







前言:最近在阅读一篇文章,用到了Attention Unet所以特地写了两篇文章,上一篇文章介绍了Attention的基础知识,这篇文化在哪个介绍Attention Unet相关知识以及代码。
Attention U-Net
基础
注意力机制
Attention介绍:就是模仿人的注意力机制设计,人看到一个东西,会把注意力放在需要关注的地方,把其它无关的信息过滤掉。下面的图是人类看到图片注意力热力图。

软注意力和硬注意力
软注意力(Soft Attention):加权图像的每个像素。 高相关性区域乘以较大的权重,而低相关性区域标记为较小的权重。
硬注意力(Hard Attention):一次选择一个图像的一个区域作为注意力,设成1,其他设为0。
通常采用的都是软注意力,因为软注意力能参与反向传播,而硬注意力机制不行,得借助强化学习的手段训练。而且软注意力机制模块大多数都不会改变输出尺寸,从而可以很灵活的插入到卷积网络的各个部分。
U-Net为什么需要Attention
既然Attention U-Net是U-Net的改进,那么需要先简单回顾一下U-Net,来更好对比。
下面是U-Net的网络结构图:
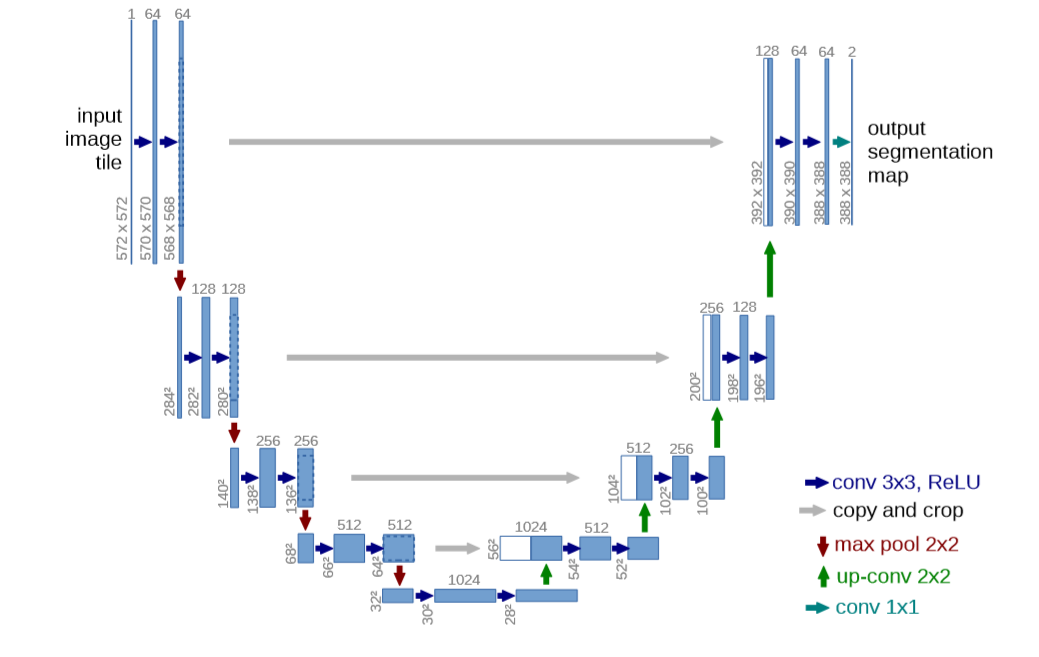
从U-Net的结构图中看出,为了避免在Decoder解码器时丢失大量的细节,使用了Skip Connection跳跃链接,将Encoder编码器中提取的信息直接连接到Decoder对应的层上。
但是,Encoder提取的low-level feature有很多的冗余信息,也就是提取的特征不太好,可能对后面并没有帮助,这就是U-Net网络存在的问题。
该问题可以通过在U-Net上加入注意力机制,来减少冗余的Skip Connection。
Attention U-Net
Attention U-Net发布比Res U-Net要早些,主要应用在医学图像分割领域。
Attention U-Net:在U-Net基础上,通过在U-Net上加入软注意力机制,来减少冗余的Skip Connection。
加入软注意机制随让能够减少冗余,但会增加训练参数,从而导致计算成本有所提高。所以集成到标准U-Net网络中时要简单方便、计算开销小。
Attention U-Net结构图:
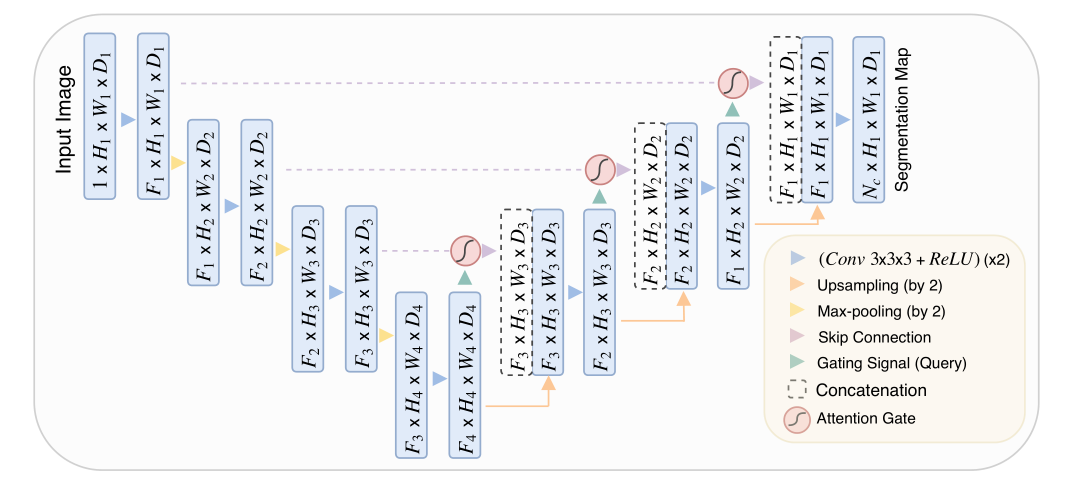
对基础U-Net网络结构,可以发现在跳跃链接中都加入了Attention Gate模块。而原始U-Net只是单纯的把同层的下采样层的特征直接连接到上采样层中。
Attention Gate模块结构图:
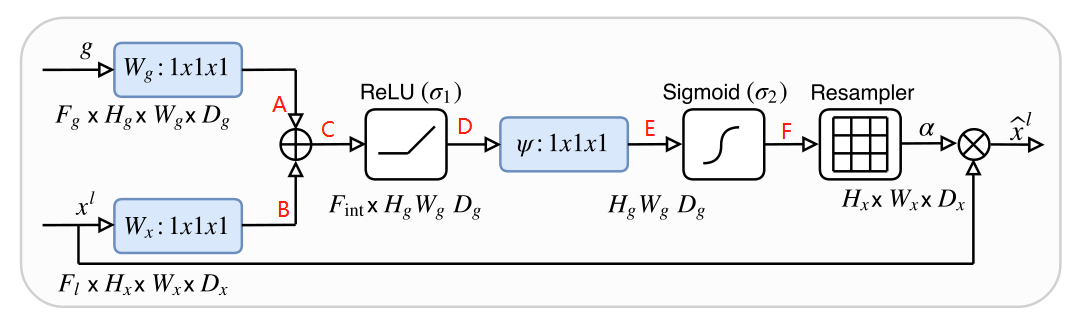
x
l
x^l
xl是当前层Encoder下采样跳跃链接来的数据;g是来自Decoder下一层的数据,所以g的尺寸大小是
x
l
x^l
xl的二分之一。所以要对
x
l
x^l
xl下采样或者g上采样,来确保尺寸一致,从而得到
W
g
W_g
Wg和
W
x
W_x
Wx。尺寸一致后,
W
g
W_g
Wg和
W
x
W_x
Wx进行逐点“+”操作,然后经过relu,再1×1卷积和sigmoid函数从而得到注意力系数,最后再结果一个resample把尺寸还原回来。还原后的注意力系数就可以和特征图
x
l
x^l
xl进行加权。
为什么需要relu和sigmoid激活函数,因为 W g W_g Wg和 W x W_x Wx进行“+”操作后还是线性操作,激活函数可以引入非线性,从而更好拟合。
简单点来说,g是decoder的数据,对比同层的 x l x^l xl要学到的东西更多,信息更加准确。g就是Attention机制中的Q(Query),告诉了模型需要要从 x l x^l xl中学习的重点。
Attention Gate模块代码
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
# 下采样的gating signal 卷积
g1 = self.W_g(g)
# 上采样的 l 卷积
x1 = self.W_x(x)
# concat + relu
psi = self.relu(g1 + x1)
# channel 减为1,并Sigmoid,得到权重矩阵
psi = self.psi(psi)
# 返回加权的 x
return x * psi


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









