







自编码器可以理解为一个试图去还原其原始输入的系统,如下图所示,虚线蓝色框内就是一个自编码器模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上都是对输入信号做某种变换。基本意思就是一个隐藏层的神经网络,输入输出都是x,并且输入维度一定要比输出维度大,属于无监督学习。一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。
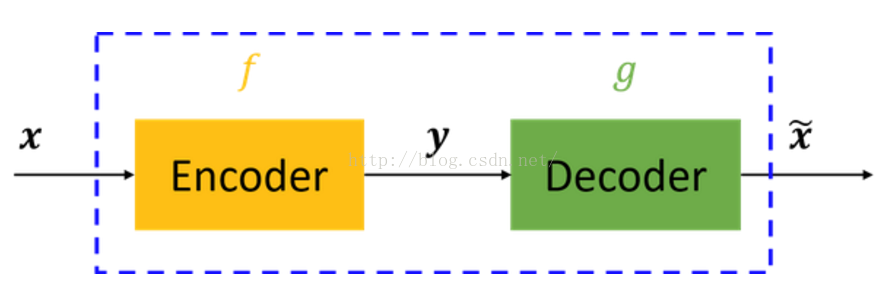
对于自编码器,我们往往并不关系输出是啥(反正只是复现输入),我们真正关心的是中间层的编码,或者说是从输入到编码的映射。可以这么想,在我们强迫编码y和输入x不同的情况下,系统还能够去复原原始信号x,那么说明编码y已经承载了原始数据的所有信息,但以一种不同的形式!这就是特征提取啊,而且是自动学出来的!实际上,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。
Auto-Encoder: What Is It? And What Is It Used For? (Part 1):https://towardsdatascience.com/auto-encoder-what-is-it-and-what-is-it-used-for-part-1-3e5c6f017726
目录
1.5 Variational AutoEncoder(VAE)
2.3 Reparameterization Trick:对某一分布的数据进行采样
1. AutoEncoder模型演进
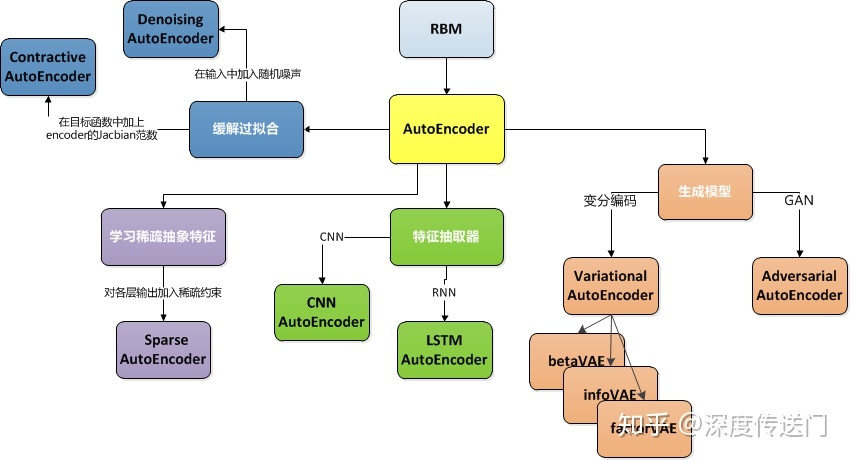
1.1 AutoEncoder

这里我们可以看到,AutoEncoder在优化过程中无需使用样本的label,本质上是把样本的输入同时作为神经网络的输入和输出,通过最小化重构误差希望学习到样本的抽象特征表示z。这种无监督的优化方式大大提升了模型的通用性。
对于基于神经网络的AutoEncoder模型来说,则是encoder部分通过逐层降低神经元个数来对数据进行压缩;decoder部分基于数据的抽象表示逐层提升神经元数量,最终实现对输入样本的重构。
问题:
这里指的注意的是,由于AutoEncoder通过神经网络来学习每个样本的唯一抽象表示,这会带来一个问题:当神经网络的参数复杂到一定程度时AutoEncoder很容易存在过拟合的风险。
1.2 Denoising AutoEncoder
为了缓解经典AutoEncoder容易过拟合的问题:
- 一个办法是:在输入中加入随机噪声;Vincent等人[3]提出了Denoising AutoEncoder,在传统AutoEncoder输入层加入随机噪声来增强模型的鲁棒性。
- 另一个办法是:结合正则化思想,Rifai等人[4]提出了Contractive AutoEncoder,通过在AutoEncoder目标函数中加上encoder的Jacobian矩阵范式来约束使得encoder能够学到具有抗干扰的抽象特征。
下图是Denoising AutoEncoder的模型框架。目前添加噪声的方式大多分为两种:(1)添加服从特定分布的随机噪声;(2)随机将输入x中特定比例置为0。有没有觉得第二种方法跟现在广泛石红的Dropout很相似,但是Dropout方法是Hinton等人在2012年才提出来的,而第二种加噪声的方法在08年就已经被应用了。这其中的关系,就留给你思考一下。

Denoising AutoEncoder模型框架
1.3 Sparse AutoEncoder
为了在学习输入样本表示的时候可以得到稀疏的高维抽象特征表示,Ng等人[5]在原来的损失函数中加入了一个控制稀疏化的正则项。稀疏约束能迫使encoder的各层只有部分神经元被激活,从而将样本映射成低维稀疏特征向量。
具体来说,如果单个神经元被激活的概率很小,则可认为该网络具有稀疏性。神经元是否被激活可以看做服从概率的伯努利分布。
神经网络稀疏性的约束衡量方式:
- 可以使用KL散度来衡量神经元被激活的概率ρ^与期望概率ρ之间的loss,通过将D_KL加入到AutoEncoder的目标函数中,即可实现对神经网络稀疏性的约束。

- 另外,还有一种方法就是对神经网络各层的输出加入L1约束。
1.4 CNN/LSTM AutoEncoder
其实无论是Convolutional Autoencoder[6]、 Recursive Autoencoder还是LSTM Autoencoder[7]等等,思路都是将传统NN网络的结构融入到AutoEncoder中。
以LSTM AutoEncoder为例,目标是针对输入的样本序列学习得到抽象特征z。因此
- encoder部分:是输入一个样本序列输出抽象特征z,采用如下的 Many-to-one LSTM;
- decoder部分:则是根据抽象特征z,重构出序列,采用如下的 One-to-many LSTM。

将传统NN网络的结构引入AutoEncoder其实更多是一个大概的思想,具体实现的时候,编码器和解码器都是不固定的,可选的有:CNN/RNN/双向RNN/LSTM/GRU等等,而且可以根据需要自由组合。
1.5 Variational AutoEncoder(VAE)
参考:
- 论文:"Tutorial on Variational Autoencoders"
- 博客:“Tutorial - What is a variational autoencoder? ”。
- 损失函数含义:Deep Learning AutoEncoder 及其相关模型
Vairational AutoEncoder(VAE)是Kingma等人与2014年提出。VAE比较大的不同点在于:
VAE不再将输入x映射到一个固定的抽象特征z上,而是假设样本x的抽象特征z服从(μ,σ^2)的正态分布,然后再通过分布采样生成抽象特征z(重采样Reparametrization tricks),最后基于z通过decoder得到输出。
由于抽象特征z是从正态分布采样生成而来,因此VAE的encoder部分是一个生成模型,然后再结合decoder来实现重构保证信息没有丢失。模型框架如下图所示:


损失函数:

VAE 的结构可以表示为图1:


图1 VAE 图2 VAE:Reparameterization Trick
但是,图1这种方式需要在前向传播时进行采样,而这种采样操作是无法进行反向传播 的。于是,论文作者提出一种“Reparameterization Trick”:将对![]() 采样的操作移到输入层进行,于是就有了图2的VAE 最终形式:
采样的操作移到输入层进行,于是就有了图2的VAE 最终形式:

下图表示了 VAE 整个过程。即首先通过 Encoder 得到x的隐变量分布参数;然后采样得到隐变量z。接下来按公式,应该是利用 Decoder 求得x的分布参数,而实际中一般就直接利用隐变量恢复x

下图展示了一个具有3个隐变量的 VAE 结构示意图,是对上面抽象描述的一个补充说明,不再赘述。
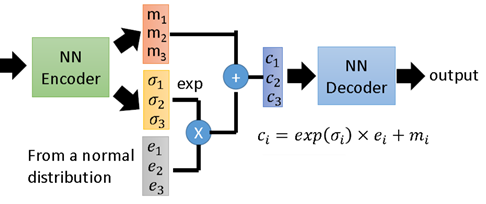
VAE 理论跟实际效果都非常惊艳,理论上涉及到的主要背景知识也比较多,包括:隐变量(Latent Variable Models)、变分推理(Variational Inference)、Reparameterization Trick 等。
VAE是一个里程碑式的研究成果,倒不是因为他是一个效果多么好的生成模型,主要是提供了一个结合概率图的思路来增强模型的鲁棒性。后续有很多基于VAE的扩展,包括infoVAE、betaVAE和factorVAE等。
1.6 Adversarial AutoEncoder
既然说到生成模型引入AutoEncoder,那必定也少不了将GAN的思路引入AutoEncoder[9],也取得了不错的效果。
对抗自编码器的网络结构主要分成两大部分:自编码部分(上半部分)、GAN判别网络(下半部分)。整个框架也就是GAN和AutoEncoder框架二者的结合。训练过程分成两个阶段:首先是样本重构阶段,通过梯度下降更新自编码器encoder部分、以及decoder的参数、使得重构损失函数最小化;然后是正则化约束阶段,交替更新判别网络参数和生成网络(encoder部分)参数以此提高encoder部分混淆判别网络的能力。
一旦训练完毕,自编码器的encoder部分便学习到了从样本数据x到抽象特征z的映射关系。

2. 背景知识点
2.1 KL散度
KL 散度:https://blog.csdn.net/matrix_space/article/details/80550561
在信息论中,D(p||q) 表示用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布

2.2 变分推断:用于近似计算后验分布P(Z|X)
参考:变分推断(Variational Inference)最新进展简述
变分推断(Variational Inference, VI)是贝叶斯近似推断方法中的一大类方法,将后验推断问题巧妙地转化为优化问题进行求解,相比另一大类方法马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo, MCMC),VI 具有更好的收敛性和可扩展性(scalability),更适合求解大规模近似推断问题。
当前机器学习两大热门研究方向:深度隐变量模型(Deep Latent Variable Model, DLVM)和深度神经网络模型的预测不确定性(Predictive Uncertainty)的计算求解都依赖于 VI,尤其是 Scalable VI。其中,DLVM 的一个典型代表是变分自编码器(Variational Autoencoder, VAE),是一种主流的深度生成模型,广泛应用于图像、语音甚至是文本的生成任务上;而预测不确定性的典型代表是贝叶斯神经网络(Bayesian Neural Network, BNN)。

问题定义:
原始目标是:需要根据已有数据推断需要的分布p;当p不容易表达,不能直接求解时,可以尝试用变分推断的方法, 即,寻找容易表达和求解的分布q,当q和p的差距很小的时候,q就可以作为p的近似分布,成为输出结果了。在这个过程中,我们的关键点转变了,从“求分布”的推断问题,变成了“缩小距离”的优化问题。
考虑一个一般性的问题, x 是 n 维的观测变量,z 是 m 维的隐变量,贝叶斯模型中需要计算后验分布,如下:
其中,p(z) 是先验分布,p(x|z) 是似然函数, p(x)=∫p(z)p(x|z),称为 evidence,通常 p(x) 是一个不可积的多重积分,导致后验分布 p(z|x) 无法获得解析解,同时因为 p(x) 只与确定的观测变量有关,在计算时可认为是一个常数。
VI 假设后验分布用一个变分分布 q(z;θ) 来近似,通过构造如下优化问题,KL散度:
求解使得两个分布距离最小的变分分布参数 θ,从而得到近似后验分布。因为真实后验分布是未知的,直接优化公式(2)是一件比较有挑战的事情,VI 巧妙地将其转化为优化 ELBO 的问题。


2.3 Reparameterization Trick:对某一分布的数据进行采样
Reparametrization tricks 重参数技巧
在 VAE 中,隐变量z一般取高斯分布,即z=N(μ,σ2)=P(Z|X),然后从这个分布P(Z|X)中采样,但采样的过程本身是不可逆的,就导致整个过程无法反向传播。我们已经知道 P(Z|X) 是服从正态分布的,也知道均值和方差,那么如何产生数据呢?解决方法就是Reparametrization tricks重参数技巧,从正态分布P(Z|X)中采样得到Z:
首先,从均值为0、标准差为1的高斯分布中采样,再放缩平移得到Z:
![]()
这样,从ϵ到z只涉及了线性操作(平移缩放),采样操作在NN计算图之外,这样相当于将采样过程提前,而ϵ对于NN来说只是一个常数。
2.4 GAN生成对抗网络
GAN生成对抗网络:https://easyai.tech/ai-definition/gan/















 2176
2176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











