






 该博客介绍了一篇关于实体关系联合抽取的研究工作,指出现有方法存在的问题,如特征混淆和结构信息丢失。文章提出使用不同的序列表示和表格表示来分别处理NER和RE任务,并通过神经网络结构保持表格的二维结构,利用BERT注意力权重学习元素表示。模型包括TextEmbedding、TableEncoder和SequenceEncoder等组件,通过实验验证了模型的有效性。
该博客介绍了一篇关于实体关系联合抽取的研究工作,指出现有方法存在的问题,如特征混淆和结构信息丢失。文章提出使用不同的序列表示和表格表示来分别处理NER和RE任务,并通过神经网络结构保持表格的二维结构,利用BERT注意力权重学习元素表示。模型包括TextEmbedding、TableEncoder和SequenceEncoder等组件,通过实验验证了模型的有效性。
点击上方,选择星标或置顶,每天给你送干货!
来自:深度学习的知识小屋
Paper: Two are Better Than One: Joint Entity and Relation Extraction with Table-Sequence Encoders
Link:https://www.aclweb.org/anthology/2020.emnlp-main.133.pdf
Code: https://github.com/LorrinWWW/two-are-better-than-one
这是一篇关于实体关系联合抽取的工作。关于现有的联合抽取工作,作者提出了两点不足之处:
Feature Confusiong: 用于同样的特征表示进行NER和RE(关系分类)两项任务,可能会对模型的学习造成误解;
现有的基于Table-Filling方法去完成联合抽取的工作,会将表结构转化成一个序列结构,这样导致丢失了重要的结构信息。
因此本文的工作有以下特点:
针对NER和RE,分别学习出不同的序列表示(sequence representations)和表格表示(table representations); 这两种表示能分别捕获任务相关的信息,同时作者还涉及了一种机制使他们彼此交互;
保持表格的结构,通过神经网络结构来捕捉二维表格中的结构信息;同时,引入BERT中的attention权重,进行表格中元素表示的学习。
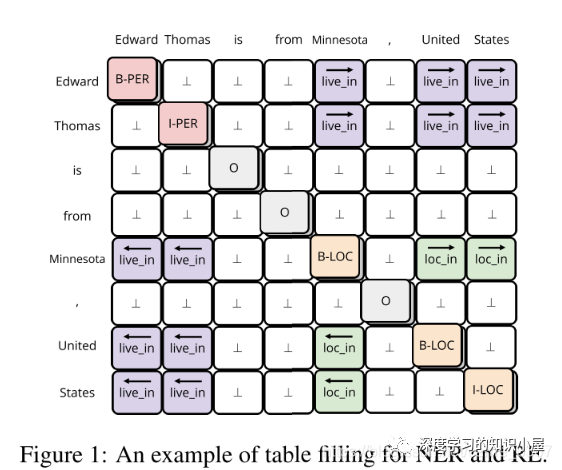
模型的核心部分包括以下模块:
Text Embedding: 对于一个输入的包含n个words的句子,其词向量、字符向量和BERT词向量的共同构成了每个word的表示。
Table Encoder: 目标在于学出 N×N 表格下的向量表示,表格第i行第j列的向量表示,与句子中的第i个和第j个词相对应,如Figure1所示。文中使用基于GRU结构的MD-RNN(多维RNN)作为Text Encoder,在更新表格中当前cell的信息时,通过MDRNN融合其上下左右四个方向上的信息,从而利用了表格的结构特点;同时引入当前cell所对应的两个词在Sequence Encoder下的表示,使得Table Encoder和Sequence Encoder之间发生信息的交流;
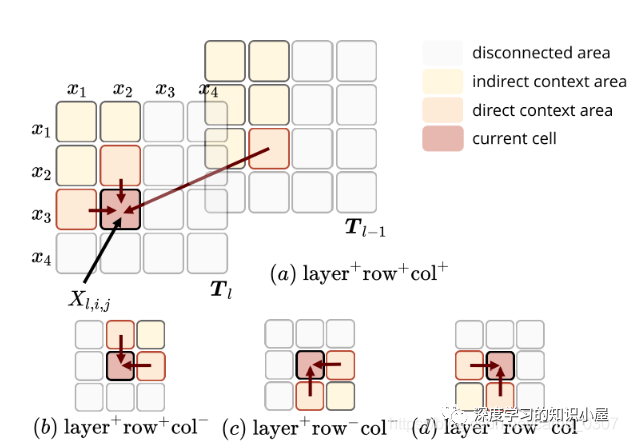
Sequence Encoder: Sequence Encoder的结构与Transformer类似,不同之处在于将Transformer中的scaled dot-product attention 替换为文中提出的 table-guided attention。具体地,将Transformer中计算Q,K之间分值的过程直接替换为对应两个word在table中对应的向量:
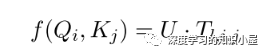
由于 T_ij 融合了四个方向上的信息,能够更加充分的捕捉上下文信息以及词与词之间的关系,同时也使Table Encoder和Sequence Encoder之间产生了双向的信息交流。
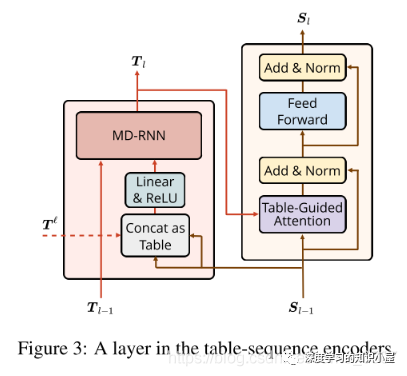
Exploit Pre-trained Attention Weights: Text Embeddings部分有用到BERT,因此将BERT中各个层上多头attention每个头上的atention权重堆叠起来,得到张量T l ∈ R N × N × ( L l × A l ) T^{l} \in \mathbb{R}^{N \times N \times (L^l \times A^l)} T和 Text Embedding中每个词的表示,来构成Table的初始输入:
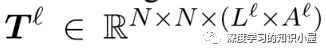
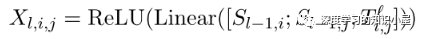
作者通过在不同数据集上的实验证明了模型的有效性,并通过消融实验进行了相关的分析。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
整理不易,还望给个在看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









