






目录
1.5 Vanishing Gradient & Gradient Explosion Problems:
1.6 Training a RNN Language Model
1.9 Solution to the Exploding & Vanishing Gradients
3.1 Task: Sentiment Classification
Bidirectional RNNs: simplified diagram
一、RNN
核⼼想法:重复使⽤ 相同 的权重矩阵W:
传统的翻译模型只能以有限窗⼝⼤⼩的前 n 个单词作为条件进⾏语⾔模型建模,循环神经⽹络与其不同,RNN 有能⼒以语料库中所有前⾯的单词为条件进⾏语⾔模型建模。下图展示的 RNN 的架构,其中矩形框是在⼀个时间步的⼀个隐藏层 t。每个这样的隐藏层都有若⼲个神经元,每个神经元对输⼊向量⽤⼀个线性矩阵运算然后通过⾮线性变化(例如 tanh 函数)得到输出。

在每⼀个时间步,隐藏层都有两个输⼊:前⼀个时间步的隐藏层 和当前时间步的输⼊ ,前⼀个时间步的隐藏层 通过和权重矩阵 相乘和当前时间步的输⼊和权重矩阵 相乘得到当前时间步的隐藏层 ,然后再将 和权重矩阵 相乘,接着对
整个词表通过 softmax 计算得到下⼀个单词的预测结果 ,如下⾯公式所示:
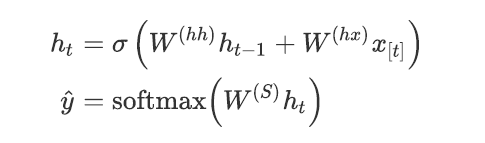
1.1 RNN语言模型

1.2 RNN的优点
1.可以处理 任意⻓度 的输⼊
2.步骤 t 的计算(理论上)可以使⽤ 许多步骤前 的信息
3.模型⼤⼩不会 随着输⼊的增加⽽增加
4.在每个时间步上应⽤相同的权重,因此在处理输⼊时具有 对称性
1.3 RNN的缺点
1.递归计算速度慢
2.在实践中,很难从许多步骤前返回信息
1.4 RNN参数说明

在反向传播时, 我们需要将RNN 沿时间维度展开, 隐层梯度在沿时间维度反向传播时需要反复乘以参数 . 因此, 尽管理论上RNN 可以捕获长距离依赖, 但实际应用中, 根据 谱半径(spectral radius)的不同, RNN 将会面临两个挑战: 梯度爆炸(gradient explosion)和梯度消失(vanishing gradient). 梯度爆炸会影响训练的收敛, 甚至导致网络不收敛; 而梯度消失会使网络学习长距离依赖的难度增加. 这两者相比, 梯度爆炸相对比较好处理, 可以用梯度裁剪(gradient clipping)来解决, 而如何缓解梯度消失是RNN 及几乎其他所有深度学习方法研究的关键所在.运⾏⼀层 RNN 所需的内存量与语料库中的单词数成正⽐。例如,我们把⼀个句⼦是为⼀个 mini-batch,那么⼀个有 k 个单词的句⼦在内存中就会占⽤ k 个词向量的存储空间。同时,RNN 必须维持两对 W和 W和b的矩阵。然⽽ W的可能是⾮常⼤的,它的⼤⼩不会随着语料库的⼤⼩⽽变化(与传统的语⾔模型不⼀样)。对于具有 1000 个循环层的 RNN,矩阵 W的⼤⼩为1000X1000 ⽽与语料库⼤⼩⽆关。
1.5 Vanishing Gradient & Gradient Explosion Problems:
RNN 从⼀个时间步传播权值矩阵到下⼀个时间步。RNN 实现的⽬标是通过⻓距离的时间步来传播上下⽂信息。推到如下:


1.6 Training a RNN Language Model
1.获取⼀个较⼤的⽂本语料库,该语料库是⼀个单词序列
2.输⼊RNN-LM;计算每个步骤 t 的输出分布:
即预测到⽬前为⽌给定的每个单词的概率分布
3.步骤 t 上的损失函数为预测概率分布 与真实下⼀个单词 ( 的独热向量)之间的交叉熵
将其:
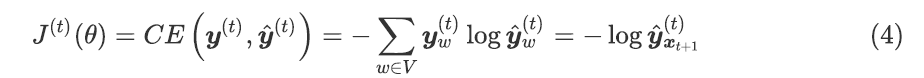
将其平均,得到整个培训集的 总体损失:
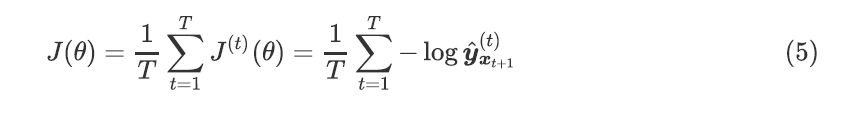


然而代价太过昂贵:

在实践中,我们通常将 x1等参数看做⼀个句⼦或是⽂档
回忆 :随机梯度下降允许我们计算⼩块数据的损失和梯度,并进⾏更新。
计算⼀个句⼦的损失(实际上是⼀批句⼦),计算梯度和更新权重。重复上述操作。
1.7 如何计算?

1.8 RNN Loss and Perplexity:

1.9 Solution to the Exploding & Vanishing Gradients
为了解决梯度爆炸的问题,Thomas Mikolov 等⼈⾸先提出了⼀个简单的启发式解决⽅案,每当梯度⼤于⼀个阈值的时候,将其截断为⼀个很⼩的值,具体如下⾯算法中的伪代码所示。


上图可视化了梯度截断的效果。它展示了⼀个权值矩阵为 和偏置项为 的很⼩的 RNN 神经⽹络的决策界⾯。该模型由⼀个单⼀单元的循环神经⽹络组成,在少量的时间步⻓上运⾏;实⼼箭头阐述了在每个梯度下降步骤的训练过程。在梯度下降模型到达目标函数的高误差壁面时,将梯度推离到决策面较远的位置。断模型⽣成了虚线,在那⾥它将误差梯度拉回到靠近原始梯度的地⽅。为了解决梯度消失问题,我们提出两个技术。
第⼀个技术是不去随机初始化 ,⽽是初始化为单位矩阵。第⼆个技术是使⽤ Rectified Linear(ReLU)单元代替 sigmoid 函数。ReLU 的导数是 0 或者 1。这样梯度传回神经元的导数是 1,⽽不会在反向传播了⼀定的时间步后梯度变⼩。
二、用困惑度来评估语言模型:

2.1 为何关注语言模型
语⾔模型是⼀项 基准测试 任务,它帮助我们 衡量 我们在理解语⾔⽅⾯的进展。⽣成下⼀个单词,需要语法,句法,逻辑,推理,现实世界的知识等语⾔建模是许多NLP任务的 ⼦组件,尤其是那些涉及 ⽣成⽂本 或 估计⽂本概率 的任务。
总结:
语⾔模型: 预测下⼀个单词 的系统
递归神经⽹络:⼀系列神经⽹络
- 采⽤任意⻓度的顺序输⼊
- 在每⼀步上应⽤相同的权重
- 可以选择在每⼀步上⽣成输出
递归神经⽹络语⾔模型
我们已经证明,RNNs是构建LM的⼀个很好的⽅法。
如何计算句⼦编码:
- 使⽤最终隐层状态
- 使⽤所有隐层状态的逐元素最值或均值
Encoder的结构在NLP中⾮常常⻅e.g. speech recognition, machine translation, summarization这是⼀个条件语⾔模型的示例。我们使⽤语⾔模型组件,并且最关键的是,我们根据条件来调整它。
三、Deep Bidirectional RNNs
⼀个双向深度神经⽹络;在每个时间步 t,这个⽹络维持两个隐藏层,⼀个是从左到右传播⽽另外⼀个是从右到左传播。为了在任何时候维持两个隐藏层,该⽹络要消耗的两倍存储空间来存储权值和偏置参数。最后的分类结果 ,是结合由两个 RNN 隐藏层⽣成的结果得分产⽣。下式展示了给出了建⽴双向RNN隐层的数学公式。两个公式之间唯⼀的区别是递归读取语料库的⽅向
不同。最后⼀⾏展示了通过总结过去和将来的单词表示,显示⽤于预测下⼀个单词的分类关系。

with three RNN layers

为了构建⼀个 L 层的深度 RNN,上述的关系要修改为在公式中的关系,其中在第 层的每个中间神经元的输⼊是在相同时间步 t 的 RNN 第 层的输出。最后的输出 ,每个时间步都是输⼊参数通过所有隐层传播的结果。
3.1 Task: Sentiment Classification

- 我们可以把这种隐藏状态看作是这个句⼦中单词“terribly”的⼀种表示。我们称之为上下⽂表示。
- 这些上下⽂表示只包含关于左上下⽂的信息(例如“the movie was”)。
- 在这个例⼦中,“exciting”在右上下⽂中,它修饰了“terribly”的意思(从否定变为肯定)


- 这是⼀个表示“计算RNN的⼀个向前步骤”的通⽤符号——它可以是普通的、LSTM或GRU计算。
- 我们认为这是⼀个双向RNN的“隐藏状态”。这就是我们传递给⽹络下⼀部分的东⻄。
- ⼀般来说,这两个RNNs有各⾃的权重
Bidirectional RNNs: simplified diagram
- 双向箭头表示双向性,所描述的隐藏状态是正向+反向状态的连接
- 注意:双向RNNs只适⽤于访问整个输⼊序列的情况
- 它们不适⽤于语⾔建模,因为在LM中,您只剩下可⽤的上下⽂
- 如果你有完整的输⼊序列(例如任何⼀种编码),双向性是强⼤的(默认情况下你应该使⽤它)
Multi-layer RNNs
- RNNs在⼀个维度上已经是“深的”(它们展开到许多时间步⻓)
- 我们还可以通过应⽤多个RNNs使它们“深⼊”到另⼀个维度——这是⼀个多层RNN
- 较低的RNNs应该计算较低级别的特性,⽽较⾼的RNNs应该计算较⾼级别的特性
- 多层RNNs也称为堆叠RNNs。

RNN i 层 的隐藏状态是RNN i +1 层 的输⼊
三、Gated Recurrent Units
我们已经讨论了从隐藏状态ht-1 向ht 转换的⽅法,使⽤了⼀个仿射转换和point — wise的⾮线性转换。在这⾥,我们讨论⻔激活函数的使⽤并修改 RNN 结构。虽然理论上RNN 能捕获⻓距离信息,但实际上很难训练⽹络做到这⼀点。⻔控制单元可以让 RNN 具有更多的持久性内存,从⽽更容易捕获⻓距离信息。让我们从数学⻆度上讨论 GRU 如何使⽤ ht-1和xt 来⽣成下⼀个隐藏状态ht 。
GRU 的四个基本操作阶段,下⾯对这些公式作出更直观的解释,下图展示了GRU 的基本结构和计算流程:


- 更新⻔:控制隐藏状态的哪些部分被更新,哪些部分被保留
- 重置⻔:控制之前隐藏状态的哪些部分被⽤于计算新内容
- 新的隐藏状态内容:重置⻔选择之前隐藏状态的有⽤部分。使⽤这⼀部分和当前输⼊来计算新的隐藏状态内容
- 隐藏状态:更新⻔同时控制从以前的隐藏状态保留的内容,以及更新到新的隐藏状态内容的内容

四、Long-Short-Term-Memories
Long-Short-Term-Memories 是和 GRU 有⼀点不同的另外⼀种类型的复杂激活神经元。它的作⽤与GRU 类似,但是神经元的结构有⼀点区别。 LSTM 神经元的设计架构:

4.1 LSTM 的架构以及这个架构背后的意义:

4.2 LSTM图示:

信息被 擦除 / 写⼊ / 读取 的选择由三个对应的⻔控制
- ⻔也是⻓度为 n 的向量
- 在每个时间步⻓上,⻔的每个元素可以打开(1)、关闭(0)或介于两者之间
- ⻔是动态的:它们的值是基于当前上下⽂计算的
4.3 LSTM结构浅析

- 遗忘⻔:控制上⼀个单元状态的保存与遗忘
- 输⼊⻔:控制写⼊单元格的新单元内容的哪些部分
- 输出⻔:控制单元的哪些内容输出到隐藏状态
- 新单元内容:这是要写⼊单元的新内容
- 单元状态:删除(“忘记”)上次单元状态中的⼀些内容,并写⼊(“输⼊”)⼀些新的单元内容
- 隐藏状态:从单元中读取(“output”)⼀些内容
- Sigmoid函数:所有的⻔的值都在0到1之间
- 通过逐元素的乘积来应⽤⻔
- 这些是⻓度相同的向量
你可以把LSTM⽅程想象成这样:

五、RNN vs LSTM
RNN的LSTM架构更容易保存许多时间步上的信息
- 如果忘记⻔设置为记得每⼀时间步上的所有信息,那么单元中的信息被⽆限地保存
- 相⽐之下,普通RNN更难学习重复使⽤并且在隐藏状态中保存信息的矩阵
LSTM并不保证没有消失/爆炸梯度,但它确实为模型提供了⼀种更容易的⽅法来学习远程依赖关系
六、LSTM vs GRU
- 研究⼈员提出了许多⻔控RNN变体,其中LSTM和GRU的应⽤最为⼴泛
- 最⼤的区别是GRU计算速度更快,参数更少
- 没有确凿的证据表明其中⼀个总是⽐另⼀个表现得更好
- LSTM是⼀个很好的默认选择(特别是当您的数据具有⾮常⻓的依赖关系,或者您有很多训练数据时)
- 经验法则:从LSTM开始,但是如果你想要更有效率,就切换到GRU
参考:
斯坦福CS224N深度学习⾃然语⾔处理2019冬学习笔记⽬录 (课件核⼼内容的提炼,并包含作者的⻅解
与建议)
斯坦福⼤学 CS224n⾃然语⾔处理与深度学习笔记汇总 {>>这是针对note部分的翻译<<}















 2194
2194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









