






笔记 | Windy
整理 | NewBeeNLP公众号
微软亚洲研究院副院长周明老师报告:From Language Intelligence to Code Intelligence Based on Pre-trained Models
感谢周明老师的分享以及Windy同学的笔记,完整报告内容文末阅读原文一键直达。
TL;DR
代码智能(Code Intelligence)旨在使计算机具备理解和生成代码的能力,并利用编程语言知识和上下文进行推理,支持代码检索、补全、翻译、纠错、问答等场景。
以深度学习为代表的人工智能算法,近年来在视觉、语音和自然语言理解任务上取得了飞跃式的突破。最近基于Transformer的预训练模型大大推动了自然语言处理和多模态的技术进步。而基于最新的自然语言技术与编程语言知识相融合的代码智能的研究也受到越来越多的关注。
本报告将介绍微软亚洲研究院自然语言计算组在该研究领域的一系列最新进展,包括针对代码智能的预训练模型(CodeBERT/CodeGPT)、基准数据集(CodeXGLUE)和融合了编程语言句法和语义信息的新的评价指标(CodeBLEU)。最后,本报告研讨该领域目前存在的主要问题并探索未来的发展方向。
报告笔记如下。
一、语言智能和预训练
这几年NLP领域里程碑式的工作
word embedding (2013)
sentence embedding
encoder-decoder with attention (2014)
Transformer(2016)考虑到RNN并行能力弱(self-attention),只有一个特征抽取 (multi-head)
Pre-trained Model (self-supervised地把大规模语料中上下文相关的语义表示学出来,再fine-tuning)
为什么要做预训练模型?
显式表征了句法和语义知识
体现了迁移学习的特点,帮助低资源情况
几乎支持所有NLP任务,而且都取得了不错的效果
可扩展性比较好,降低了NLP门槛
Self-supervised Learning方法
利用数据自然特点,不需要人工标注
autoregressive(AR) LM
auto-encoding (AE)
总结预训练模型的相关工作(见下图)
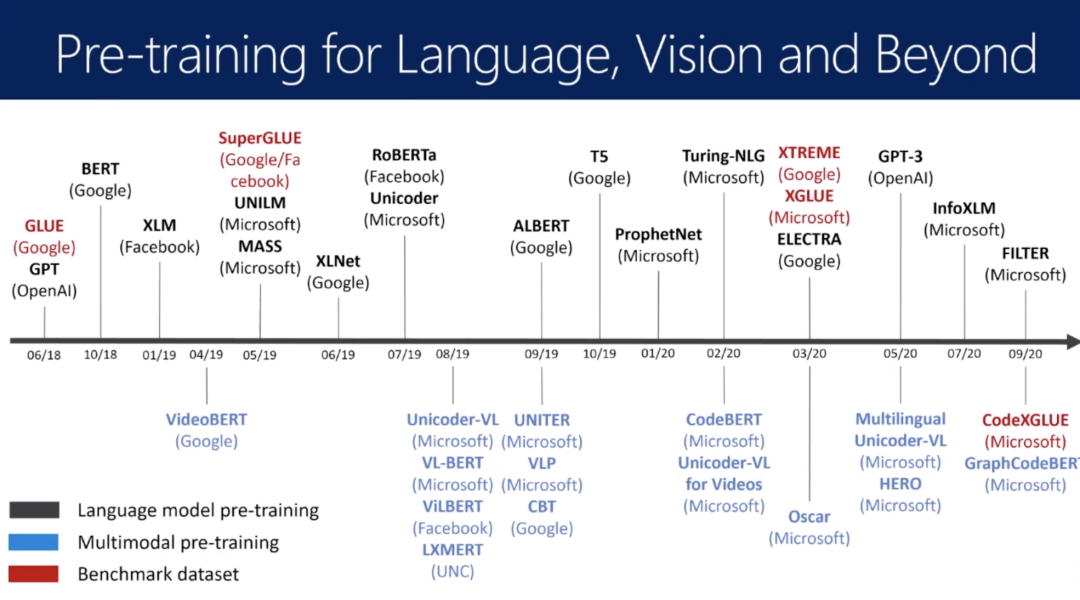
预训练模型的发展趋势
模型越来越大(消耗资源,且不利于非企业研究)
预训练方法和模型不断创新
从单语到多语,到多模态,到程序语言
模型压缩,知识蒸馏
微软工作总览
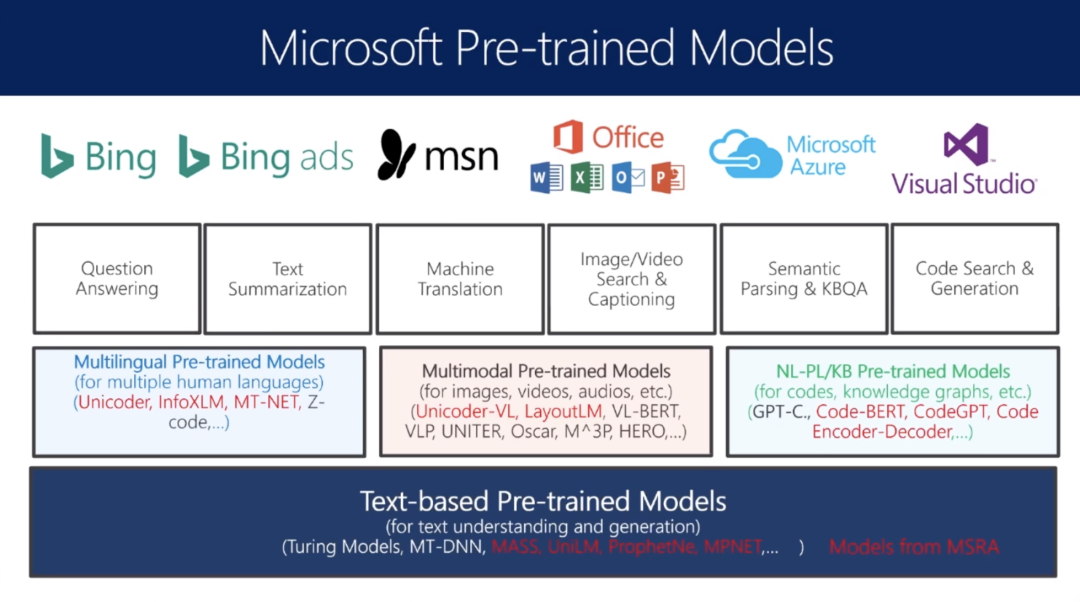
微软预训练模型介绍
「UniLM」(Dong et al.,2019)
GPT是单向,适合做生成;
Bert是双向,适合做理解。
能否合成?用了一个统一架构三个部分做多任务学习。
「Unicoder for Understanding」 (Huang et al.,2019)
多语言;
增加contrastive learning任务判断是否构成互译。
「Unicoder for Generation」 (Liang et al.,2020)
由于2不能做生成而提出;
对输入加噪,试图在解码时去噪。
「Unicoder一VL for Images」 (Li et al, 2020)
到图像上的预训练,考虑图片+注释。
「Unicoder一VL for Videos」 (Luo et al., 2020)
同理,做视频的预训练,多任务训练得到,融入了文本信息。
「LayoutLM: Text+Layout Pre 一training」
文档的预训练(考虑了排版的信息,OCR结果的位置信息)
应用
QA
Question Generation
Multilingual QA
Multilingual News Headline Generation
Image Search
Document Understanding
Video Chaptering
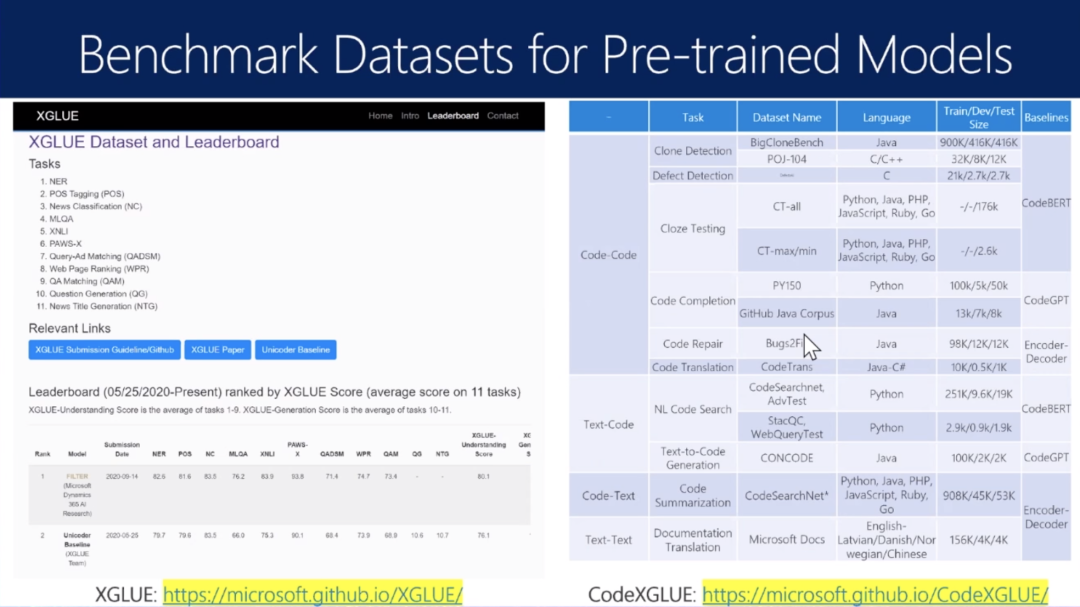
XCLUE基准
二、代码智能 (基于预训练模型)
能不能把自然语言的方法应用到代码领域,提高效率?
已有工作
excel检测已经完成的部分
从自然语言的query通过parsing到SQL
GPT-3代码生成(从自然语言描述到代码块)
现成资源
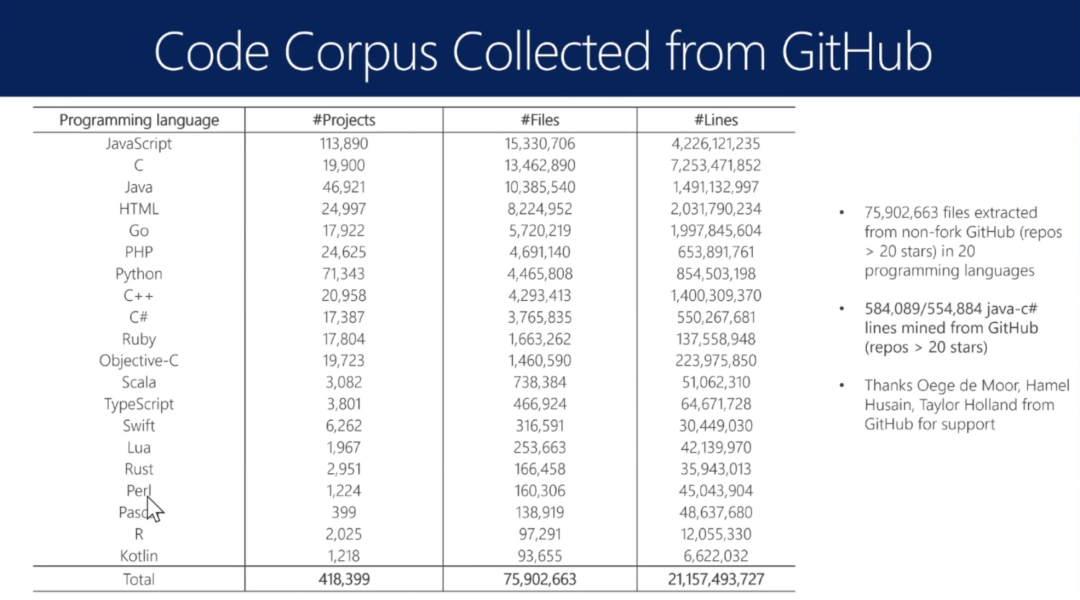
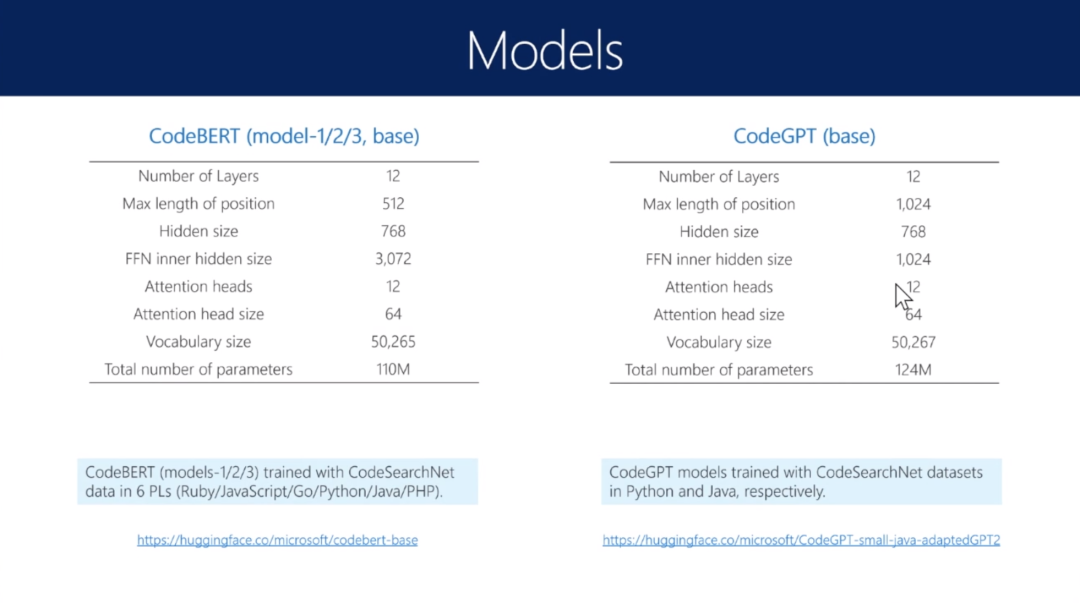
模型
「CodeBERT」 (Model-1)
baseline,在数据基础上直接训练一个Bert。
「CodeBERT (Model-2): Pre-Train with Code + Text」
考虑到代码有自己的特点(注释)。
「CodeBERT (Model-3): Pre-Train with Code + Text + Structure」
除了注释还考虑到代码有结构(AST),变量有依赖或顺序关系。
「CodeGPT」
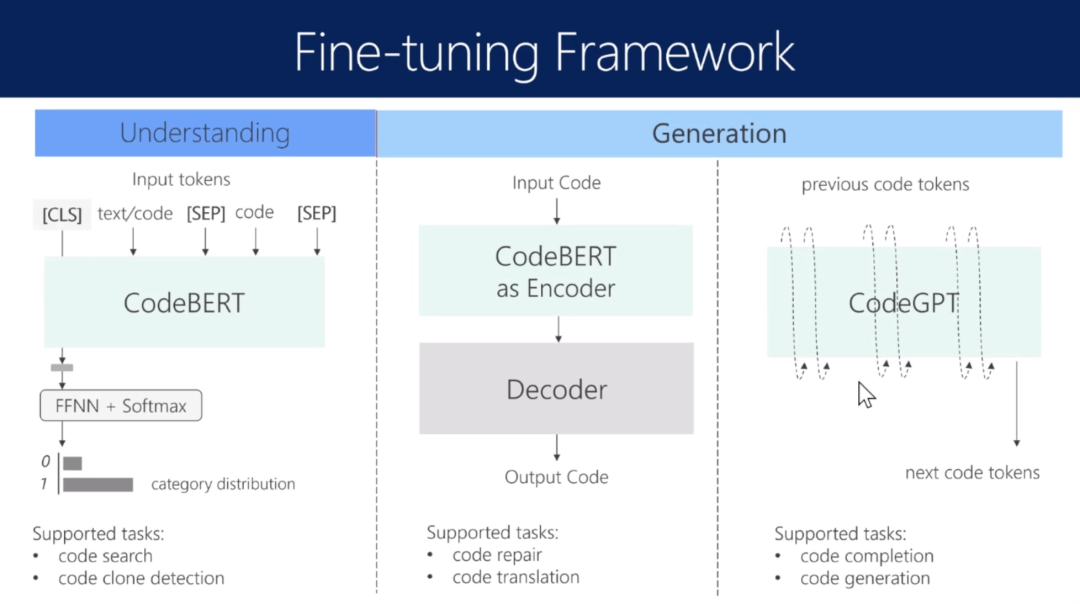
下游任务
找到和输入自然语言串符合的code
写了一段代码,补足下一个词
找到bug并且修改
不同语言的代码之间的翻译(低资源问题,如何应用单语数据)
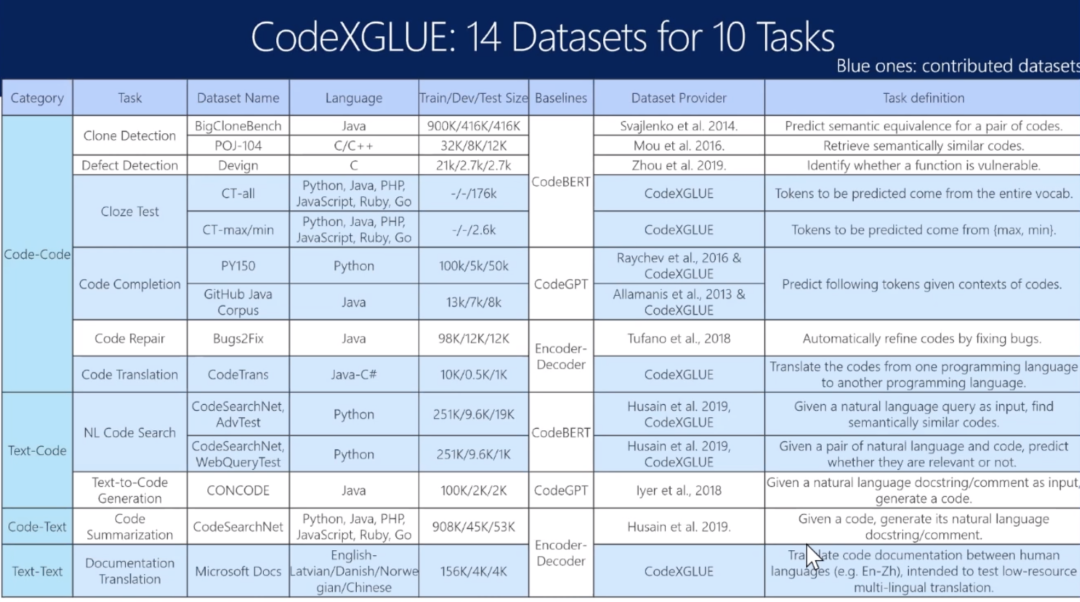
CodeXGLUE数据集和任务汇总
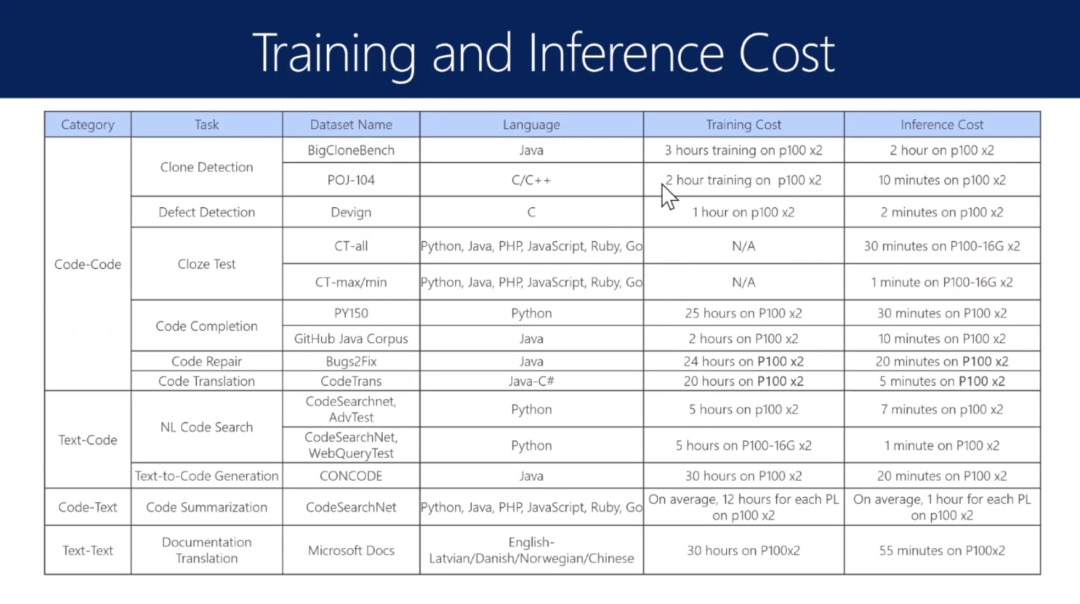
成本估算
评测
基于3点:不同词的权重不同,AST的匹配,语义一致(看变量是否一致)
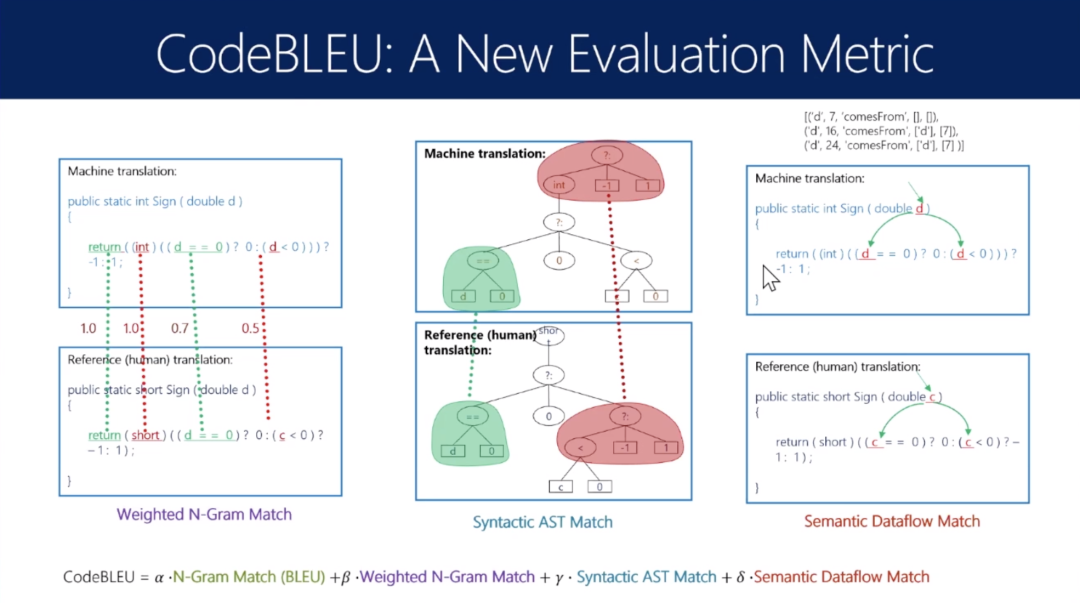
评测本身是否好?(看哪种评价和人工评价最吻合)
总结

未来的工作方向

提问
问:从高校的角度如何在预训练方面工作?
答:
不要军备竞赛或者拼蛮力,应该做方法论,例如如何融入知识;
小模型能否做很好的工作;模型压缩,知识萃取;
fine-tune也有很多工作,什么样的方法微调会比较好;
扩展应用领域;
跨学科工作。
问:代码自动生成的规则是硬约束还是自动学习,如何保证正确性?
答:NLP工作者只知道串对串,对几个词的不同比较宽容,但编程只要错一点就没法运行。如何评测是需要考虑的,目前没有很好的办法数字化衡量,例如可执行性,但逻辑性效率等都可以做一些模拟工作,希望大家未来想办法自动评价
问:想关注跨模态工作前景?
答:以前从其他领域借鉴了很多方法,挪到了NLP;后来NLP的transformer等等,有更好的预训练模型,可以反攻其他领域了。这件事是NLP工作者应该好好考虑的,一切序列化的任务都可以看作自然语言任务,提高相关领域的技术发展,反哺其他领域。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
 。
。投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
整理不易,还望给个在看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









