









attention 机制
什么是attention
attention机制是(非常)松散地基于人类的视觉注意机制。就是按照“高分辨率”聚焦在图片的某个特定区域并以“低分辨率”感知图像的周边区域的模式,然后不断地调整聚焦点。这个概念最早出现在认知心理学上面。用一个最通俗的例子来解释就是,当你认真的去做一件事情,你的注意力会被更多的分配在手上的事情,而忽略身边的其他事情;当你喜欢一个人,你会自然而然的关注他,忽略其他身边的异性。这就是attention机制对人生活的影响,可以说这种影响无处不在。所以人们就在想,将这个机制应用在图片上可行,是否可以应用在文本处理。答案是可行的,其实当我们快读阅读或者读长篇文本的时候,我们的注意力是集中在关键词,事件或实体上。通过大量实验证明,将attention机制应用在机器翻译,摘要生成,阅读理解等问题上,取得的成效显著。
Attention与神经网络
Encoder-Decoder框架
Encoder-Decoder框架可以直观地理解为:一个适合处理由一个context生成一个target的通用处理模型。
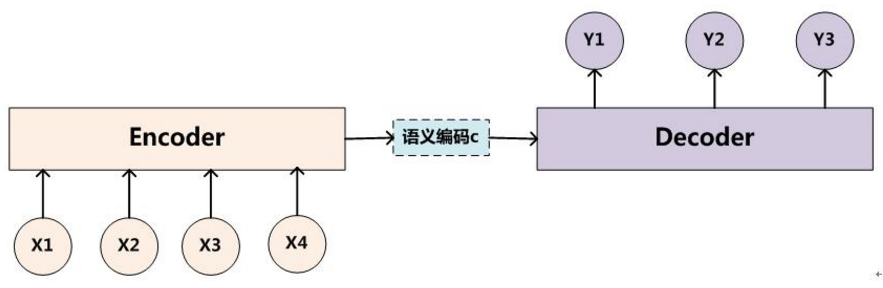
例如机器翻译中,对于句子对
<X,Y>
<script type="math/tex" id="MathJax-Element-1">
</script>,我们的目标是给定输入句子X,通过Encoder-Decoder框架来生成目标句子Y。X和Y可以是同一种语言,也可以是两种不同的语言。而X和Y分别由各自的单词序列构成:
Encoder对输入句子X进行编码,将输入句子通过非线性变换转化为中间语义表示C:
解码器Decoder,其任务是根据句子X的中间语义表示C和之前已经生成的历史信息y1,y2….yi-1来生成i时刻要生成的单词yi。
对于输入而言,Encoder-Decoder模型是没有注意力的,是注意力不集中的分心模型。在目标句子中的每个单词的生成过程:
不论生成哪个单词,是y1,y2,还是y3也好,他们使用的句子X的语义编码C都是一样的,没有任何区别。
举个例子,输入的英文句子是:Cats eat mice,Encoder-Decoder框架逐步生成中文单词:“猫” ,“吃” ,“老鼠”。在翻译词语“猫”的时候,分心模型里面的每个英文单词对于翻译目标单词“猫”贡献是相同的,很明显这里不太合理,显然“Cats”对于翻译成“猫”更重要,但是分心模型是无法体现这一点的。这样的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,缺点就比较明显了。如图所示:
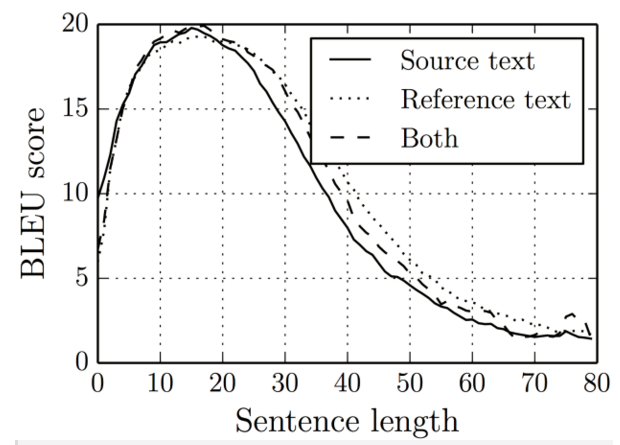
当文本的长度超过15,Encoder-Decoder框架的结果就逐步下滑了。这是因为,无论输入包含多少信息量,最终所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失。encoder中丢失很多细节信息,decoder的结果也就会显著变差。
Attention model
Attention严格上讲,是一种机制,而不是具体的model的实现(这一点很像贪心,并不是一种算法,而是一种idea,但人们习惯上称为贪心算法)。我们将Attention引入Encoder-Decoder框架,通过前面的输入X和中间语义表示C来共同决定decoder的结果。增加了Attention model的Encoder-Decoder框架如下图所示:
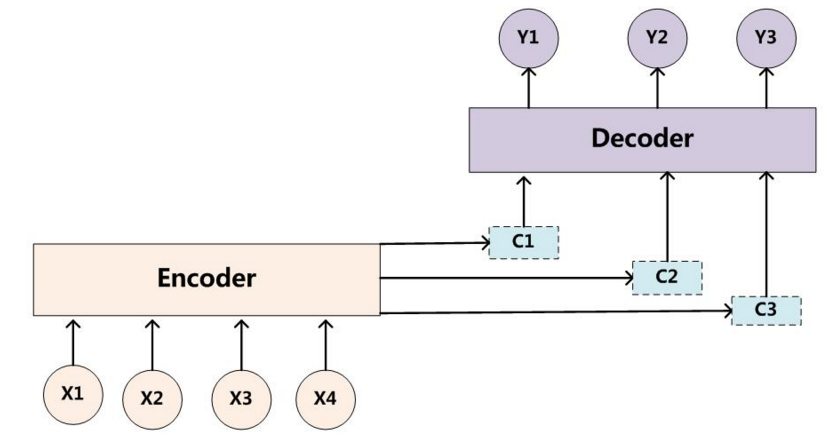
目标句子中的每个单词都学会其对应的源语句子中单词的注意力分配概率信息。在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。即生成目标句子单词的过程成了下面的形式:
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布。比如对于上面的英汉翻译来说,其对应的信息可能如下:
这里,计算注意力分配概率分布信息要根据不同的网络模型来选择不同的计算框架。
这是参考大牛博客写的读后感
自然语言处理中的Attention Model:是什么及为什么
Attention 应用
深度学习和自然语言处理中的attention和memory机制
Neural Attention Model for Abstractive Sentence Summarization















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









