







前言
pytorch实现线性回归
过程如下
假设我们的基础模型就是 y=wx+b 其中w和b均为参数,我们使用y=3*x+0.8来构造数据x,y 所以最后通过模型应该能够得到w和b应该在3与0.8附近。思路如下:
1准备数据 2计算预测值 3计算损失,把参数的梯度设置为0,进行反向传播 4更新参数 5效果可视化
## 1准备数据
#1.准备数据y=3x+0.8,准备参数
import torch
x=torch.rand([50])#x是随机的50个数据 x在0-1之间
y=3*x+0.8#y是x的函数 也是50个数据
#可视化一下
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(x,y)
plt.xlabel('x')
plt.ylabel('y')
#准备一下要去拟合的线性回归的w和b
w=torch.rand(1,requires_grad=True)#随机初始的一个w 范围在0-1之间
b=torch.rand(1,requires_grad=True)#随机初始的一个b 范围在0-1之间
print(w)
print(b)
tensor([0.0100], requires_grad=True)
tensor([0.4700], requires_grad=True)
## 准备一下函数:计算损失,把参数的梯度设置为0,进行反向传播
def loss_fn(y,y_predict):
loss=(y_predict-y).pow(2).mean()#均方误差
#每次反向传播前把梯度置为0
for i in [w,b]:
#w和b中
if i.grad is not None:#如果梯度不为空 就设置为0
i.grad.data.zero_()
loss.backward()#反向传播
return loss.data#返回loss的具体数值
## 准备函数:更新参数
def optimize(learning_rate):
w.data-=learning_rate*w.grad.data#这里运用的是梯度下降法
b.data-=learning_rate*b.grad.data
for i in range(3000):
## 2计算预测值
y_predict=x*w+b
## 3计算损失 并把参数的梯度置为0 进行反向传播
loss=loss_fn(y,y_predict)
if i%300==0:
print('迭代次数:',i,'\t误差:',loss)
## 4更新参数w和b
optimize(0.01)
迭代次数: 0 误差: tensor(3.5854)
迭代次数: 300 误差: tensor(0.1780)
迭代次数: 600 误差: tensor(0.0958)
迭代次数: 900 误差: tensor(0.0516)
迭代次数: 1200 误差: tensor(0.0278)
迭代次数: 1500 误差: tensor(0.0149)
迭代次数: 1800 误差: tensor(0.0080)
迭代次数: 2100 误差: tensor(0.0043)
迭代次数: 2400 误差: tensor(0.0023)
迭代次数: 2700 误差: tensor(0.0013)
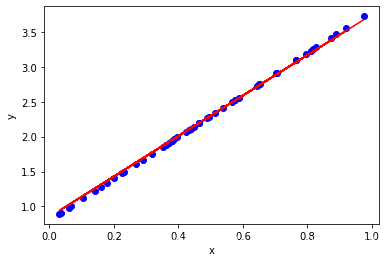
## 5效果可视化
y_predict=w*x+b #训练好的w和b 然后算出y的预测值
plt.figure()
plt.scatter(x,y,c='b')#原来的数据用散点图 颜色是蓝色
plt.plot(x,y_predict.detach().numpy(),c='r')#拟合的数据用直线图 颜色是红色
plt.xlabel('x')
plt.ylabel('y')
print('w:',w)
print('b',b)
w: tensor([2.8976], requires_grad=True)
b tensor([0.8508], requires_grad=True)
完成。
总结
(如果您发现我写的有错误,欢迎在评论区批评指正)。















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









