.zeros((n,1))
for i in range(0,n):
quan[i]=tzx[i]/np.sum(tzx)
a=quan.T
print(a)返回:
![]()
3.5 计算客观权重
#计算信息熵
p=data3
for j in range(0,n):
p[:,j]=data3[:,j]/sum(data3[:,j])
# print(p)
E=data3[0,:]
for j in range(0,n):
E[j]=-1/np.log(m)*sum(p[:,j]*np.log(p[:,j]))
# print(E)
# 计算权重
b=(1-E)/sum(1-E)
print(b)返回:
![]()
3.6 计算组合权重
#计算组合权重
w=b
sum=0
for i in range(n):
sum = sum + np.sqrt(a[i]*b[i])
# print(sum)
for i in range(n):
w[i] = np.sqrt(a[i]*b[i])/sum
print(w)返回:
![]()
3.7 计算得分
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"方案{i}百分制评分为::{Score[i]}")返回:

完整代码
#导入相关库
import pandas as pd
import numpy as np
#读取数据
data = pd.read_excel('D:\桌面\zuhefuquan.xlsx')
# print(data)
label_need=data.keys()[1:]#提取变量名
# print(label_need)
data1=data[label_need].values #只提取数据
print(data1)
#越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
data2 = data1
index=[1,3]
for i in range(0,len(index)):
data2[:,index[i]]=max(data1[:,index[i]])-data1[:,index[i]]
print(data2)
#0.002~1区间归一化
[m,n]=data2.shape #查看行数和列数
data3=data2
ymin=0.002
ymax=1
for j in range(0,n):
d_max=max(data2[:,j])
d_min=min(data2[:,j])
data3[:,j]=(ymax-ymin)*(data2[:,j]-d_min)/(d_max-d_min)+ymin
print(data3)
#求特征值和特征向量
V,D = np.linalg.eig(data3)
# print('特征值:')
# print(V)
# print('特征向量:')
# print(D)
#最大特征值
tzz = np.max(V)
# print(tzz)
#最大特征向量
k=[i for i in range(len(V)) if V[i] == np.max(V)]
tzx = -D[:,k]
# print(tzx)
# #赋权重
quan=np.zeros((n,1))
for i in range(0,n):
quan[i]=tzx[i]/np.sum(tzx)
a=quan.T
print(a)
#计算信息熵
p=data3
for j in range(0,n):
p[:,j]=data3[:,j]/sum(data3[:,j])
# print(p)
E=data3[0,:]
for j in range(0,n):
E[j]=-1/np.log(m)*sum(p[:,j]*np.log(p[:,j]))
# print(E)
# 计算权重
b=(1-E)/sum(1-E)
print(b)
#计算组合权重
w=b
sum=0
for i in range(n):
sum = sum + np.sqrt(a[i]*b[i])
# print(sum)
for i in range(n):
w[i] = np.sqrt(a[i]*b[i])/sum
print(w)
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"方案{i}百分制评分为::{Score[i]}")















 3981
3981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









