







实例5:识别黑白图中的服装图案
Fashion-MNIST是手写数字数据集MNIST的一个替代品,常常被用来测试网络模型,如果在该数据集上效果都不好,其他数据集上的效果可想而知。其单个样本为28X28,6万张训练集,1万张测试集,共10类服装分类。
自动下载Fashion-MNIST
transform将图片转换成了Pytorch支持的形状(【通道,高,宽】)
import torchvision
import torchvision.transforms as tranforms
data_dir = './data/fashion_mnist/'
tranform = tranforms.Compose([tranforms.ToTensor()])
train_dataset = torchvision.datasets.FashionMNIST(data_dir, train=True, transform=tranform,download=True)
print("训练数据集条数",len(train_dataset))
val_dataset = torchvision.datasets.FashionMNIST(root=data_dir, train=False, transform=tranform)
print("测试数据集条数",len(val_dataset))
我们直接打印一下val_dataset[0]和一张用Image读取的PNG图片
a = Image.open("1.png")
print(a)
print(val_dataset[0])
输出为:
<PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1144x329 at 0x185B5B6E5D0>
(<PIL.Image.Image image mode=L size=28x28 at 0x185B5BE8890>, 9)
我们可以直接用np.array()来将PIL Image其转化成np数组,可以观察数据。
a = np.array(Image.open("1.png"))
print(a)
print(np.array(val_dataset[0][0]))
[[[245 247 249 255]
[245 247 249 255]
[245 247 249 255]
...
[245 247 249 255]
[245 247 249 255]
[245 247 249 255]]
[[245 247 249 255]
[245 247 249 255]
[184 184 184 255]
...
[245 247 249 255]
[245 247 249 255]
[245 247 249 255]]
[[245 247 249 255]
[184 184 184 255]
[184 184 184 255]
...
[245 247 249 255]
[245 247 249 255]
[245 247 249 255]]
...
[[245 247 182 255]
[102 15 23 255]
[ 62 143 216 255]
...
[204 232 207 255]
[204 232 207 255]
[204 232 207 255]]
[[245 247 249 255]
[177 105 23 255]
[ 12 105 182 255]
...
[204 232 207 255]
[204 232 207 255]
[204 232 207 255]]
[[245 247 249 255]
[177 105 23 255]
[ 12 105 182 255]
...
[204 232 207 255]
[204 232 207 255]
[204 232 207 255]]]
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 3 1 0 0 7 0 37 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 0 27 84
11 0 0 0 0 0 0 119 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 88 143
110 0 0 0 0 22 93 106 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 53 129 120
147 175 157 166 135 154 168 140 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 2 0 11 137 130 128
160 176 159 167 178 149 151 144 0 0]
[ 0 0 0 0 0 0 1 0 2 1 0 3 0 0 115 114 106 137
168 153 156 165 167 143 157 158 11 0]
[ 0 0 0 0 1 0 0 0 0 0 3 0 0 89 139 90 94 153
149 131 151 169 172 143 159 169 48 0]
[ 0 0 0 0 0 0 2 4 1 0 0 0 98 136 110 109 110 162
135 144 149 159 167 144 158 169 119 0]
[ 0 0 2 2 1 2 0 0 0 0 26 108 117 99 111 117 136 156
134 154 154 156 160 141 147 156 178 0]
[ 3 0 0 0 0 0 0 21 53 92 117 111 103 115 129 134 143 154
165 170 154 151 154 143 138 150 165 43]
[ 0 0 23 54 65 76 85 118 128 123 111 113 118 127 125 139 133 136
160 140 155 161 144 155 172 161 189 62]
[ 0 68 94 90 111 114 111 114 115 127 135 136 143 126 127 151 154 143
148 125 162 162 144 138 153 162 196 58]
[ 70 169 129 104 98 100 94 97 98 102 108 106 119 120 129 149 156 167
190 190 196 198 198 187 197 189 184 36]
[ 16 126 171 188 188 184 171 153 135 120 126 127 146 185 195 209 208 255
209 177 245 252 251 251 247 220 206 49]
[ 0 0 0 12 67 106 164 185 199 210 211 210 208 190 150 82 8 0
0 0 178 208 188 175 162 158 151 11]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
也可以用Tensor
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(tranforms.Compose([tranforms.ToTensor()])(data))
#输出
#tensor([[[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]]], dtype=torch.int32)
尝试用直接用tranforms.Compose([tranforms.ToTensor()])(a)转化成tensor失败,(其实也就可以用(tranforms.ToTensor()(a)) ),tranforms.Compose可以添加更多的转换条件。提示只能用于 PIL Image or ndarray,不支持直接用tuple元组转换,去看源代码,而是取出作为PIL Image进行的转换,而标签类别没有转换则返回默认类型Int。
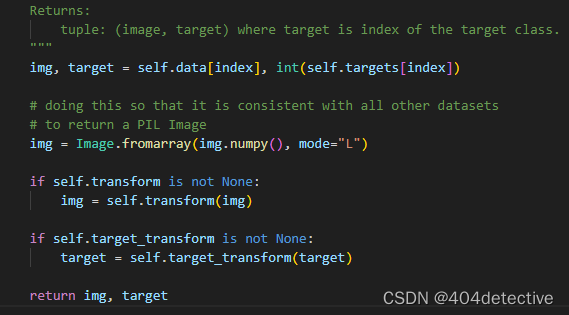
print(type(val_dataset[0][0]))
print(type(val_dataset[0][1]))
返回的类型为:
<class ‘torch.Tensor’>
<class ‘int’>
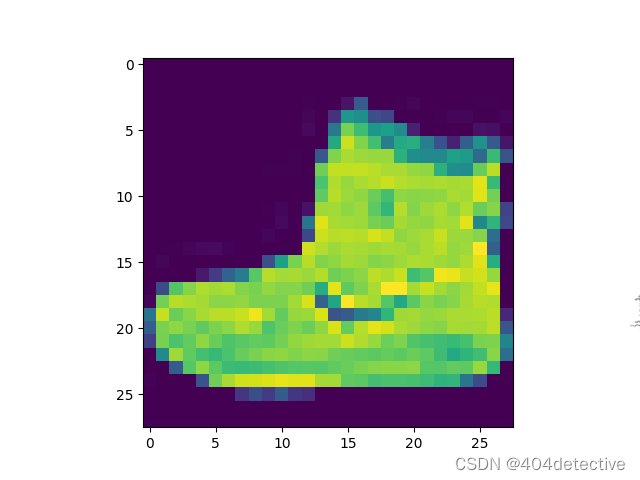
读取显示Fashion-MNIST中的数据
im.reshape(-1,28)等价于im.reshape(28,28)等价于im.reshape(-1,28)
-1为自动匹配
import pylab
im = train_dataset[0][0]
im = im.reshape(-1,28)
print("该图片的标签为:",train_dataset[0][1])
pylab.imshow(im)
pylab.show()
数据集封装类DataLoader
使用torch.utils.data.DataLoader类构建带有批次的数据集,与其配套的还有采样器Sampler类,有多种…
shuffle代表是否要顺序打乱
打印出来的train_dataset和用DataLoader之后的train_loader。
DataLoader就是用来读取dataset类的,自定义的数据集就要自己设计一个dataset类。
Dataset FashionMNIST
Number of datapoints: 60000
Root location: ./data/fashion_mnist/
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
)
<torch.utils.data.dataloader.DataLoader object at 0x00000200A4746350>
用iter(train_loader)使其变为
<class ‘torch.utils.data.dataloader._SingleProcessDataLoaderIter’>
接着使用下列代码,就能打印出来10个数据。
print((iter(train_loader).__next__()))
[tensor([[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
...,
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.7059, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.2824, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.2745, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.1529, 0.0039, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.9333, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.5137, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0275, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0353, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0118, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]]), tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])]
这张图是连在一起的,是由于torchvision.utils.make_grid(images,nrow=batch_size)

nrow表示一行放几张,填5则放两行。

#逆时针旋转90度
img = np.transpose(img, (1, 0, 2))
#目前没搞懂
img = np.transpose(img, (1, 2, 0))
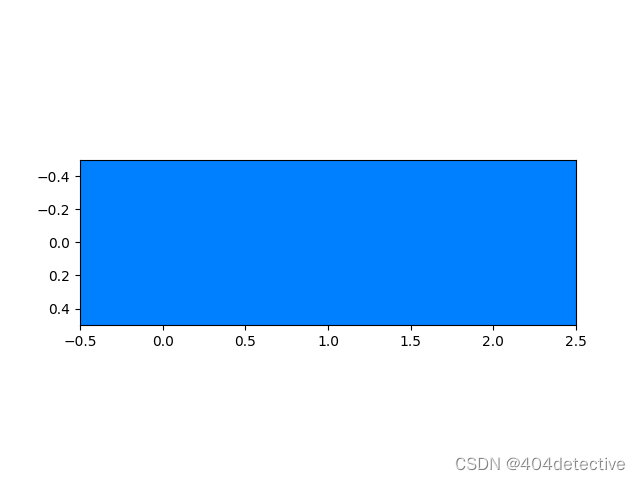
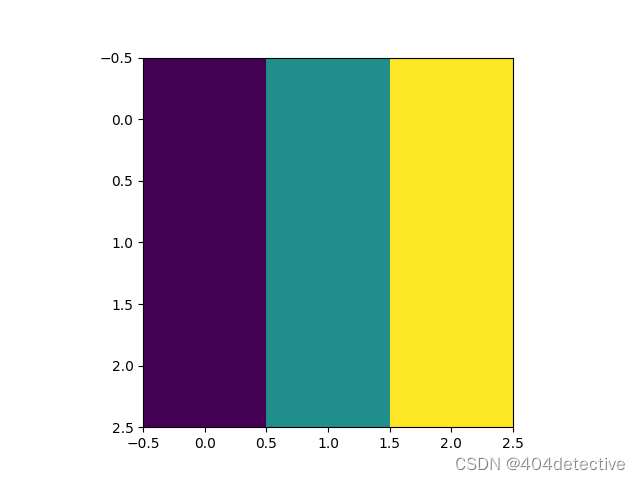
import numpy as np
import pylab as plt
a=[[[0,127,255],[0,127,255],[0,127,255]]]
print(a)
a_trans=np.transpose(a, (1, 2, 0))
print(a_trans)
plt.imshow(a)
plt.imshow(a_trans)
plt.show()
a和a_trans分别为:
############数据集的制作
import torch.utils.data #可以跳转查看代码定义
batch_size = 10
print(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
print(train_loader)
from matplotlib import pyplot as plt
import numpy as np
def imshow(img):
print("图片形状:",np.shape(img))
npimg = img.numpy()
plt.axis('off')
plt.imshow(np.transpose(npimg, (1, 2, 0)))
classes = ('T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle_Boot')
sample = iter(train_loader)
images, labels = sample.__next__()
print('样本形状:',np.shape(images))
print('样本标签:',labels)
imshow(torchvision.utils.make_grid(images,nrow=batch_size)) #是个tensor
print(','.join('%5s' % classes[labels[j]] for j in range(len(images))))
#样本形状: torch.Size([10, 1, 28, 28])
#样本标签: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])
#图片形状: torch.Size([3, 32, 302])
#Sandal,Shirt, Coat,Sandal,Pullover,Sandal,Ankle_Boot, Bag,Shirt,Pullover
############数据集的制作
输出结果一共四行:
第一行,形状4个维度,第1维的10代表有10个数据,第2维度的1代表1个通道,3、4维是图片长宽。
第二行,是样本标签。
第三行,可视化的图片形状,第1维的3代表图片是3通道。在合成过程中图片由1通道变成3通道了。
第四行是分类的具体类别。
构建并训练模型
定义模型类
#########################################################################################################################
#定义myConNet模型类,该模型包括 2个卷积层和3个全连接层
from torch.nn import functional as F
class myConNet(torch.nn.Module):
def __init__(self):
super(myConNet, self).__init__()
#定义卷积层
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = torch.nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
#定义全连接层
self.fc1 = torch.nn.Linear(in_features=12*4*4, out_features=120)
self.fc2 = torch.nn.Linear(in_features=120, out_features=60)
self.out = torch.nn.Linear(in_features=60, out_features=10)
def forward(self, t):#搭建正向结构
#第一层卷积和池化处理
t = self.conv1(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
#第二层卷积和池化处理
t = self.conv2(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
#搭建全连接网络,第一层全连接
t = t.reshape(-1, 12 * 4 * 4)#将卷积结果由4维变为2维
t = self.fc1(t)
t = F.relu(t)
#第二层全连接
t = self.fc2(t)
t = F.relu(t)
#第三层全连接
t = self.out(t)
return t
if __name__ == '__main__':
#
network = myConNet()
print(network)#打印网络
#myConNet(
# (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
# (conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
# (fc1): Linear(in_features=192, out_features=120, bias=True)
# (fc2): Linear(in_features=120, out_features=60, bias=True)
# (out): Linear(in_features=60, out_features=10, bias=True)
#)
定义损失的计算方法及优化器
criterion = torch.nn.CrossEntropyLoss() #实例化损失函数类
optimizer = torch.optim.Adam(network.parameters(), lr=.01)
训练并保存模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
network.to(device)
for epoch in range(2): #数据集迭代2次
running_loss = 0.0
for i, data in enumerate(train_loader, 0): #循环取出批次数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) #
optimizer.zero_grad()#清空之前的梯度
outputs = network(inputs)
loss = criterion(outputs, labels)#计算损失
loss.backward() #反向传播
optimizer.step() #更新参数
running_loss += loss.item()
if i % 1000 == 999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 保存模型
torch.save(network.state_dict(), './CNNFashionMNIST.pth')
# [1, 1000] loss: 0.430
# [1, 2000] loss: 0.313
# [1, 3000] loss: 0.288
# [1, 4000] loss: 0.296
# [1, 5000] loss: 0.267
# [1, 6000] loss: 0.280
# [2, 1000] loss: 0.264
# [2, 2000] loss: 0.260
# [2, 3000] loss: 0.267
# [2, 4000] loss: 0.267
# [2, 5000] loss: 0.257
# [2, 6000] loss: 0.253
加载使用并测试模型
network.load_state_dict(torch.load( './CNNFashionMNIST.pth'))#加载模型
#使用模型
dataiter = iter(test_loader)
images, labels = dataiter.__next__()
inputs, labels = images.to(device), labels.to(device)
imshow(torchvision.utils.make_grid(images,nrow=batch_size))
print('真实标签: ', ' '.join('%5s' % classes[labels[j]] for j in range(len(images))))
outputs = network(inputs)
_, predicted = torch.max(outputs, 1)
print('预测结果: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(len(images))))
#测试模型
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in test_loader:
images, labels = data
inputs, labels = images.to(device), labels.to(device)
outputs = network(inputs)
_, predicted = torch.max(outputs, 1)
predicted = predicted.to(device)
c = (predicted == labels).squeeze()
for i in range(10):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
sumacc = 0
for i in range(10):
Accuracy = 100 * class_correct[i] / class_total[i]
print('Accuracy of %5s : %2d %%' % (classes[i], Accuracy ))
sumacc =sumacc+Accuracy
print('Accuracy of all : %2d %%' % ( sumacc/10. ))

真实标签: Ankle_Boot Pullover Trouser Trouser Shirt Trouser Coat Shirt Sandal Sneaker
预测结果: Ankle_Boot Pullover Trouser Trouser Shirt Trouser Coat Shirt Sandal Sneaker
Accuracy of T-shirt : 88 %
Accuracy of Trouser : 95 %
Accuracy of Pullover : 54 %
Accuracy of Dress : 86 %
Accuracy of Coat : 77 %
Accuracy of Sandal : 96 %
Accuracy of Shirt : 42 %
Accuracy of Sneaker : 95 %
Accuracy of Bag : 92 %
Accuracy of Ankle_Boot : 92 %
Accuracy of all : 82 %
完整代码:
import torchvision
import torchvision.transforms as tranforms
data_dir = './data/fashion_mnist/'
tranform = tranforms.Compose([tranforms.ToTensor()])
train_dataset = torchvision.datasets.FashionMNIST(data_dir, train=True, transform=tranform,download=True)
print("训练数据集条数",len(train_dataset))
val_dataset = torchvision.datasets.FashionMNIST(root=data_dir, train=False, transform=tranform)
print("测试数据集条数",len(val_dataset))
import pylab
im = train_dataset[0][0]
im = im.reshape(-1,28)
pylab.imshow(im)
pylab.show()
print("该图片的标签为:",train_dataset[0][1])
############数据集的制作
import torch
batch_size = 10
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
from matplotlib import pyplot as plt
import numpy as np
def imshow(img):
print("图片形状:",np.shape(img))
npimg = img.numpy()
plt.axis('off')
plt.imshow(np.transpose(npimg, (1, 2, 0)))
classes = ('T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle_Boot')
sample = iter(train_loader)
images, labels = sample.next()
print('样本形状:',np.shape(images))
print('样本标签:',labels)
imshow(torchvision.utils.make_grid(images,nrow=batch_size))
print(','.join('%5s' % classes[labels[j]] for j in range(len(images))))
############数据集的制作
#########################################################################################################################
#定义myConNet模型类,该模型包括 2个卷积层和3个全连接层
from torch.nn import functional as F
class myConNet(torch.nn.Module):
def __init__(self):
super(myConNet, self).__init__()
#定义卷积层
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = torch.nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
#定义全连接层
self.fc1 = torch.nn.Linear(in_features=12*4*4, out_features=120)
self.fc2 = torch.nn.Linear(in_features=120, out_features=60)
self.out = torch.nn.Linear(in_features=60, out_features=10)
def forward(self, t):#搭建正向结构
#第一层卷积和池化处理
t = self.conv1(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
#第二层卷积和池化处理
t = self.conv2(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
#搭建全连接网络,第一层全连接
t = t.reshape(-1, 12 * 4 * 4)#将卷积结果由4维变为2维
t = self.fc1(t)
t = F.relu(t)
#第二层全连接
t = self.fc2(t)
t = F.relu(t)
#第三层全连接
t = self.out(t)
return t
if __name__ == '__main__':
#
network = myConNet()
print(network)#打印网络
#
#print(network.parameters())
##指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
network.to(device)
#print(network.parameters())
criterion = torch.nn.CrossEntropyLoss() #实例化损失函数类
optimizer = torch.optim.Adam(network.parameters(), lr=.01)
for epoch in range(2): #数据集迭代2次
running_loss = 0.0
for i, data in enumerate(train_loader, 0): #循环取出批次数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) #
optimizer.zero_grad()#清空之前的梯度
outputs = network(inputs)
loss = criterion(outputs, labels)#计算损失
loss.backward() #反向传播
optimizer.step() #更新参数
running_loss += loss.item()
if i % 1000 == 999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 保存模型
torch.save(network.state_dict(), './CNNFashionMNIST.pth')
#from sklearn.metrics import accuracy_score
#outputs = network(inputs)
#_, predicted = torch.max(outputs, 1)
#print("训练时的准确率:",accuracy_score(predicted.cpu().numpy(),labels.cpu().numpy()))
network.load_state_dict(torch.load( './CNNFashionMNIST.pth'))#加载模型
#使用模型
dataiter = iter(test_loader)
images, labels = dataiter.next()
inputs, labels = images.to(device), labels.to(device)
imshow(torchvision.utils.make_grid(images,nrow=batch_size))
print('真实标签: ', ' '.join('%5s' % classes[labels[j]] for j in range(len(images))))
outputs = network(inputs)
_, predicted = torch.max(outputs, 1)
print('预测结果: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(len(images))))
#测试模型
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in test_loader:
images, labels = data
inputs, labels = images.to(device), labels.to(device)
outputs = network(inputs)
_, predicted = torch.max(outputs, 1)
predicted = predicted.to(device)
c = (predicted == labels).squeeze()
for i in range(10):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
sumacc = 0
for i in range(10):
Accuracy = 100 * class_correct[i] / class_total[i]
print('Accuracy of %5s : %2d %%' % (classes[i], Accuracy ))
sumacc =sumacc+Accuracy
print('Accuracy of all : %2d %%' % ( sumacc/10. ))
'''
当你需要输出tensor查看的时候,或许需要设置一下默认的输出选项:
torch.set_printoptions(precision=None, threshold=None, edgeitems=None, linewidth=None, profile=None)
其中precision是每一个元素的输出精度,默认是八位;threshold是输出时的阈值,当tensor中元素的个数大于该值时,进行缩略输出,默认时1000;edgeitems是输出的维度,默认是3;linewidth字面意思,每一行输出的长度;profile=None,修正默认设置(不太懂,感兴趣的可以试试))
为了防止一些不正常的元素产生,比如特别小的数,pytorch支持如下设置:
torch.set_flush_denormal(mode)
mode中可以填true或者false
例子如下:
>>> torch.set_flush_denormal(True)
True
>>> torch.tensor([1e-323], dtype=torch.float64)
tensor([ 0.], dtype=torch.float64)
>>> torch.set_flush_denormal(False)
True
>>> torch.tensor([1e-323], dtype=torch.float64)
tensor(9.88131e-324 *
[ 1.0000], dtype=torch.float64)
可以看出设置了之后,当出现极小数时,直接置为0了。文档中提出该功能必须要系统支持。
'''
训练数据集条数 60000
测试数据集条数 10000
libpng warning: iCCP: cHRM chunk does not match sRGB
该图片的标签为: 9
样本形状: torch.Size([10, 1, 28, 28])
样本标签: tensor([0, 9, 4, 7, 6, 6, 3, 9, 7, 5])
图片形状: torch.Size([3, 32, 302])
T-shirt,Ankle_Boot, Coat,Sneaker,Shirt,Shirt,Dress,Ankle_Boot,Sneaker,Sandal
myConNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=192, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=60, bias=True)
(out): Linear(in_features=60, out_features=10, bias=True)
)
cpu
[1, 1000] loss: 0.414
[1, 2000] loss: 0.299
[1, 3000] loss: 0.294
[1, 4000] loss: 0.264
[1, 5000] loss: 0.276
[1, 6000] loss: 0.266
[2, 1000] loss: 0.260
[2, 2000] loss: 0.254
[2, 3000] loss: 0.253
[2, 4000] loss: 0.265
[2, 5000] loss: 0.256
[2, 6000] loss: 0.251
Finished Training
图片形状: torch.Size([3, 32, 302])
真实标签: Ankle_Boot Pullover Trouser Trouser Shirt Trouser Coat Shirt Sandal Sneaker
预测结果: Ankle_Boot Pullover Trouser Trouser Shirt Trouser Coat Shirt Sandal Sneaker
Accuracy of T-shirt : 88 %
Accuracy of Trouser : 95 %
Accuracy of Pullover : 54 %
Accuracy of Dress : 86 %
Accuracy of Coat : 77 %
Accuracy of Sandal : 96 %
Accuracy of Shirt : 42 %
Accuracy of Sneaker : 95 %
Accuracy of Bag : 92 %
Accuracy of Ankle_Boot : 92 %
Accuracy of all : 82 %















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









