






点击下面卡片,关注我呀,每天给你送来AI技术干货!
知乎:TniL
链接:
https://www.zhihu.com/question/455384157/answer/1852594882
编辑:深度学习自然语言处理公众号
已获作者授权
抛砖引玉,欢迎指正。讲一个预训练模型使用上的范式更迭:finetune 到 prompt-based tuning/task-reformulation。
从BERT开始,预训练模型的使用范式长期是pretrain->finetune的范式,即先在大量无标注语料上预训练一个模型,然后将模型(可选地,增加一定模块后)放到特定下游任务上的标注数据finetune。后来实验还表明在下游任务的数据上继续预训练,可以进一步压榨PTM的性能,所以有pretrain-> further pretrain -> finetune的范式[1][2]。这类方法思路就是通过调整PTM参数,来适应任务/数据特性,不过背后的机理还有待debate。
2020年的GPT3[3]放出的时候大家对它的反应无一例外都是都是惊奇于1700亿的参数量。不过这篇文章引出了一个很有意思的现象,正如它的标题:Language models are few-shot learners,在这样一个大规模PTM上,只要给出任务描述(和可选的少量样例)作为prompt,PTM无需更新参数也可以在下游任务达到不错的性能。
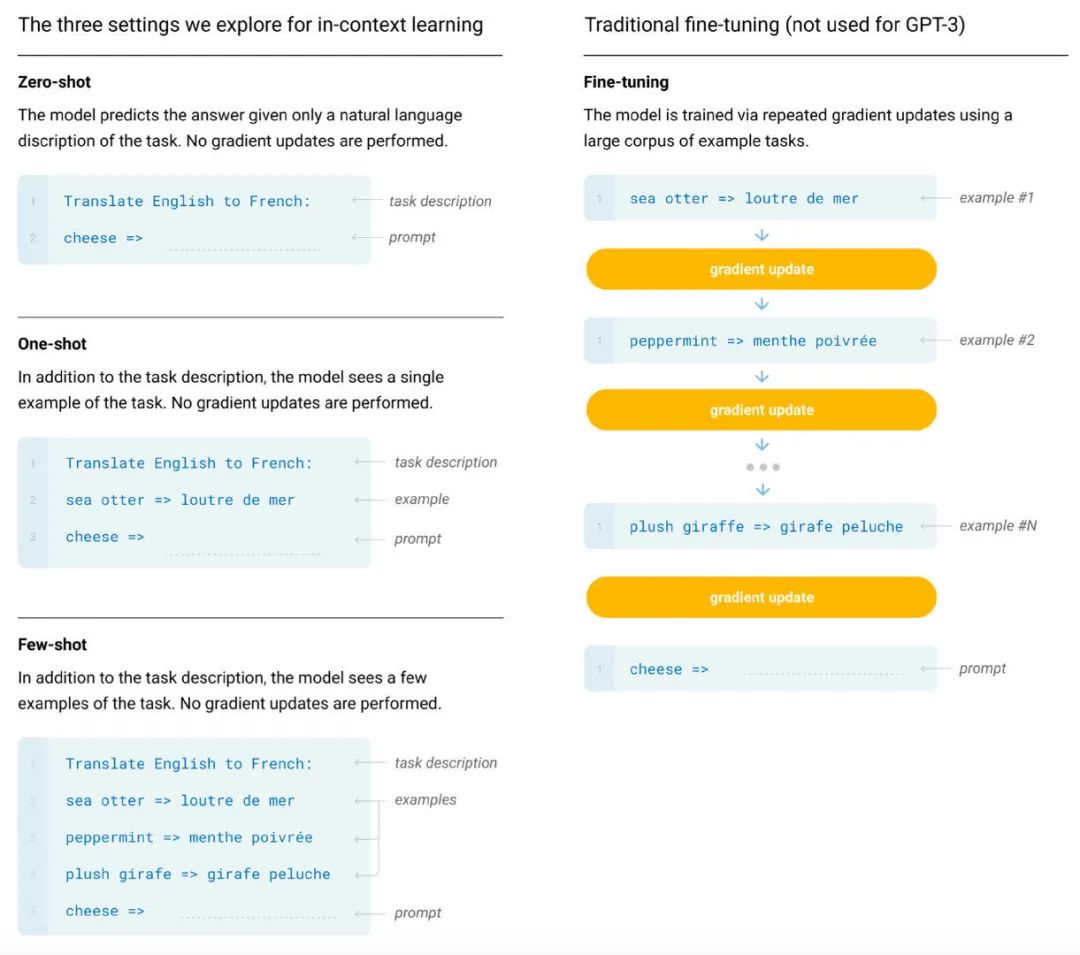
GPT3与传统finetune范式的对比
GPT3的few-shot设定虽然结果远没有达到SOTA,但是结果是非常吸引人的,因此引出了很多工作,大体思路是用自动构建的prompt代替人工设计的prompt,这类基于prompt的方法有一点比较大的优势:由于固定了PTM的部分,可以有多个任务共享同一个backbone,而任务特定的部分只有输入端prompt的部分,一般不会包含太多参数(类似adapters[4]的概念),这样就可以构造一个天然的多任务网络。
这里罗列几篇这类方法的工作:
AutoPrompt[5]提出了一种离散的prompt搜索方法,其中prompt中有一系列词表中的触发词,这些词被初始化为[MASK],然后通过基于梯度的top-k搜索迭代式地更新
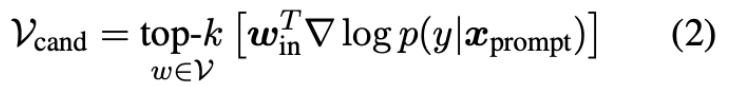
AutoPrompt中选取候选更新词的方法
Prefix-tuning[6]在生成类任务上提出,将prompt作为一种任务特定、连续、可学习的prefix加到embedding和中间层激活的开头(这里还将prefix重参数化,否则结果不好),固定PTM部分参数不变。类似地,WARP[7] 令输入的prompt部分、以及label candidates可学习,这个方法只加入几千个参数即可在实验中接近finetune的结果。
P-tuning[8]使用LSTM输出的的(连续空间中的)伪token(加上一些任务相关的anchor token),从而使用GPT(生成)模型在理解任务上取得了超过BERT的结果(不过这篇工作的PTM参数也是在tuninng过程中更新的,所以没有参数上的优势,不过证明了适当的建模可以让GPT在理解任务上取得很好的效果)。
当然这一系列工作不是孤立出现的,比较相关的还有LAMA[9]、PET[10],都属于task reformulation,个人感觉这类将各种PTM tuning中的传统建模方法替代为基于模版填空/Prompting的方法是一种比较明显的趋势。
[1] How to Fine-Tune BERT for Text Classification?
[2] Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
[3] Language models are few-shot learners
[4] Parameter-Efficient Transfer Learning for NLP
[5] AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
[6] Prefix-Tuning: Optimizing Continuous Prompts for Generation
[7] WARP: Word-level Adversarial ReProgramming
[8] GPT Understands, Too
[9] Language Models as Knowledge Bases?
[10] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









