







 自编码器是一种自监督学习的神经网络,常用于数据降维、去噪和预训练。文章介绍了最简单的自编码器、稀疏自编码器、栈式自编码器、去噪自编码器、卷积自编码器和序列到序列的自编码器,特别讨论了变分自编码器在生成模型中的应用。
自编码器是一种自监督学习的神经网络,常用于数据降维、去噪和预训练。文章介绍了最简单的自编码器、稀疏自编码器、栈式自编码器、去噪自编码器、卷积自编码器和序列到序列的自编码器,特别讨论了变分自编码器在生成模型中的应用。
十分建议先读keras文档
看完之后感觉好像普通的自编码器好像没啥用啊?
使用自编码器做数据压缩,性能并不怎么样……
做逐层预训练训练深度网络吧,现在好的初始化策略、Batch Normalization、残差连接啥的都很有效了……
那自编码器岂不是只有数据去噪、为进行可视化而降维这两个可应用的点了!配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
当然了,变分自编码器用于生成模型还是挺好的!
1.简介
自编码器是一类在半监督学习和非监督学习中使用的人工神经网络。
功能: 通过将输入信息作为学习目标,对输入信息进行表征学习。可应用于降维、降噪、异常值检测、数据生成、深度神经网络的预训练,包含卷积层的可被应用于计算机视觉问题,包括图像降噪、神经风格迁移等 。
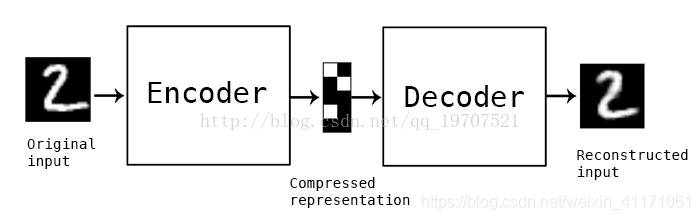
结构: 编码器(encoder)和解码器(decoder)。输入神经元和输出神经元的个数相等,输出是在设法重建输入,损失函数是重建损失。
特点: 是一种数据压缩算法。
- 数据相关的(data-specific),只能压缩类似于训练集的数据。
- 有损的,解压缩的输出与原来的输入相比是退化的。
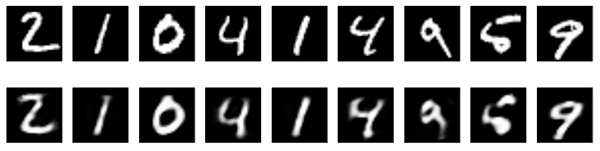
- 从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
按学习范式分类: 前两者是判别模型、后者是生成模型
- 收缩自编码器(Undercomplete autoencoder)
- 正则自编码器(Regularized autoencoder)
- 变分自编码器(Variational AutoEncoder, VAE)
按构筑类型分类:
- 前馈结构的神经网络
- 递归结构的神经网络
不完备自编码器(undercomplete autoencoder):内部表示(隐层的输出)的维度小于输入数据。
自编码器吸引了一大批研究和关注的主要原因之一是很长时间一段以来它被认为是解决无监督学习的可能方案,即大家觉得自编码器可以在没有标签的时候学习到数据的有用表达。再说一次,自编码器并不是一个真正的无监督学习的算法,而是一个自监督的算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,你需要想出一个靠谱的目标跟一个损失函数,问题来了,仅仅把目标设定为重构输入可能不是正确的选项。基本上,要求模型在像素级上精确重构输入不是机器学习的兴趣所在,学习到高级的抽象特征才是。事实上,当你的主要任务是分类、定位之类的任务时,那些对这类任务而言的最好的特征基本上都是重构输入时的最差的那种特征。
2.最简单的自编码器
一个全连接的编码器和解码器,学到的是PCA的近似。
3.稀疏自编码器
对隐层单元施加稀疏性/正则性约束的话,会得到更为紧凑的表达,只有一小部分神经元会被激活。所以模型过拟合的风险降低。
2.栈式自编码器Stacked Autoencoders
定义: 有多个隐层的自编码器,即把自编码器叠起来。
Q:增加隐层可以学到更复杂的编码,但千万不能使自编码器过于强大。
A:想象一下,一个Encoder过于强大,它仅仅是学习将输入映射为任意数,然后Decoder学习其逆映射。很明显,这一自编码器可以很好的重建数据,但它并没有在这一过程中学到有用的数据表示,也不能推广到新的实例。
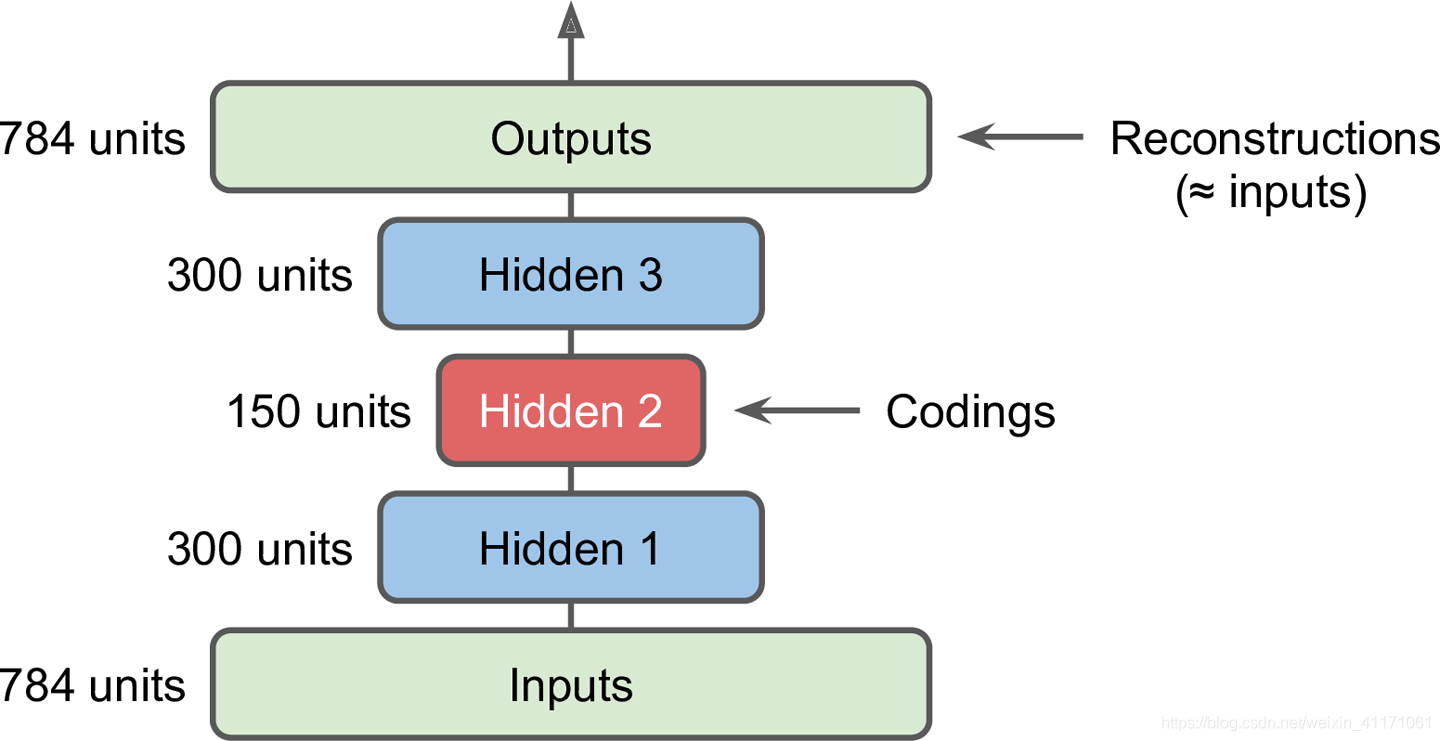
2.1.训练方式
2.1.1.捆绑权重,直接训练整个栈式自编码器
前提: 自编码器的层次是严格轴对称的(如上图)。
实现: 将Decoder层的权重捆绑到Encoder层。
好处: 使得模型参数减半,加快了训练速度,降低了过拟合风险。
假设自编码器一共有 N N N层(不算输入层), W L W_L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9861
9861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









