







标题:《DIET: Lightweight Language Understanding for Dialogue Systems》
中文:用于对话系统的轻量语言理解方法
时间:2020年5月
作者:RASA
简介:这个是RASA团队针对对话系统中NLU任务,设计的一种新框架,名叫Dual Intent and Entity Transformer (DIET,双重意图与实体Transformer ) 。成果是,DIET在不利用pre-trained embeddings.的情况下,达到了可比的性能,即large pre-trained models对NLU任务似乎没有什么优势。我们的方法比微调的BERT还好。
代码:https://github.com/RasaHQ/DIET-paper
学习资料:
- https://blog.rasa.com/introducing-dual-intent-and-entity-transformer-diet-state-of-the-art-performance-on-a-lightweight-architecture/
- https://www.youtube.com/watch?v=vWStcJDuOUk&list=PL75e0qA87dlG-za8eLI6t0_Pbxafk-cxb
- https://www.youtube.com/watch?v=KUGGuJ0aTL8&list=PL75e0qA87dlG-za8eLI6t0_Pbxafk-cxb&index=3
1. Introduction
本文,我们提出DIET——一个用于意图分类和实体识别(intent classification and entity recognition)的多任务框架。考虑两方面的embeddings,一是pre-trained word embeddings from language
models,二是sparse word and character level n-gram features。我们的特点是有能力将两种特征以plug-and-play方式结合起来。实验显示,尽管不使用pre-trained embeddings, 仅使用sparse
word and character level n-gram features, DIET依然能超越SOTA的NLU性能。而在增加pre-trained embeddings和sentence embedding的情况下,性能可以进一步提升。我们的最好性能优于微调BERT,且速度是后者6倍。
DIET代表Dual Intent and Entity Transformer,是一种多任务transformer 架构,可以同时执行意图分类和实体识别。它由多个组件组成,这使我们可以灵活地交换不同的组件。例如,我们可以尝试使用不同的word embeddings,例如BERT和GloVe。
许多预训练语言模型非常笨拙,因为它需要强大的计算能力,并且推理时间很长,因此尽管它们具有出色的性能,但它们并不是为对话式AI应用程序设计的。因此,大规模的预训练语言模型对于构建对话式AI应用程序的开发人员而言并不理想。
DIET之所以与众不同,是因为:
- 它是一种模块化体系结构,适合典型的软件开发工作流程;
- 在准确性和性能方面,能达到大规模的预训练语言模型的效果;
- 改进了现有技术,胜过目前的SOTA,并且训练速度提高了6倍。
2. Related Work
2.1 transfer learning
- fine-tuning a large pre-trained language model like BERT may not be optimal for every downstream task
- we study the impact of using sparse representations like word level one-hot encodings and character level n-grams along with dense representations transferred from large pre-trained language models.
2.2 Joint Intent Classification and Named Entity Recognition
以多任务学习的方式,联合实现意图分类与NER,这个思路已经有很多论文研究过。本文中,我们利用一个 similar transformer-based的多任务设置用于DIET。并通过消融实验与单任务设置下进行对比。
3. DIET architecture
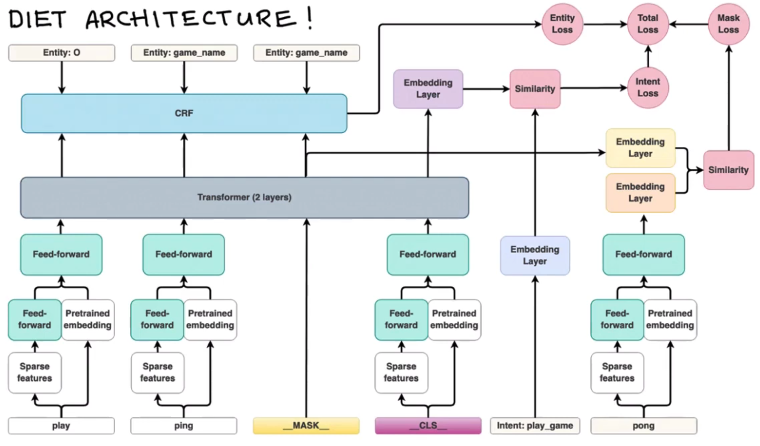
问题:
- Embedding Layer怎么实现的?
数据集要求:the input text、label(s) of intent(s) 、label(s) of entities.
FFNN Characteristics
关于架构中所有FFNN的两个特别说明:
- 首先,它们没有完全连接。从一开始,FFNN的dropout 率约为80%。这使得FFNN更轻巧。
- 其次,所有FFNN具有相同的权重。All the FFNN post sparse features share weights (W1) and all the FFNN post merging the output of the two paths share another set of weights (W2).
Featurization
在每一个句子结尾加一个__CLS__的special token。每个token都有它的嵌入,可以是sparse的,可以是dense的。通过线性层统一维度。
Transformer
自己实现一个小型的(2层)的Transformer来编码context。
NER
用Transformer输出向量,接一个CRF层进行NER。
Intent Classification
over all possible intent labels,将label嵌入与CLS对应的隐藏向量计算dot-product similarity。
- 训练阶段:最大化正标签的相似度,最小化负标签的相似度
- inference阶段:dot-product similarity在所有inten label上的rank
Masking
受masked language modelling task的启发,我们额外增加一个MASK损失函数来预测randomly masked input tokens。在序列中随机选择输入词符的 15%, 对于选定的词符,在70%的情况下我们将输入替换为特殊屏蔽词符 __MASK__ 对应的向量,在 10% 情况下我们用随机词符的向量替换输入,并在其余的 20% 情况下保留原始输入。
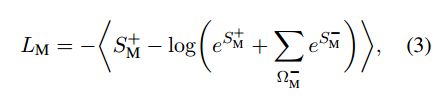
我们假设添加一个以重建MASK输入的训练目标,应该可以作为一个正则化器,帮助模型从文本中学习到更多一般的特征,而不仅要从分类中获得区分性。
Total loss
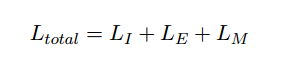
Total loss:
- Entity loss
- Intent loss
- Mask loss
注:这个结构可以配置,可以随时关闭上述总和中的任何一种损失。该体系结构的设计方式使我们可以打开或关闭多个组件,旨在处理意图和实体分类,但是如果我们只希望模型进行intent classification,则可以关闭Entity loss和Mask loss,而只专注于优化训练期间的Intent loss。
Batching
使用balanced batching策略来减轻类别不平衡,因为某些意图可能比其它意图更为频繁。 另外,还在整个训练期间增加批次大小,作为正则化的另一个来源。
4. 实验评估
在本节中,我们首先描述实验中使用的数据集,然后描述实验设置,然后进行消融研究以了解体系结构每个组件的有效性。
4.1 数据集
我们使用三个数据集进行评估:NLU-Benchmark、ATIS 和 SNIPS。 我们的实验重点是 NLU-Benchmark 数据集,因为它是这三个中最具挑战性的。 ATIS 和 SNIPS 测试集精度的最先进水平已经接近 100%,请参见表5。
NLU-Benchmark 数据集: NLU-Benchmark 数据集(Liu 等人,2019b),带有场景、动作和实体的标注。 例如,“schedule a call with Lisa on Monday morning” 标注为场景 calendar、动作 set_event、实体 [event_name: a call with Lisa] 和 [date: Monday morning]。 将场景和动作标签进行连接得到意图标签(例如 calendar_set_event)。 该数据集有 25,716 个语句,涵盖多个家庭助理任务,例如播放音乐或日历查询、聊天、以及向机器人发出的命令。 我们将数据分为 10 fold。 每一份都有自己的训练集和测试集,分别有 9960 和 1076 个个语句。3 总共存在 64 个意图和 54 种实体类型。
ATIS: ATIS(Hemphill 等人,1990)是 NLU 领域中经过充分研究的数据集。 它由预订机票的人的录音经过标注转录。 我们使用与 Chen 等人 (2019)一样分划分,最初由 Goo 等人 (2018)提出。 训练、开发和测试集分别包含 4,478、500 和 893 个语句。 训练数据集包含 21 个意图和 79 个实体。
SNIPS: 此数据集是从 Snips 个人语音助手收集的(Coucke 等人,2018)。 它包含 13,784 个训练和 700 个测试样本。 为了公平比较,我们使用与 Chen 等人 (2019)和 Goo 等人 (2018)一样的数据划分,数据集链接。 训练集中分 700 个样本用作开发集。 数据可以在线访问 4。 SNIPS 数据集包含 7 个意图和 39 个实体。
4.2 实验设置
我们的模型用 Tensorflow 实现:
- 使用 NLU-Benchmark 数据集的第一个fold来选择超参数。 为此,我们从训练集中随机抽取 250 个语句作为验证集。
- 训练 200 多个epochs的模型(在一台具有 4 个 CPU,15 GB 内存和一台 NVIDIA Tesla K80 的计算机上)。
- 使用 Adam(Kingma 和 Ba,2014)进行优化,初始学习率为 0.001。
- batch size大小从 64 增加到 128(Smith 等人,2017)。
在 NLU-Benchmark 数据集的第一个小份上训练我们的模型大约需要一个小时。 在推断的时候,我们需要大约 80 毫秒来处理一条语句。
4.3 在 NLU-Benchmark 数据集上的实验
为了获得该模型在该数据集上的整体性能,我们采用 Vanzo 等人 (2019)的方法:分别训练 10 个模型,每个小份一次,将平均值作为最终得分。
Micro-averaged precision、召回率和 F1 得分用作指标
意图标签的 True positives、false positives 和 false negatives 的计算方式与其它任何多类分类任务一样。 如果预测范围和正确范围之间重叠,并且其标签匹配,则该实体被视为 true positive。
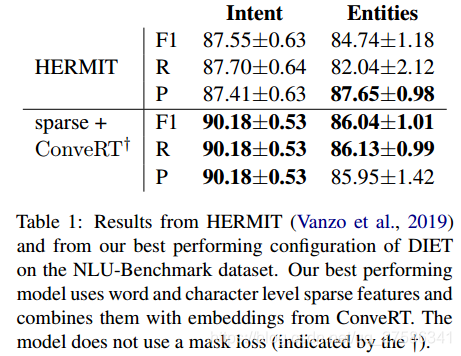
表1显示我们在 NLU-Benchmark 数据集上表现最好的模型的结果。 我们性能最好的模型使用稀疏特征,即词符级别的 one-hot 编码和字符 n-gram 的 multi-hot 编码(n ≤ 5)。 这些稀疏特征与 ConveRT 的密集嵌入相结合(Henderson 等人,2019b)。
性能最好的模型没有使用MASK损失
我们在意图方面的表现优于 HERMIT,绝对值超过 2%。 我们的实体 F1 微观平均得分(86.04%)也高于 HERMIT(84.74%)。 HERMIT 报告的实体精度值相似,但是,我们的召回率要高得多(86.13% 相比 82.04%)。
4.4 NLU-Benchmark 数据集上的消融研究
我们使用 NLU-Benchmark 数据集来评估模型体系结构的不同组成部分,因为它涵盖多个领域并且在三个数据集中拥有最多的意图和实体。
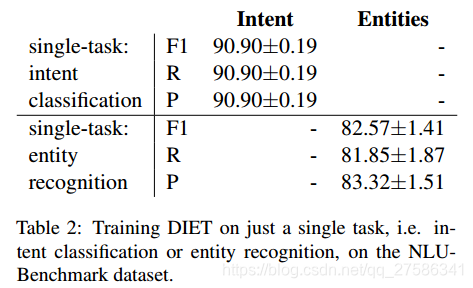
Joint training的重要性:为了评估意图分类和命名实体识别这两个任务是否受益于joint优化,我们针对每个任务分别训练了模型。 表2列出使用 DIET 仅训练单个任务的结果。 结果表明,与实体识别一起训练时,意图分类的性能略有下降(90.90% vs 90.18%)。 应该注意的是,意图分类单任务训练的最佳性能配置对应于使用没有 transformer 层5 的 ConveRT 嵌入。 但是,当单独训练实体时,实体的 micro-averaged F1 分数从 86.04 %下降到 82.57%。 检查 NLU-Benchmark 数据集,这可能是由于特定意图与特定实体的存在之间的强相关性。 例如,几乎所有属于 play_game 意图的语句都有一个名为 game_name 的实体。 同样,实体 game_name 仅与意图 play_game 一起出现。 我们认为,这一结果进一步表明拥有像 DIET 这样的模块化和可配置架构的重要性,以便处理这两项任务之间的性能折衷。
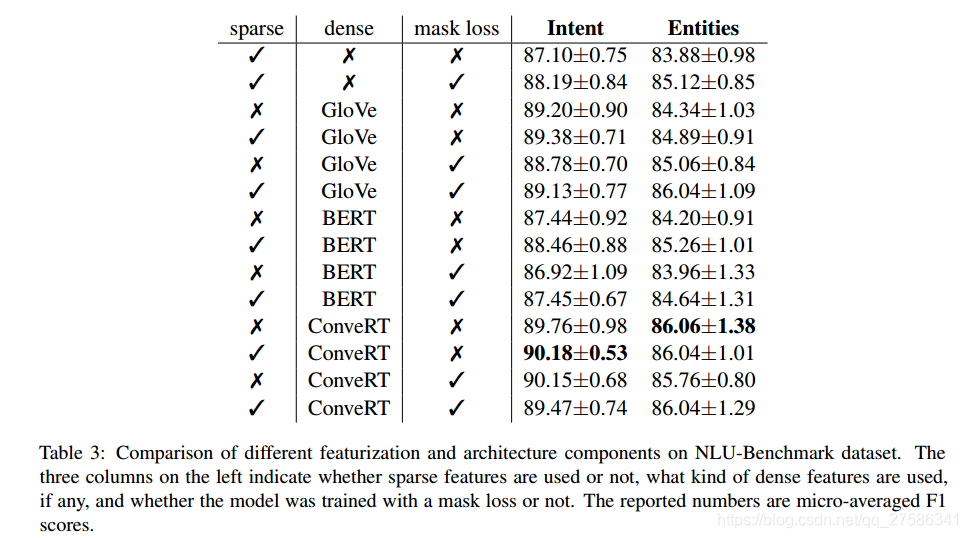
不同特征组件和MASK的重要性:如第3节所述,不同预训练语言模型的嵌入都可以用作dense特征。 我们训练多种变体来研究每种变体的有效性:仅sparse特征,即word级别的 one-hot 编码和character n-gram 的 multi-hot 编码(n ≤ 5),以及与 ConveRT、BERT 或 GloVe一起使用的组合。 此外,我们在有和没有MASK损失的情况下训练每种组合。 表3中显示的结果显示意图分类和实体识别的 F1 分数,并表明多种观察结果:
- 当使用sparse特征和mask损失,而没有任何预训练的embeddings时,DIET 的性能具有竞争力。 在目标和实体上增加mask损失都会使性能提高绝对值约 1%。
- 具有 GloVe 嵌入的 DIET 也具有同等的竞争力,并且在与sparse特征和mask损失结合使用时,在意图和实体上都将得到进一步增强。
- 有趣的是,使用上下文 BERT 嵌入作为dense特征的效果要比 GloVe 差。 我们假设这是因为 BERT 主要是在各种文本上预训练的,因此在转移到对话任务之前需要微调。 由于 ConveRT 专门针对会话数据进行微调,因此使用 ConveRT 嵌入的 DIET 的性能支持了这种假设。
- sparse特征 和 ConveRT 嵌入的结合在意图分类上获得了最佳的 F1 得分,并且在意图分类和实体识别方面都比现有最好结果高出 3% 左右。
- 与 BERT 和 ConveRT 一起用作dense特征时,增加mask损失似乎会稍微影响性能。
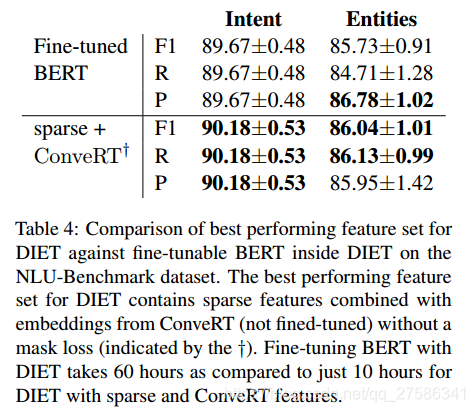
与微调 BERT 比较:我们评估将 BERT 应用到 DIET 的特征流水线中并对整个模型进行微调的有效性。 表4显示使用冻结 ConveRT 嵌入的 DIET 作为dense特征和单词、字符级稀疏特征在实体识别上表现优于微调的 BERT,而在意图分类方面表现持平。 此结果尤为重要,因为在所有 10 个 NLU-Benchmark 数据集上微调的 DIET 中的 BERT 需要 60 个小时,而使用 ConveRT 嵌入和稀疏特征的 DIET 则需要 10 个小时。
4.5 ATIS 和 SNIPS 上的实验
为了将我们的结果与 Chen 等人 (2019)比较,我们使用与以下相同的评估方法 Chen 等人 (2019)和 Goo 等人 (2018)。 他们报告意图分类的准确性和实体识别的 micro-averaged F1 分数。 同样,可以像在其它任何多类分类任务中一样获得意图标签的 true positives、false positives 和 false negatives。 但是,只有当预测范围与正确范围完全匹配并且其标签匹配正确时,实体才算为 true positive,定义比 Vanzo 等人 (2019)更严格。 所有实验在 ATIS 和 SNIPS 上均进行 5 次。 我们将这些运行结果的平均值作为最终数字。
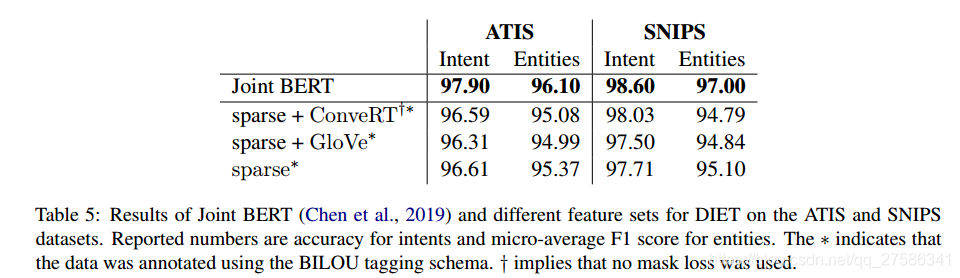
为了解 DIET 超参数的可移植性,我们采用在 NLU-Benchmark 数据集上性能最佳的 DIET 模型配置,并在 ATIS 和 SNIPS 上对其进行评估。 表5中列出 ATIS 和 SNIPS 数据集上的意图分类准确性和命名实体识别 F1 得分。
由于采用了更严格的评估方法,因此我们使用 BILOU 标记模式对数据进行标记(Ramshaw 和 Marcus,1995)。 表5中的 ∗ 指示使用 BILOU 标记模式。
值得注意的是,DIET 仅使用稀疏特征而没有任何预训练的嵌入,即使这样其性能仅比 Joint BERT 模型低 1-2%之内。 利用 NLU-Benchmark 数据集上性能最佳模型的超参数,DIET 在 ATIS 和 SNIPS 上均获得与 Joint BERT 竞争的结果。
参考:https://natural-language-understanding.fandom.com/wiki/Named_entity_recognition#BILOU
Similar but more detailed than BIO, BILOU encode the Beginning, the Inside and Last token of multi-token chunks while differentiate them from Unit-length chunks. The same sentence is annotated differently in BILOU:
B - 'beginning' I - 'inside' L - 'last' O - 'outside' U - 'unit'如:
Minjun U-Person is O from O South B-Location Korea L-Location . O

















 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









